SLAKE
收藏arXiv2025-09-30 收录
下载链接:
https://www.med-vqa.com/slake/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集被用于评估临床环境中的语言模型,它与VQA-RAD一同使用,以此来基准测试LLaVA-Med模型的表现。其所涉及的任务是封闭集问题评估。
This dataset is utilized for evaluating language models in clinical environments. It is used alongside VQA-RAD to benchmark the performance of the LLaVA-Med model, with the associated task being closed-set question evaluation.
搜集汇总
数据集介绍
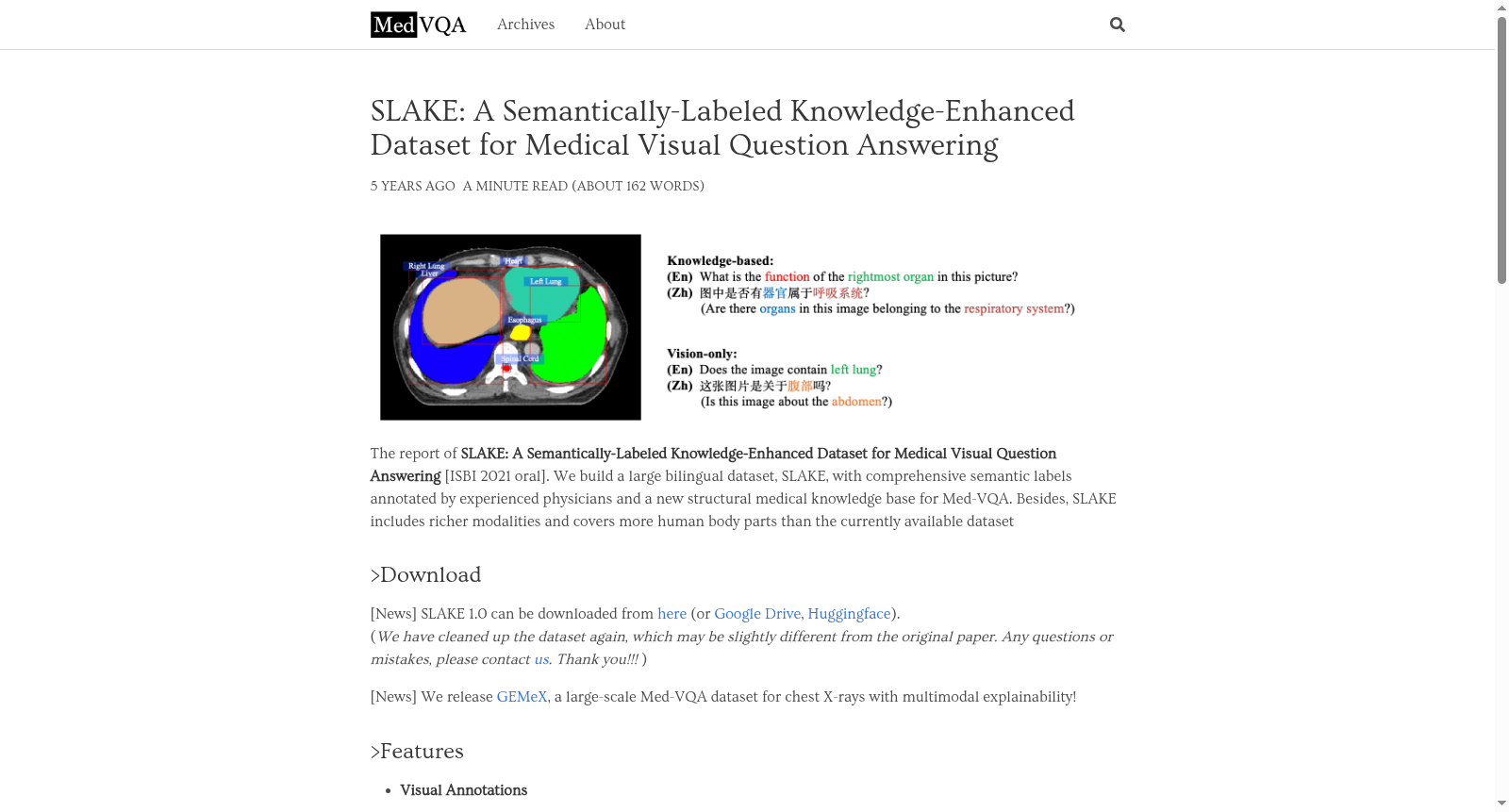
构建方式
在医学视觉问答领域,高质量标注数据集的匮乏长期制约着技术的发展。为填补这一空白,SLAKE数据集应运而生,其构建过程严谨而系统。首先,研究团队从三个公开医学影像数据集中精选了642张放射学图像,涵盖CT、MRI和X-Ray三种模态,并覆盖头、颈、胸、腹及盆腔等人体部位。随后,由经验丰富的医师利用ITK-SNAP工具对这些图像进行精细的语义标注,包括器官与疾病的掩膜分割和边界框标注。与此同时,团队基于OwnThink知识库,通过筛选、清洗与人工校验,构建了一个包含2603个英文和2629个中文三元组的医学知识图谱,用以支撑需要外部知识的复杂问题。最后,医师借助自研的标注系统,依据预定义模板和十种内容类型生成14,028个中英文双语问答对,并通过平衡答案分布来降低统计偏差。数据集按图像级别以70%、15%、15%的比例划分为训练集、验证集和测试集。
使用方法
使用SLAKE数据集进行医学视觉问答研究时,研究者可遵循一套成熟的实验框架。首先,视觉特征通过预训练的VGG16网络从放射学图像中提取;对于双语问题,则需设计专门的分词器以生成中英文词嵌入,并利用1024维LSTM提取文本语义并分类问题类型。对于纯视觉问题,视觉与文本特征被送入堆叠注意力网络(SAN)进行多模态融合与分类。对于基于知识的问题,需额外从自建医学知识图谱中提取与问题相关的实体嵌入(如关系与尾实体),利用TransE方法计算头实体嵌入,并将其与多模态融合特征结合后进行分类。实验表明,利用语义分割掩膜预训练VGG骨干网络可使准确率提升2.6%,而引入知识图谱可使基于知识问题的准确率提升2.0%。研究者可根据任务需求,灵活选择是否使用语义标注或知识图谱模块,以验证不同模型在SLAKE上的表现。
背景与挑战
背景概述
医学视觉问答(Med-VQA)作为人工智能与医疗交叉领域的前沿方向,旨在使机器能够依据放射学图像回答临床问题,从而辅助患者获取健康信息、协助医生进行诊断决策并支持临床教育。然而,该领域长期受困于高质量标注数据的匮乏,现有数据集如VQA-RAD虽具开创性,却缺乏语义标签(如器官分割掩膜或目标边界框)及外部医学知识支持,难以支撑复杂推理任务。为填补这一空白,香港理工大学联合四川大学华西医院及四川省人民医院的研究团队于2021年创建了SLAKE数据集。该数据集包含642张放射学图像(涵盖CT、MRI和X光三种模态)及14028个中英双语问答对,覆盖头部、颈部、胸部、腹部及盆腔等人体部位,并由资深医师标注了39种器官与12种疾病的语义信息。此外,团队构建了包含5232条医学知识三元组的知识图谱,以支持需要外部知识的问题回答。SLAKE的发布显著推动了Med-VQA领域的发展,为模型训练与评估提供了更丰富、更平衡的基准资源。
当前挑战
SLAKE数据集所面临的挑战主要体现在两个层面。在领域问题层面,Med-VQA需回答的临床问题具有高度专业性与安全性要求,现有模型在SLAKE上的准确率仅约73%,远未达到临床应用标准,尤其开放性问题因答案自由度高而更具难度。知识型问题需结合外部知识图谱进行多步推理,而当前模型性能提升有限(约2%),表明知识融合机制尚待突破。在构建过程中,挑战尤为显著:首先,图像标注需由经验丰富的医师手动完成语义分割与边界框标注,耗时超过半年,且需确保跨模态(CT、MRI、X光)和跨身体部位的标注一致性;其次,知识图谱的构建需从大规模开放知识库中筛选并精炼医学相关三元组,手动过滤无关实体(如胃炎)并确保双语(中英)覆盖;最后,为缓解模型对答案分布的统计偏倚,团队需刻意平衡问答对中“是/否”答案的比例,例如对同一问题在不同部位图像中均等采样,这对数据设计提出了精细化的要求。
常用场景
经典使用场景
在医学视觉问答(Med-VQA)领域,SLAKE数据集被广泛用作基准测试平台,以评估和比较不同模型在临床图像理解与推理任务上的表现。该数据集包含642张放射学图像(涵盖CT、MRI和X光模态),并配以超过14,000个中英双语问题-答案对,问题类型涵盖纯视觉问题和基于知识的问题。研究者常利用SLAKE训练和测试多模态融合模型,如堆叠注意力网络(SAN),以验证其在器官识别、疾病定位和医学属性判断等任务中的有效性。数据集的语义分割掩码和边界框标注进一步支持了细粒度视觉推理研究。
解决学术问题
SLAKE解决了Med-VQA领域缺乏高质量、多模态、语义标注丰富的数据集这一核心学术难题。此前,VQA-RAD等数据集规模较小且未提供语义标签,限制了模型对感兴趣区域的定位能力。SLAKE通过引入器官和疾病的精确分割掩码、边界框以及可扩展的医学知识图谱,使得模型能够处理需要外部知识的复杂组合问题,例如器官功能或疾病治疗方法的查询。该数据集还通过平衡答案分布缓解了统计偏差问题,为开发更具鲁棒性和泛化能力的Med-VQA系统奠定了坚实基础,推动了该领域从简单视觉匹配向复杂临床推理的跨越。
实际应用
在实际医疗场景中,SLAKE数据集支撑的Med-VQA系统可被集成到临床决策支持工具中,辅助医生进行放射学图像的快速解读,提供第二诊断意见。患者也能通过此类系统自主获取关于影像的健康信息,增强医疗决策的参与度。此外,该系统可嵌入医学教育平台,用于培训医学生和放射科医师,通过问答交互提升其图像判读能力。在医疗对话AI领域,SLAKE驱动的技术有望被整合进智能问诊系统,实现从影像到自然语言反馈的端到端服务,从而提升诊疗效率并减轻医疗资源紧张的压力。
数据集最近研究
最新研究方向
在医学视觉问答领域,SLAKE数据集的开创性贡献在于其深度融合了语义标注与外部知识图谱,为多模态推理研究开辟了新路径。当前前沿方向聚焦于利用该数据集的大规模双语问答对及细粒度器官分割标签,推动模型从简单视觉匹配向复杂临床推理演进,尤其关注知识驱动型问题的解答能力。随着医疗AI对可解释性与鲁棒性要求的提升,SLAKE所引入的平衡化答案分布与结构化知识三元组,正成为评估模型消除统计偏差、整合领域知识的关键基准,其影响已辐射至辅助诊断、临床教育及多语言医疗对话系统等热点应用场景。
相关研究论文
- 1SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering香港理工大学计算机系、四川大学华西医院超声科、四川省医学科学院四川省人民医院 · 2021年
以上内容由遇见数据集搜集并总结生成


