wenge-research/yayi2_pretrain_data
收藏Hugging Face2023-12-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/wenge-research/yayi2_pretrain_data
下载链接
链接失效反馈官方服务:
资源简介:
本数据集源自雅意训练语料,精选了约100B数据,数据大小约为500GB,旨在推动中文预训练大模型开源社区的发展。数据集在预训练阶段使用了互联网数据、通用精选数据和领域数据,涵盖了报纸类、文献类、代码类、书籍类、百科类等多种数据类型。数据清洗过程包括标准化、启发式清洗、多级去重和毒性过滤,最终从240TB原始数据中筛选出10.6TB高质量数据。数据集遵循Apache-2.0协议,并提供了社区和商用许可协议。
本数据集源自雅意训练语料,精选了约100B数据,数据大小约为500GB,旨在推动中文预训练大模型开源社区的发展。数据集在预训练阶段使用了互联网数据、通用精选数据和领域数据,涵盖了报纸类、文献类、代码类、书籍类、百科类等多种数据类型。数据清洗过程包括标准化、启发式清洗、多级去重和毒性过滤,最终从240TB原始数据中筛选出10.6TB高质量数据。数据集遵循Apache-2.0协议,并提供了社区和商用许可协议。
提供机构:
wenge-research
原始信息汇总
介绍
本数据集源自雅意训练语料,精选了约100B数据,数据大小约为500GB。通过开源预训练数据,旨在推动中文预训练大模型开源社区的发展,并与合作伙伴共同构建雅意大模型生态。
组成
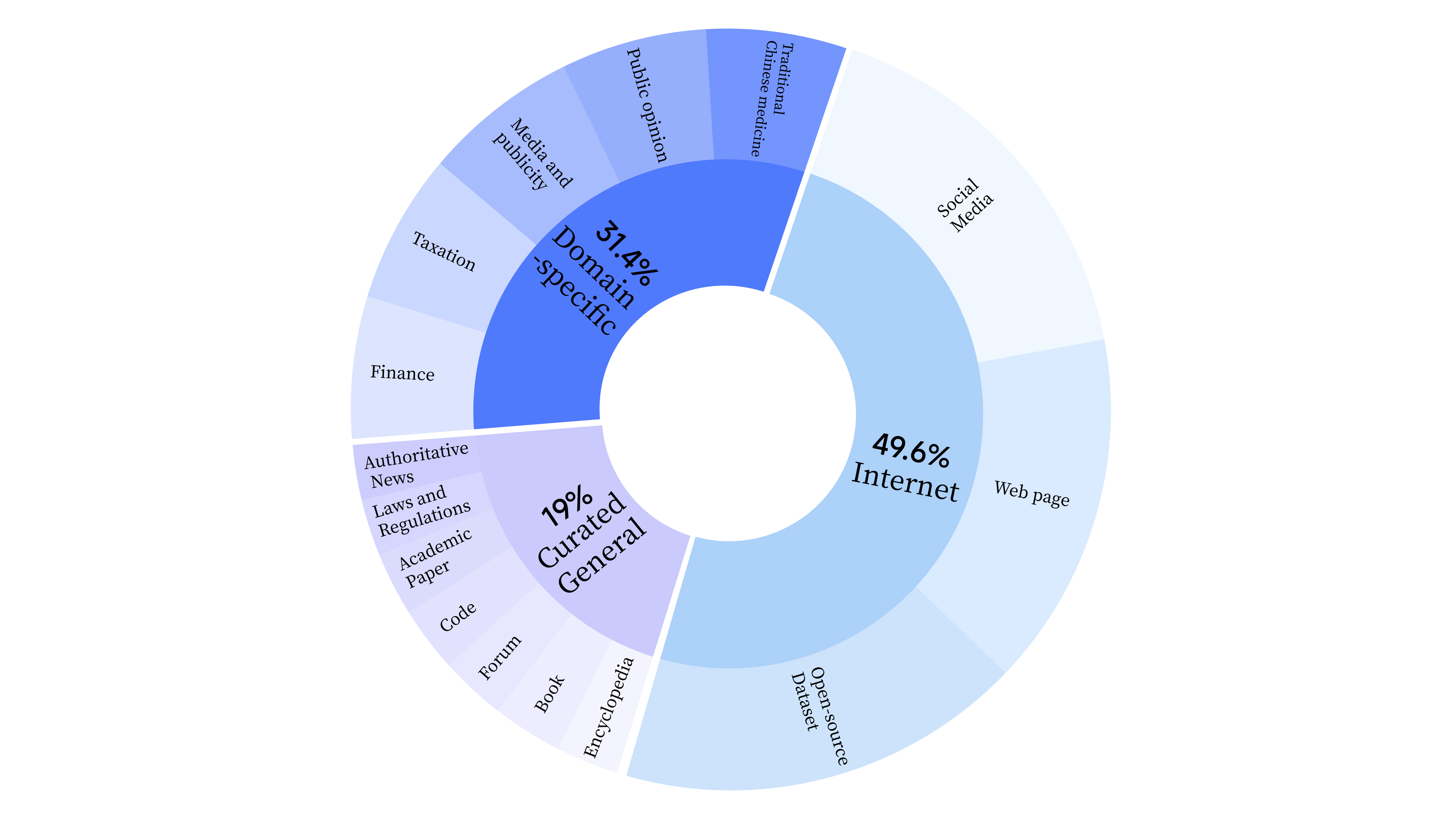
在预训练阶段,数据集不仅包含互联网数据,还添加了通用精选数据和领域数据,以增强模型的专业技能。通用精选数据涵盖报纸类数据、文献类数据、APP类数据、代码类数据、书籍类数据、百科类数据等。数据分布情况如下:
数据清洗
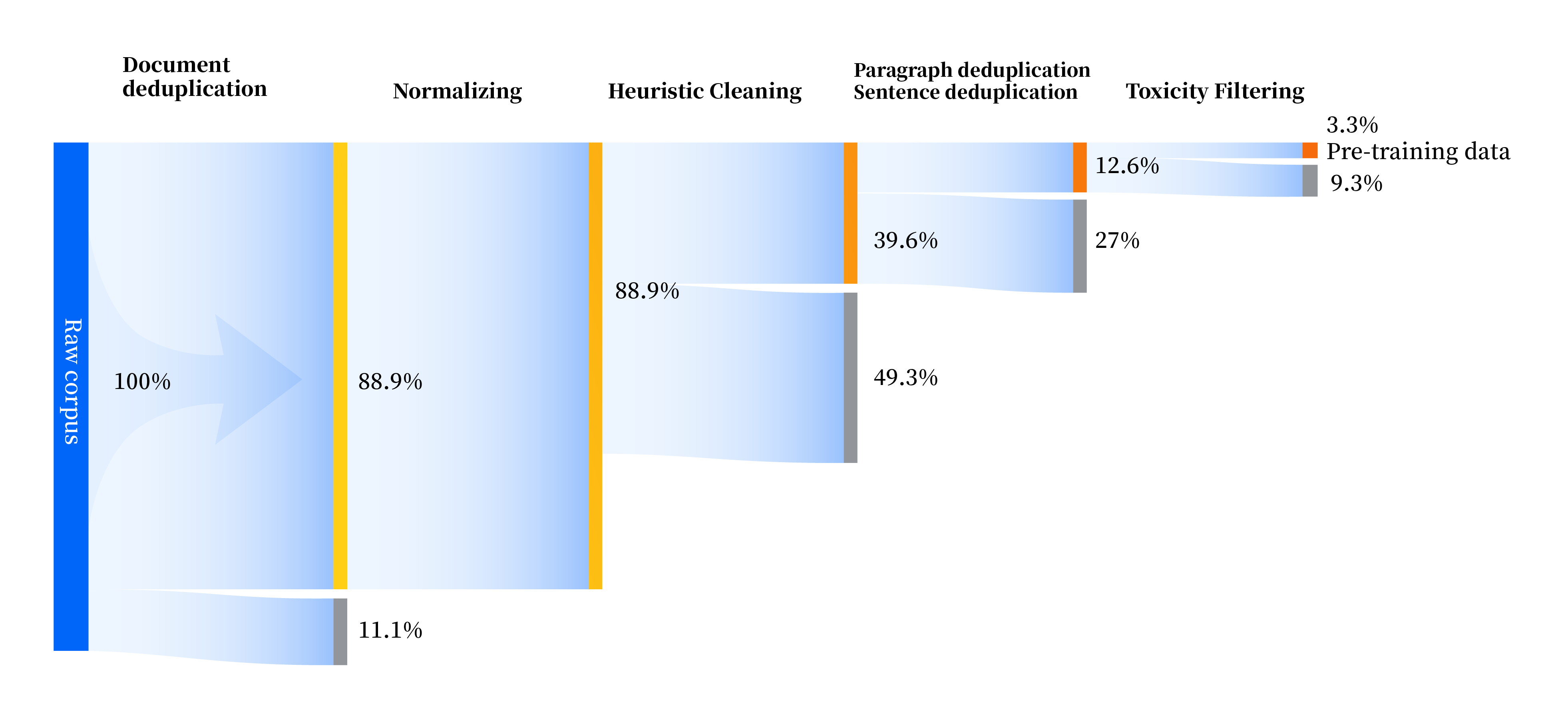
构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。共收集了240TB原始数据,预处理后仅剩10.6TB高质量数据。数据处理流程如下:
协议
本项目中的代码依照Apache-2.0协议开源。使用YAYI 2模型和数据需遵循雅意YAYI 2模型社区许可协议。若用于商业用途,需申请商用许可并遵循相关限制。
引用
如使用本数据集,请引用以下论文:
@article{YAYI 2, author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.}, title = {YAYI 2: Multilingual Open Source Large Language Models}, journal = {arXiv preprint arXiv:2312.14862}, url = {https://arxiv.org/abs/2312.14862}, year = {2023} }
搜集汇总
数据集介绍
构建方式
该数据集的构建基于雅意训练语料,经过精心筛选,包含约100亿个标记,数据量达500GB。在预训练阶段,不仅整合了互联网数据以提升模型的语言能力,还引入了通用精选数据和领域特定数据,以强化模型的专业技能。通用精选数据涵盖了报纸、文献、代码、书籍和百科等多种类型,确保数据的高质量和多样性。此外,数据处理流程包括标准化、启发式清洗、多级去重和毒性过滤,确保最终数据的高质量。
特点
此数据集的显著特点在于其大规模和高质量。数据集不仅包含广泛的新闻报道和学术论文,还涵盖了多种编程语言的源码和丰富的文学作品,为语言模型提供了多样的语境和词汇。此外,数据集经过严格的多级去重和毒性过滤,确保了数据的纯净度和适用性。
使用方法
使用该数据集时,用户需确保本地存储空间超过500GB,并根据所选的标记器处理超过100亿个标记。数据集适用于训练中文预训练大模型,尤其适合需要处理多领域数据和提升专业技能的模型。使用前,请遵循Apache-2.0开源协议,并根据需要申请商用许可。
背景与挑战
背景概述
雅意预训练数据集(wenge-research/yayi2_pretrain_data)是由雅意研究团队精心构建的,旨在推动中文预训练大模型开源社区的发展。该数据集于2023年由Yin Luo、Qingchao Kong、Nan Xu等研究人员共同创建,其核心研究问题在于如何通过大规模、高质量的数据集来提升语言模型的性能和泛化能力。数据集包含了约100B的精选数据,涵盖了报纸、文献、代码、书籍、百科等多种类型,旨在为模型提供丰富的语境和专业知识。该数据集的发布不仅为中文自然语言处理领域提供了宝贵的资源,也为全球预训练模型研究提供了新的视角和方法。
当前挑战
尽管雅意预训练数据集在数据规模和质量上具有显著优势,但其构建过程中仍面临诸多挑战。首先,数据来源的多样性要求在数据清洗和处理过程中必须具备高度的精确性和效率,以确保数据的一致性和可用性。其次,数据集的构建涉及大量的计算资源和存储空间,如何在有限的资源下高效地完成数据处理和模型训练是一个重要问题。此外,数据集的开放性和共享性也带来了数据隐私和安全方面的挑战,如何在保障数据安全的前提下促进数据的开源和共享,是该数据集未来发展中需要解决的关键问题。
常用场景
经典使用场景
在自然语言处理领域,wenge-research/yayi2_pretrain_data数据集的经典使用场景主要体现在预训练大模型的构建与优化上。该数据集通过整合互联网数据、通用精选数据和领域特定数据,为模型提供了丰富的语言知识和专业技能。例如,在构建多语言支持的预训练模型时,该数据集能够显著提升模型对中文及其他语言的理解和生成能力,从而在跨语言翻译、文本摘要和问答系统等任务中表现出色。
衍生相关工作
基于wenge-research/yayi2_pretrain_data数据集,研究者们开发了多种衍生工作,包括改进的预训练算法、多任务学习模型和跨语言迁移学习方法。例如,有研究团队利用该数据集开发了针对特定领域的预训练模型,显著提升了模型在法律、医疗等专业领域的应用效果。此外,该数据集还促进了多语言模型的联合训练和跨语言知识共享,推动了全球范围内的自然语言处理技术发展。
数据集最近研究
最新研究方向
在自然语言处理领域,雅意预训练数据集的最新研究方向主要集中在多语言模型的优化与应用上。随着全球化的深入,跨语言理解和生成能力成为研究热点,雅意数据集通过融合中英文等多语言数据,为构建高效的多语言预训练模型提供了坚实基础。此外,数据集在数据清洗和处理方面的创新,如多级去重和毒性过滤,进一步提升了数据质量,推动了模型在实际应用中的稳定性和可靠性。这些研究不仅有助于提升模型的语言理解能力,还为多语言环境下的智能应用开辟了新的可能性。
以上内容由遇见数据集搜集并总结生成


