Hredpajama_instruct_7b_MU_RedPajama-Data-1T_reservoir_eng_tokenized_normal
收藏Hugging Face2025-03-28 更新2025-03-29 收录
下载链接:
https://huggingface.co/datasets/samihormi/Hredpajama_instruct_7b_MU_RedPajama-Data-1T_reservoir_eng_tokenized_normal
下载链接
链接失效反馈官方服务:
资源简介:
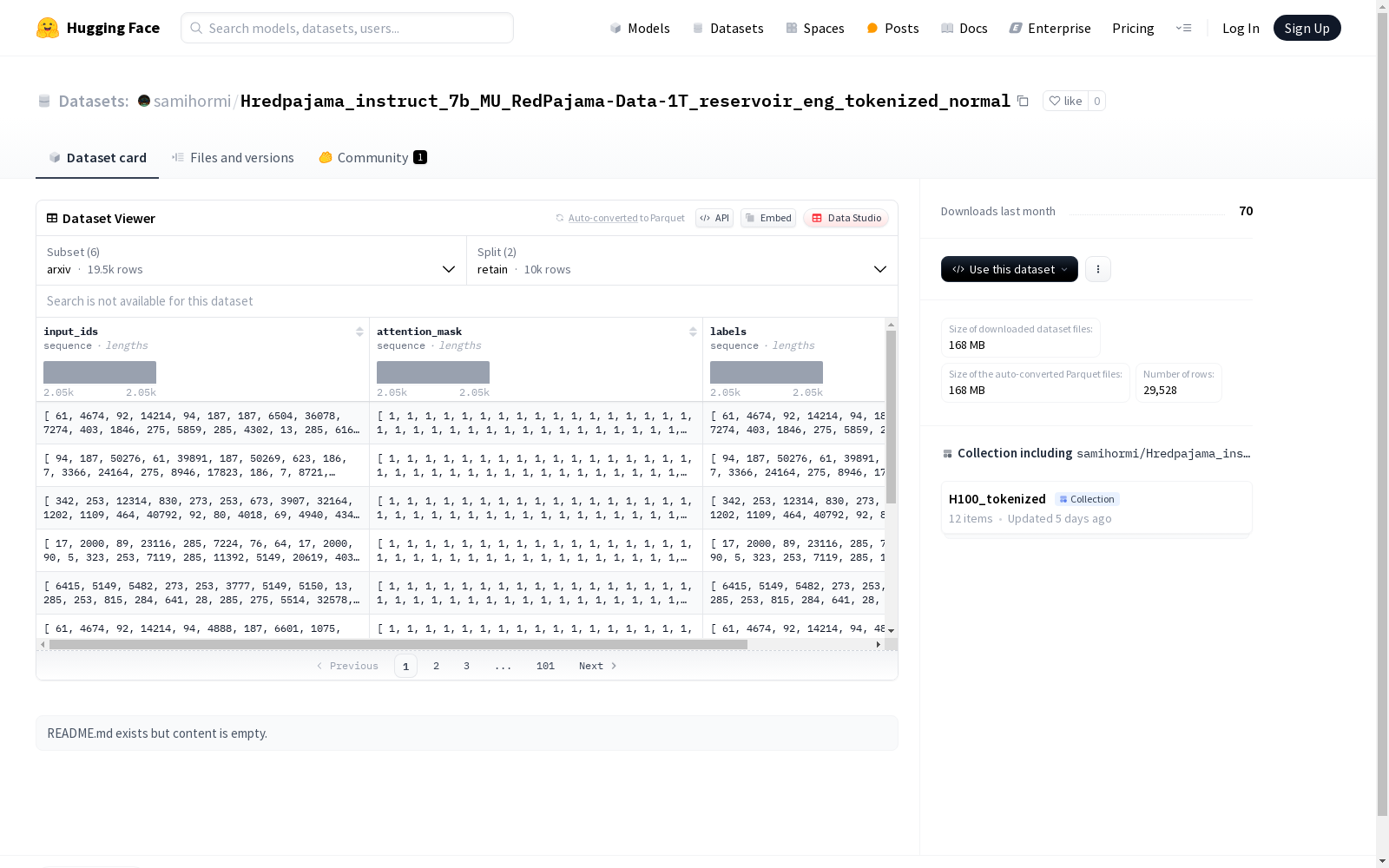
该数据集包含了多个来源的数据,如arxiv、common_crawl、github、stackexchange和wikipedia。每个数据集都包含输入ID序列、注意力掩码序列和标签序列。具体描述如下:
arxiv数据集:包含10043个'retain'示例和9487个'forget'示例。
c4数据集:包含1049个'retain'示例和1038个'forget'示例。
common_crawl和github数据集:没有数据示例。
stackexchange数据集:包含1021个'retain'示例和1036个'forget'示例。
wikipedia数据集:包含2788个'retain'示例和3066个'forget'示例。
创建时间:
2025-03-23
搜集汇总
数据集介绍
构建方式
该数据集基于RedPajama-Data-1T海量语料库构建,采用多源异构数据融合策略,涵盖arxiv学术论文、c4网络文本、common_crawl网页数据、github代码库、stackexchange技术问答及wikipedia百科条目六大知识领域。通过reservoir采样技术实现数据均衡化处理,并运用tokenized标准化流程对文本进行序列编码,最终形成包含input_ids、attention_mask和labels三组特征的结构化数据。数据划分采用retain-forget双分支设计,为机器学习模型提供精准的训练与验证样本。
使用方法
研究者可通过HuggingFace数据集库直接加载特定领域配置,如加载arxiv子集时系统自动返回retain/forget双分割数据。input_ids序列可直接输入Transformer架构,attention_mask有效标识填充位置,labels序列支持因果语言建模和指令微调任务。针对模型遗忘学习等前沿研究,可利用双分割特性设计对比实验,其中forget子集特别适用于机器遗忘(machine unlearning)领域的算法验证。
背景与挑战
背景概述
Hredpajama_instruct_7b_MU_RedPajama-Data-1T_reservoir_eng_tokenized_normal数据集是基于RedPajama-Data-1T项目构建的高质量语言模型预训练数据集,专注于英文文本的指令微调任务。该数据集由多个子集构成,包括arXiv学术论文、C4网络文本、Common Crawl网页数据、GitHub代码库、StackExchange技术问答以及Wikipedia百科全书内容,涵盖了广泛的领域和文本类型。其核心研究问题在于如何通过大规模、多样化的文本数据提升语言模型在指令理解和生成任务上的性能。RedPajama项目作为开放学术倡议的产物,旨在为研究社区提供可复现的大模型训练基础,对推动开源语言模型的发展具有显著影响力。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域适应性方面,不同来源数据的质量差异和领域分布不均衡可能导致模型偏置,例如学术论文与网络文本的语言风格差异会加大模型统一表征的难度;数据处理方面,原始网页数据包含大量噪声和重复内容,需设计高效的过滤和标准化流程。特别在指令微调场景中,如何从非结构化文本中构建高质量的(input, output)配对成为关键瓶颈。此外,多源数据的版权合规性审查与隐私信息清除也构成了数据集构建过程中的法律与技术双重挑战。
常用场景
经典使用场景
在自然语言处理领域,Hredpajama_instruct_7b_MU_RedPajama-Data-1T_reservoir_eng_tokenized_normal数据集凭借其多源异构的文本数据,成为训练大规模语言模型的理想选择。该数据集整合了学术论文、技术文档、社区问答等多样化语料,特别适合用于指令微调任务的基准测试。研究人员通过其划分的retain/forget子集,能够系统评估模型在不同数据分布下的知识保留与遗忘特性。
解决学术问题
该数据集有效解决了大语言模型训练中数据异构性建模的难题,为研究数据选择偏差对模型性能的影响提供了标准实验平台。其细粒度的数据来源标注,使得学术界能够深入探究不同领域文本(如arXiv论文与StackExchange问答)对模型知识结构的差异化贡献,推动了数据高效利用与模型遗忘机制的理论研究。
实际应用
在实际应用中,该数据集支撑了智能问答系统和学术文献摘要生成系统的开发。企业利用其丰富的技术社区语料训练专业领域助手,显著提升了代码生成和技术问题解答的准确率。医疗健康领域则通过微调其学术论文子集,构建了具备专业文献解读能力的辅助诊疗工具。
数据集最近研究
最新研究方向
在自然语言处理领域,RedPajama数据集因其涵盖arxiv、c4、stackexchange和wikipedia等多源异构数据而备受关注。最新研究聚焦于利用该数据集进行大规模语言模型的知识遗忘与保留机制探索,通过划分retain与forget子集,分析模型在不同数据分布下的性能变化。这一方向与当前AI伦理研究中模型可解释性、数据隐私保护等热点议题深度契合,为构建更安全可控的生成式AI系统提供了重要实验基础。
以上内容由遇见数据集搜集并总结生成


