SLAKE
收藏arXiv2021-02-19 更新2024-06-21 收录
下载链接:
http://www.med-vqa.com/slake
下载链接
链接失效反馈官方服务:
资源简介:
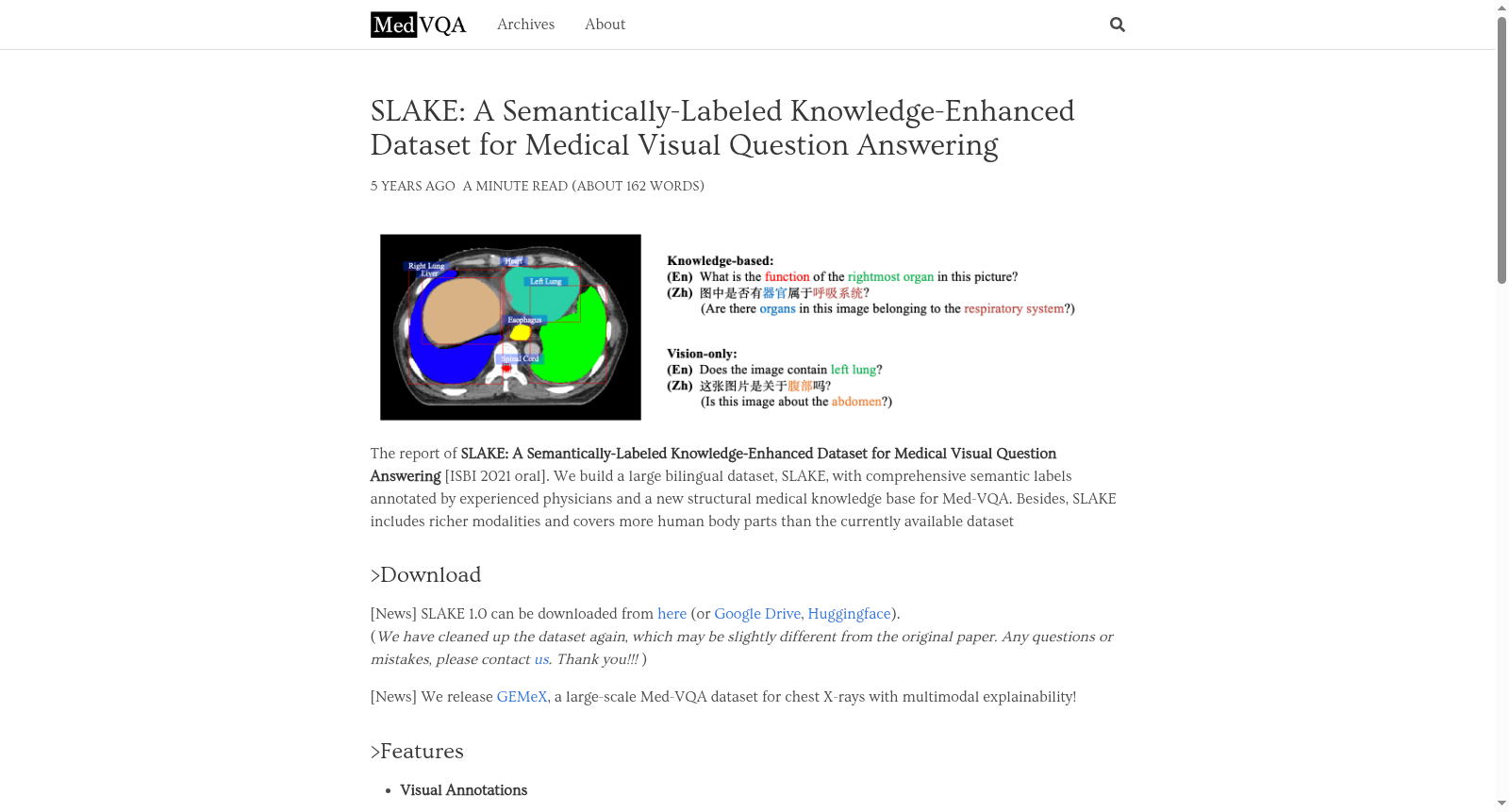
SLAKE是一个大规模、语义标注丰富、知识增强的双语医疗视觉问答数据集,由香港理工大学和四川大学等机构合作创建。该数据集包含642张放射学图像,涵盖多种成像模式和人体部位,共有14,000个问题-答案对,旨在通过提供精确的视觉和文本标注以及扩展的医学知识图谱,推动医疗视觉问答系统的发展。SLAKE不仅覆盖了更多的身体部位和问题类型,还提供了详细的语义标签,以区分仅依赖视觉信息的问题和需要外部医学知识的问题。此数据集的应用领域广泛,包括辅助诊断、临床教育和患者健康信息获取等,旨在解决医疗领域中视觉信息处理和理解的挑战。
SLAKE is a large-scale, semantically richly annotated, knowledge-enhanced bilingual medical visual question answering (VQA) dataset co-created by institutions including The Hong Kong Polytechnic University and Sichuan University. This dataset contains 642 radiological images covering diverse imaging modalities and human anatomical regions, with a total of 14,000 question-answer pairs. It aims to advance the development of medical visual question answering systems by providing precise visual and textual annotations as well as extended medical knowledge graphs. SLAKE not only covers a broader range of anatomical regions and question types, but also provides detailed semantic labels to distinguish between questions that rely solely on visual information and those that require external medical knowledge. This dataset has wide application scenarios, including auxiliary diagnosis, clinical education, patient health information acquisition and more, aiming to address the challenges of visual information processing and understanding in the medical field.
提供机构:
香港理工大学计算机系、四川大学华西医院超声科、四川省医学科学院四川省人民医院
创建时间:
2021-02-19
搜集汇总
数据集介绍
构建方式
在医学视觉问答领域,构建高质量数据集需融合多模态医学影像与专业临床知识。SLAKE数据集通过整合来自公开医学影像库的642张放射学图像,涵盖CT、MRI和X射线等多种模态,覆盖头部、颈部、胸腹部等人体部位。由经验丰富的医师使用ITK-SNAP工具对器官与病灶进行精细语义标注,包括分割掩码与检测边界框。同时,基于OwnThink知识库构建了包含2600余条双语三元组的医学知识图谱,以支持外部知识推理。问题生成环节通过预定义模板与医师人工修订相结合,确保了14,028个问答对的多样性与临床准确性,并采用分层抽样策略划分训练、验证与测试集,以评估模型泛化能力。
特点
SLAKE数据集在医学视觉问答领域展现出多重独特优势。其核心在于提供了丰富的语义标注,包括器官与疾病的精细分割掩码和边界框,为模型定位感兴趣区域提供了结构化视觉信息。数据集涵盖开放式与封闭式双语问答,并创新性地引入了知识增强问题,要求模型结合外部医学知识图谱进行推理,如器官功能或疾病治疗方案。相较于现有数据集,SLAKE在模态多样性、人体部位覆盖广度以及问题类型复杂性方面均有显著扩展,同时通过平衡答案分布有效缓解了模型训练中的统计偏差,为开发鲁棒性强的Med-VQA系统奠定了坚实基础。
使用方法
SLAKE数据集适用于训练与评估医学视觉问答模型,其使用需遵循多模态融合与知识推理的框架。研究者可首先提取放射学图像的视觉特征,并利用双语词嵌入与LSTM网络处理问题文本,以区分视觉依赖型与知识增强型问题。对于视觉问题,通过注意力机制融合多模态特征进行分类;对于知识型问题,则需结合知识图谱中实体与关系的嵌入表示,例如采用TransE等方法对齐三元组信息,辅助模型进行医学知识推理。数据集的标准化划分支持模型在训练中优化参数,并通过验证集与测试集评估其临床准确性,从而推动Med-VQA技术在辅助诊断与医学教育等场景的应用发展。
背景与挑战
背景概述
医学视觉问答(Med-VQA)作为人工智能在医疗领域的重要分支,旨在通过分析医学影像并结合临床问题提供精准答案,对辅助诊断、患者教育和临床决策具有深远意义。然而,该领域长期面临高质量公开数据匮乏的困境,制约了相关技术的深入发展。为应对这一挑战,香港理工大学与四川大学华西医院等机构的研究团队于2021年联合构建了SLAKE数据集,该数据集涵盖642张放射影像与1.4万条双语问答对,并创新性地整合了结构化医学知识图谱。通过引入语义分割标注与多模态数据,SLAKE不仅扩展了人体部位覆盖范围,更推动了Med-VQA系统从单纯视觉理解向知识增强推理的范式演进,为医疗人工智能研究提供了关键基准。
当前挑战
SLAKE数据集致力于解决医学视觉问答中复杂临床问题的精准推理挑战,其核心难点在于如何融合多模态医学信息与外部知识进行深度语义理解。具体而言,数据构建过程面临双重挑战:一是医学标注的专业壁垒,需由资深医师对影像中的器官与病变进行精细分割与检测,并设计涵盖形态、功能等维度的多样化问题,耗时长达半年以上;二是知识整合的复杂性,需从海量医学知识库中筛选并构建以器官为中心的结构化图谱,以支持对疾病成因、治疗方案等知识型问题的推理,同时需平衡双语问答的语义一致性与数据偏差,确保模型泛化能力。
常用场景
经典使用场景
在医学视觉问答领域,SLAKE数据集作为一项关键资源,其经典使用场景集中于训练和评估多模态融合模型。该数据集通过提供丰富的语义标注和结构化知识图谱,使得研究者能够开发出能够理解放射影像并回答临床问题的智能系统。例如,模型可利用数据集中的器官分割掩码和边界框标注,精准定位图像中的感兴趣区域,进而回答关于疾病诊断、器官功能等复杂问题。这种场景不仅推动了医学人工智能的技术进步,还为临床辅助决策提供了可靠的数据基础。
衍生相关工作
SLAKE数据集的发布催生了一系列相关经典研究工作,尤其是在多模态融合和知识增强模型的设计上。例如,研究者基于其语义标注开发了改进的堆叠注意力网络,结合视觉分割预训练策略,显著提升了模型在视觉问答任务中的准确性。此外,数据集中的知识图谱被用于构建TransE嵌入方法,支持知识推理问题的解答。这些工作不仅扩展了Med-VQA的技术边界,还为后续研究如跨语言问答、疾病预测等方向提供了重要参考。
数据集最近研究
最新研究方向
在医学视觉问答领域,SLAKE数据集凭借其丰富的语义标注和结构化知识图谱,正推动着多模态融合与知识增强模型的前沿探索。当前研究聚焦于如何有效整合视觉特征与外部医学知识,以提升模型对复杂临床问题的推理能力,例如通过注意力机制引导模型在知识图谱中检索相关信息,从而准确回答涉及器官功能或疾病治疗的开放性问题。同时,双语特性促进了跨语言医疗AI应用的发展,使模型能够服务于更广泛的全球医疗场景。这些进展不仅加速了辅助诊断系统的实用化进程,也为临床教育和患者参与决策提供了新的技术支撑。
相关研究论文
- 1SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering香港理工大学计算机系、四川大学华西医院超声科、四川省医学科学院四川省人民医院 · 2021年
以上内容由遇见数据集搜集并总结生成


