GaMS-Nemotron-Chat
收藏GaMS-Nemotron-Chat 数据集概述
基本信息
- 数据集名称:GaMS-Nemotron-Chat
- 数据集地址:https://huggingface.co/datasets/cjvt/GaMS-Nemotron-Chat
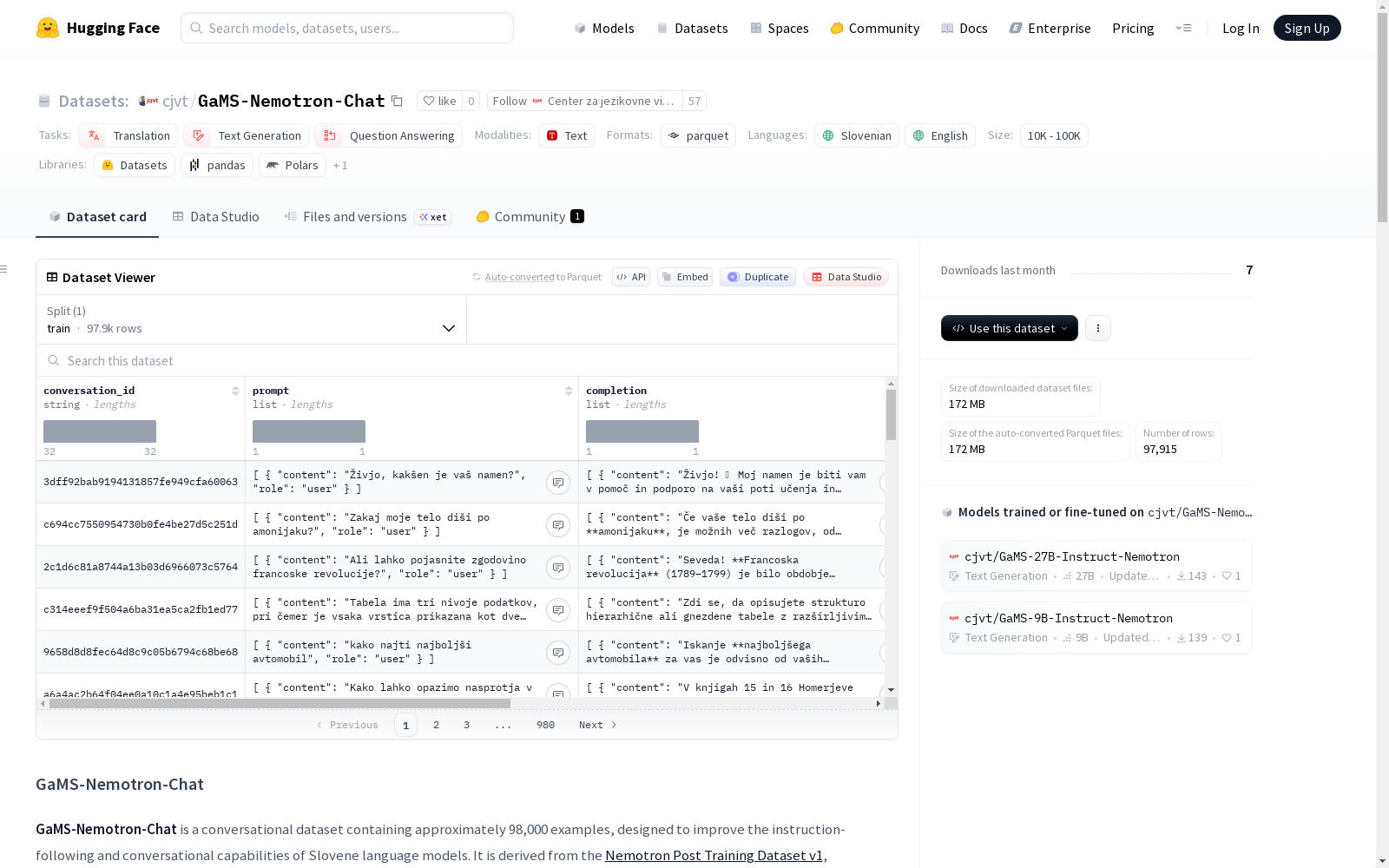
- 数据规模:约 98,000 个示例
- 语言:斯洛文尼亚语(sl)、英语(en)
- 任务类别:翻译(translation)、文本生成(text-generation)、问答(question-answering)
- 规模分类:10K<n<100K
数据集描述
GaMS-Nemotron-Chat 是一个对话数据集,旨在提升斯洛文尼亚语语言模型的指令遵循和对话能力。该数据集源自 Nemotron Post Training Dataset v1,包含由 Qwen3 235B A22B 模型生成的回答,并使用 GaMS-27B Instruct 模型将示例翻译成斯洛文尼亚语。数据集遵循 80:20 的比例,包含翻译的斯洛文尼亚语示例(80%)和原始的英语示例(20%),以保持多语言能力并防止语言退化。
数据集结构
数据集包含一个训练集(train)拆分,具体信息如下:
- 训练集示例数量:97,915
- 训练集大小:292,841,624 字节
- 下载大小:172,074,390 字节
每个示例包含以下字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
conversation_id |
string |
对话的唯一标识符,继承自源数据。 |
prompt |
list |
用户的输入消息。对于斯洛文尼亚语示例,这是原始 LMSYS Chat 1M 用户提示的翻译。 |
completion |
list |
助手的回复。源自 Qwen3-235B 生成(通过 Nemotron),并翻译成斯洛文尼亚语,或为修正身份而重新生成。 |
ds_name |
string |
源数据集的名称(例如 nvidia/Nemotron-Post-Training-Dataset-v1)。 |
ds_split |
string |
源数据集的拆分(例如 chat)。 |
language |
string |
语言代码:sl 表示斯洛文尼亚语条目(从英语翻译),en 表示英语条目。 |
category |
string |
对话的主题类别(例如 explanation、coding、creative writing),源自 LMSYS Chat 1M Clean 分类法。 |
identity |
bool |
指示回复是否专门为修正模型身份(将“Qwen”改为“GaMS”)而重新生成。 |
创建过程
- 源数据选择:利用 Nemotron Post Training Dataset v1 中的 LMSYS Chat 1M 子集,其中的回答由 Qwen3 235B A22B 生成。
- 过滤:在 LMSYS Chat 1M Clean 子集上应用 MinHash LSH 过滤(阈值 0.65),以选择约 80,000 个跨不同类别的多样化和高质量示例。
- 翻译:使用 GaMS 27B Instruct 模型将选定的示例翻译成斯洛文尼亚语。
- 身份修正:对模型自称为“Qwen”的回答,使用自定义提示重新生成,以建立 GaMS 身份(
identity属性设置为 True)。 - 增强:为支持多语言,向最终混合数据中添加了约 20,000 个来自 Nemotron Post Training Dataset v1 的原始英语示例(非重叠)。
使用的数据集和模型
数据集
- Nemotron Post Training Dataset v1 (https://huggingface.co/datasets/nvidia/Nemotron-Post-Training-Dataset-v1):包含由 Qwen3 235B A22B 模型生成的高质量回答的源数据集。
- LMSYS Chat 1M (https://huggingface.co/datasets/lmsys/lmsys-chat-1m):原始真实世界用户提示的源数据集。
- LMSYS Chat 1M Clean (https://huggingface.co/datasets/OpenLeecher/lmsys_chat_1m_clean):用于提示的分类和过滤。
模型
- Qwen3 235B A22B:NVIDIA 用于在 Nemotron 数据集中生成合成回答的模型。
- GaMS-27B Instruct (https://huggingface.co/cjvt/GaMS-27B-Instruct):用于将数据集从英语翻译成斯洛文尼亚语的模型。
应用
基于此数据集微调的 GaMS-9B-Instruct-Nemotron (https://huggingface.co/cjvt/GaMS-9B-Instruct-Nemotron) 和 GaMS-27B-Instruct-Nemotron (https://huggingface.co/cjvt/GaMS-27B-Instruct-Nemotron) 模型,截至 2026 年 1 月,在斯洛文尼亚语聊天竞技场中分别排名第 4 和第 2 位。
引用
bibtex @misc{ petric2025gamsnemotron, author={Timotej Petrič and Domen Vreš and Iztok Lebar Bajec and Marko Robnik-Šikonja}, title={{GaMS-Nemotron-Chat dataset}}, url={https://huggingface.co/datasets/cjvt/GaMS-Nemotron-Chat}, note={Hugging Face repository}, year={2025} }
@misc{ petric2025prilagoditev, author={Petrič, Timotej}, title={Prilagoditev velikih jezikovnih modelov s človeškimi preferencami}, url={https://repozitorij.uni-lj.si/IzpisGradiva.php?lang=slv&id=173848}, note = {Master thesis}, year={2025} }