harshmistry27/enron-emails
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/harshmistry27/enron-emails
下载链接
链接失效反馈官方服务:
资源简介:
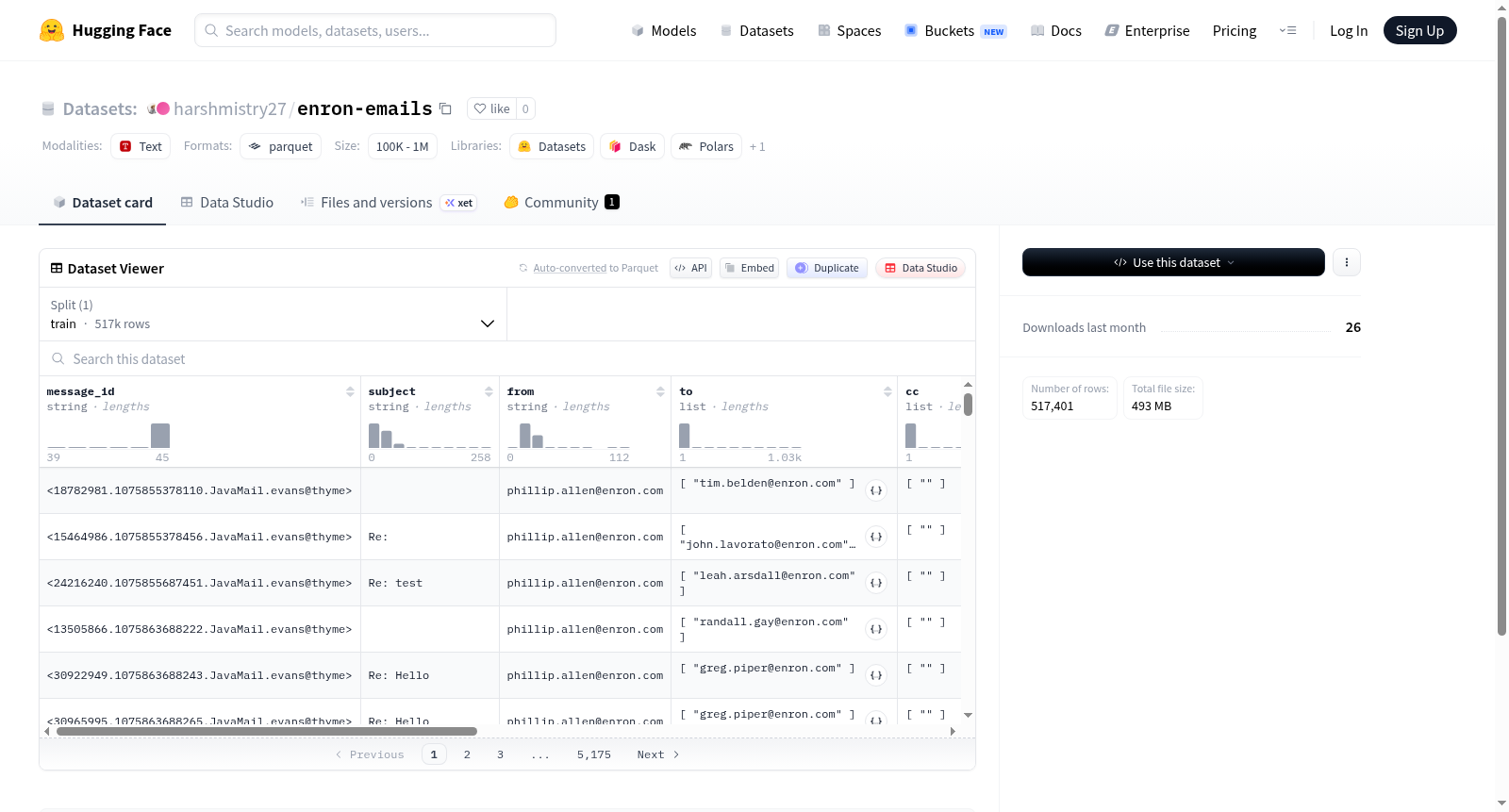
该数据集是一个电子邮件集合,包含517,401个示例,总大小约1.15GB。数据特征包括消息ID、主题、发件人、收件人列表、抄送列表、密送列表、日期时间戳、正文内容和文件名。数据集仅提供训练拆分,用于自然语言处理或电子邮件分析任务。
This dataset is a collection of emails with 517,401 examples and a total size of approximately 1.15GB. The features include message ID, subject, sender, recipient list, CC list, BCC list, date timestamp, body content, and file name. The dataset only provides a training split and is intended for natural language processing or email analysis tasks.
提供机构:
harshmistry27
搜集汇总
数据集介绍
构建方式
Enron电子邮件数据集源自美国安然公司(Enron Corporation)在2001年破产后公开的约50万封真实企业邮件,经联邦能源监管委员会整理后成为研究机构与企业内部通信行为的重要语料库。该数据集在HuggingFace上以Parquet格式存储,共包含517,401条训练样本,每条记录具备message_id、subject、from、to、cc、bcc、date、body及file_name等九个字段,其中收件人、抄送和密送字段采用序列化字符串数组结构,日期字段以带UTC时区的时间戳格式存储,确保了时间信息的精确性与跨时区一致性。数据文件按统一配置进行分片,便于分布式加载与处理。
特点
该数据集的突出特点在于其真实性与规模性——源自全球知名企业破产后曝光的真实邮件,涵盖了企业内部日常沟通、高层决策、财务操作乃至欺诈行为的完整通信链路,为自然语言处理、社交网络分析、异常检测及组织行为学研究提供了罕见的第一手语料。邮件元数据丰富,包括完整的收发关系与时间戳,使得研究者能够构建动态的通信网络模型;正文与主题字段则支持文本分类、情感分析及摘要生成等任务。此外,数据集的标准化序列字段设计兼顾了多收件人场景的复杂性,增强了数据在关系抽取与图结构建模中的适用性。
使用方法
使用者可通过HuggingFace Datasets库直接加载该数据集,仅需调用`load_dataset("enron-emails", split="train")`即可获取所有训练样本,数据以字典格式返回,各字段可直接按名称索引。适用于构建邮件分类模型(如垃圾邮件检测、主题分类)、进行时序通信模式分析(利用date字段)、提取社交网络边关系(从from与to字段生成有向图),或利用body与subject进行文本生成与摘要研究。值得一提的是,数据集的body字段包含大量企业纯文本内容,可直接用于训练语言模型或进行关键词抽取,而file_name字段则保留了原始邮件文件的来源信息,便于交叉验证与溯源分析。
背景与挑战
背景概述
安然电子邮件数据集(Enron Email Dataset)诞生于2000年代初,由联邦能源监管委员会在对安然公司进行调查期间收集,并由卡内基梅隆大学等机构整理发布。该数据集包含约51.7万封来自安然公司雇员的真实商业电子邮件,时间跨度从1998年至2002年,覆盖了这家能源巨头从辉煌到破产的全过程。作为大规模企业真实邮件通信的罕见样本,它已成为自然语言处理、社交网络分析和组织行为研究领域的基准资源,推动了电子邮件摘要、欺诈检测、层级关系推断等课题的研究进展。
当前挑战
该数据集核心解决的领域问题包括:从非结构化邮件中提取语义信息(如主题分类)、基于通信模式推断组织架构(如上下级关系)以及异常行为检测(如内幕交易信号)。构建过程中的挑战极为显著:原始邮件数据涉及大量隐私和伦理问题,需匿名化处理;邮件格式不统一,包含HTML、附件编码、回复链截断等问题,增加了清洗标准化难度;此外,时间跨度内公司结构剧变,导致元数据(如部门归属)缺失,给跨时间研究带来连贯性难题。
常用场景
经典使用场景
Enron电子邮件数据集(Enron Email Dataset)是自然语言处理与计算社会科学领域中最具标志性的公开语料库之一。该数据集源自美国安然公司(Enron Corporation)在2001年破产事件后由联邦能源监管委员会公开的真实公司内部电子邮件,共计约51.7万封邮件,覆盖151位员工的通信记录。其经典使用场景集中于文本分析任务,包括邮件主题与正文的主题建模、情感分析、以及通信网络中个体角色的检测。研究者常利用其丰富的元数据字段(如发件人、收件人、抄送人、时间戳)构建时序社交网络,进而挖掘组织内部信息流动模式与层级结构。此外,该数据集也广泛用于评估文本摘要算法、自动邮件回复系统及异常行为检测模型。
解决学术问题
该数据集为多个学术研究难题提供了宝贵的真实世界基准。首先,它解决了传统语料库缺乏真实组织内部通信结构的困境,使得研究能够深入探究企业环境中信息传播的动力学机制与权力结构对沟通行为的影响。其次,利用时间戳与多层级收件人信息,研究者得以建模电子邮件线程的演化过程,为对话系统与事件抽取任务提供支撑。更重要的是,安然邮件数据集在计算社会科学领域被广泛用于验证关于欺诈检测与异常沟通模式的假设,通过分析发件频率、网络中心性及内容情绪变化,揭示公司治理失效的先兆迹象。该数据集的公开性还促进了自然语言处理模型的公平性比较,推动了跨组织沟通行为建模方法的发展。
衍生相关工作
安然邮件数据集催生了多项里程碑式研究工作。在经典网络科学领域,Klimt与Yang(2004)首次利用该数据集验证了组织内部通信网络的小世界特性和社区发现算法;随后,Diesner与Carley(2005)提出了基于动态网络分析的组织影响力识别方法,开创了通过电子邮件元数据推断企业权力层级的研究范式。在自然语言处理方向,基于该数据集衍生的主题模型改进工作(如Author-Topic模型)成为学科标准工具;而情感分析领域,Culotta等人(2005)将邮件情绪随时间的变化与安然公司股价波动关联分析,实现了文本指标与财务预测的跨学科融合。此外,该数据集还支撑了匿名社交网络合成生成器(如EdgeRipper)的基准测试,并推动了一系列电子邮件个性化摘要算法的竞赛与标准评估框架的建立。
以上内容由遇见数据集搜集并总结生成


