bigbio/bionlp_st_2013_cg
收藏Hugging Face2022-12-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/bigbio/bionlp_st_2013_cg
下载链接
链接失效反馈官方服务:
资源简介:
BioNLP 2013 CG数据集是一个专注于癌症遗传学领域的事件抽取任务,同时也是BioNLP共享任务(ST)2013的主要任务之一。该任务旨在从文本中识别事件,这些事件表示为给定物理实体的结构化n元关联。与之前的BioNLP共享任务系列不同,CG任务不仅涉及癌症领域,还涉及广泛的病理过程和多层次的生物组织,从分子到细胞和器官水平,直至整个生物体。最终测试集的提交来自六个团队。
The BioNLP 2013 CG dataset is an event extraction task centered on the domain of cancer genetics, and it constitutes one of the core tasks of the BioNLP Shared Task (ST) 2013. This task aims to identify events within textual data, where each event is formalized as a structured n-ary association of specified physical entities. In contrast to earlier editions of the BioNLP Shared Task series, the CG task not only covers the cancer domain but also encompasses a broad range of pathological processes and multi-level biological hierarchies, ranging from molecular, cellular and organ levels up to the entire living organism. Submissions for the final test set were received from six participating teams.
提供机构:
bigbio
原始信息汇总
BioNLP 2013 CG 数据集概述
基本信息
- 语言: 英语
- 许可证: GENIA_PROJECT_LICENSE
- 多语言性: 单语种
- 数据集名称: BioNLP 2013 CG
- 主页: https://github.com/openbiocorpora/bionlp-st-2013-cg
- 是否公开: 是
- 是否包含PubMed数据: 是
任务类型
- 事件抽取 (EVENT_EXTRACTION)
- 命名实体识别 (NAMED_ENTITY_RECOGNITION)
- 指代消解 (COREFERENCE_RESOLUTION)
数据集描述
BioNLP 2013 CG 数据集主要关注癌症遗传学领域的事件抽取任务,是2013年BioNLP共享任务(ST)的主要任务之一。该任务旨在从文本中识别事件,并以结构化的n元关联形式表示给定的物理实体。与之前的BioNLP ST系列事件抽取任务相比,CG任务不仅关注癌症领域,还涉及从分子到细胞、器官乃至整个生物体的广泛病理过程和多级生物组织。
引用信息
@inproceedings{pyysalo-etal-2013-overview, title = "Overview of the Cancer Genetics ({CG}) task of {B}io{NLP} Shared Task 2013", author = "Pyysalo, Sampo and Ohta, Tomoko and Ananiadou, Sophia", booktitle = "Proceedings of the {B}io{NLP} Shared Task 2013 Workshop", month = aug, year = "2013", address = "Sofia, Bulgaria", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/W13-2008", pages = "58--66", }
搜集汇总
数据集介绍
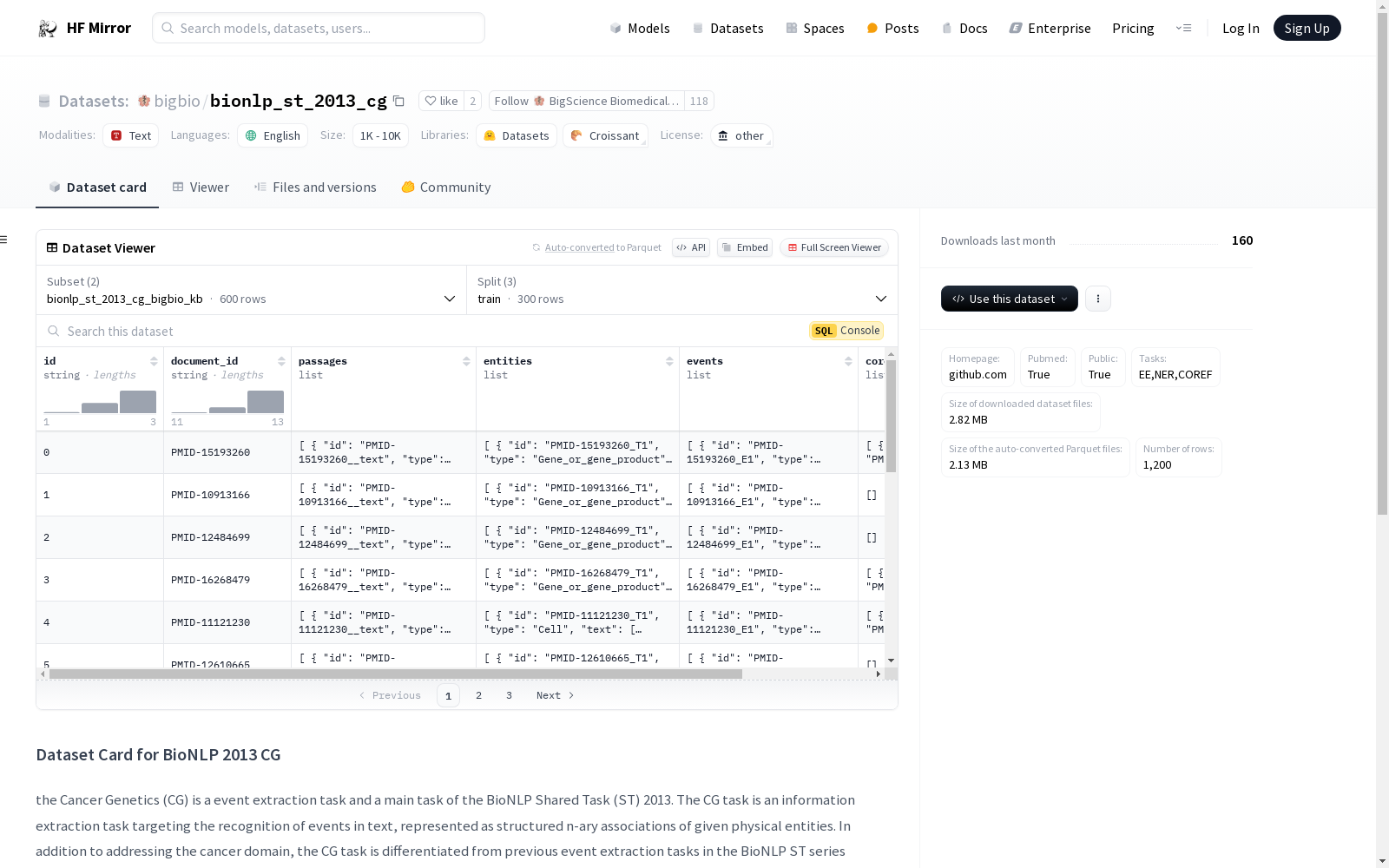
构建方式
该数据集源自2013年BioNLP共享任务中的癌症遗传学(CG)任务,专注于从文本中提取事件信息。构建过程中,数据集涵盖了从分子到整个生物体的多层次生物组织,旨在识别和表示文本中的结构化n元关联实体。通过整合多层次的病理过程和生物组织信息,数据集为事件提取任务提供了丰富的资源。
特点
该数据集的显著特点在于其广泛的应用领域和多层次的生物组织覆盖,从分子到整个生物体,涵盖了多种病理过程。此外,数据集支持事件提取、命名实体识别和共指消解等多项任务,为生物医学文本处理提供了全面的解决方案。
使用方法
该数据集适用于多种生物医学文本处理任务,包括事件提取、命名实体识别和共指消解。用户可以通过访问其GitHub主页获取数据集,并根据任务需求进行数据预处理和模型训练。数据集的广泛应用领域和多任务支持使其成为生物医学信息提取研究的重要资源。
背景与挑战
背景概述
BioNLP 2013 CG数据集是BioNLP Shared Task 2013中的一个重要组成部分,专注于癌症遗传学领域的事件抽取任务。该数据集由Sampo Pyysalo、Tomoko Ohta和Sophia Ananiadou等人创建,旨在识别和结构化表示文本中的事件,这些事件涉及多种物理实体的n元关联。与以往的事件抽取任务不同,BioNLP 2013 CG不仅关注癌症领域,还涵盖了从分子到整个生物体的多层次生物组织和病理过程。该数据集的创建标志着生物医学文本处理领域在复杂事件抽取方面的重大进展,为相关研究提供了宝贵的资源。
当前挑战
BioNLP 2013 CG数据集在构建过程中面临多项挑战。首先,该数据集需要处理复杂的生物医学文本,这些文本通常包含高度专业化的术语和多层次的生物组织描述,增加了事件抽取的难度。其次,数据集涉及的事件类型多样,从分子层面的反应到整个生物体的病理变化,要求模型具备广泛的知识覆盖和精确的语义理解能力。此外,数据集的构建还需要解决跨文档的共指消解问题,以确保事件的完整性和一致性。这些挑战不仅推动了信息抽取技术的发展,也为后续的生物医学文本分析提供了重要的研究方向。
常用场景
经典使用场景
在生物医学领域,BioNLP 2013 CG数据集的经典使用场景主要集中在事件抽取、命名实体识别和共指消解等任务上。该数据集通过识别和结构化文本中的生物实体及其相互关系,为癌症遗传学领域的研究提供了丰富的信息资源。研究者可以利用该数据集进行模型训练,以自动提取和分析复杂的生物医学事件,从而加速相关领域的知识发现和应用。
实际应用
在实际应用中,BioNLP 2013 CG数据集被广泛用于开发和验证生物医学文本分析工具。例如,在临床研究中,这些工具可以帮助医生和研究人员快速提取和分析与癌症相关的遗传信息,从而支持诊断和治疗决策。此外,该数据集还为生物医学文献的自动化综述和知识图谱构建提供了基础数据支持。
衍生相关工作
基于BioNLP 2013 CG数据集,研究者们开发了多种先进的自然语言处理模型和算法,用于生物医学文本的自动分析。例如,一些研究工作专注于提高事件抽取的准确性和召回率,而另一些则探索了如何在多层次生物组织背景下进行更精细的实体识别和关系抽取。这些衍生工作不仅推动了生物医学信息学的发展,也为其他领域的文本分析提供了借鉴。
以上内容由遇见数据集搜集并总结生成


