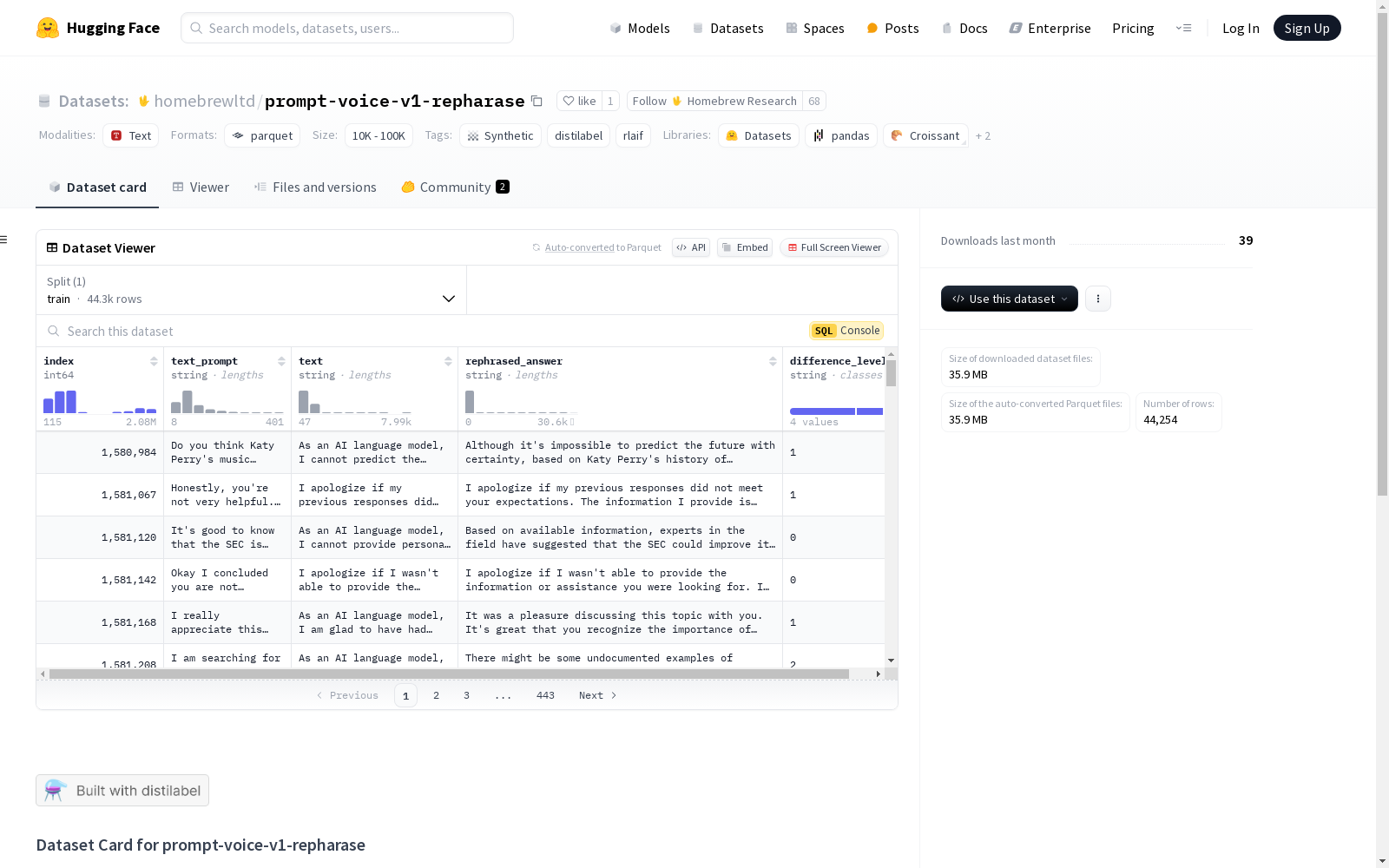
prompt-voice-v1-repharase
收藏数据集卡片 for prompt-voice-v1-repharase
数据集概述
该数据集包含一个 pipeline.yaml 文件,可以使用 distilabel CLI 重现生成该数据集的管道:
console distilabel pipeline run --config "https://huggingface.co/datasets/homebrewltd/prompt-voice-v1-repharase/raw/main/pipeline.yaml"
或者探索配置:
console distilabel pipeline info --config "https://huggingface.co/datasets/homebrewltd/prompt-voice-v1-repharase/raw/main/pipeline.yaml"
数据集结构
数据集的示例结构如下:
配置: default
json { "index": 115, "prompt": "u003c|sound_start|u003eu003c|sound_0206|u003eu003c|sound_0314|u003eu003c|sound_0314|u003eu003c|sound_0314|u003eu003c|sound_0314|u003eu003c|sound_0041|u003eu003c|sound_0323|u003eu003c|sound_0323|u003eu003c|sound_0212|u003eu003c|sound_0212|u003eu003c|sound_0212|u003eu003c|sound_0158|u003eu003c|sound_0045|u003eu003c|sound_0177|u003eu003c|sound_0177|u003eu003c|sound_0088|u003eu003c|sound_0399|u003eu003c|sound_0268|u003eu003c|sound_0268|u003eu003c|sound_0129|u003eu003c|sound_0129|u003eu003c|sound_0129|u003eu003c|sound_0129|u003eu003c|sound_0308|u003eu003c|sound_0308|u003eu003c|sound_0439|u003eu003c|sound_0475|u003eu003c|sound_0463|u003eu003c|sound_0016|u003eu003c|sound_0016|u003eu003c|sound_0113|u003eu003c|sound_0113|u003eu003c|sound_0103|u003eu003c|sound_0436|u003eu003c|sound_0436|u003eu003c|sound_0118|u003eu003c|sound_0105|u003eu003c|sound_0444|u003eu003c|sound_0444|u003eu003c|sound_0444|u003eu003c|sound_0162|u003eu003c|sound_0162|u003eu003c|sound_0218|u003eu003c|sound_0162|u003eu003c|sound_0215|u003eu003c|sound_0351|u003eu003c|sound_0083|u003eu003c|sound_0083|u003eu003c|sound_0509|u003eu003c|sound_0268|u003eu003c|sound_0208|u003eu003c|sound_0193|u003eu003c|sound_0193|u003eu003c|sound_0485|u003eu003c|sound_0318|u003eu003c|sound_0318|u003eu003c|sound_0318|u003eu003c|sound_0221|u003eu003c|sound_0221|u003eu003c|sound_0260|u003eu003c|sound_0260|u003eu003c|sound_0164|u003eu003c|sound_0164|u003eu003c|sound_0140|u003eu003c|sound_0471|u003eu003c|sound_0471|u003eu003c|sound_0332|u003eu003c|sound_0393|u003eu003c|sound_0393|u003eu003c|sound_0010|u003eu003c|sound_0351|u003eu003c|sound_0083|u003eu003c|sound_0020|u003eu003c|sound_0083|u003eu003c|sound_0446|u003eu003c|sound_0446|u003eu003c|sound_0446|u003eu003c|sound_0091|u003eu003c|sound_0045|u003eu003c|sound_0446|u003eu003c|sound_0446|u003eu003c|sound_0446|u003eu003c|sound_0347|u003eu003c|sound_0376|u003eu003c|sound_0125|u003eu003c|sound_0349|u003eu003c|sound_0349|u003eu003c|sound_0174|u003eu003c|sound_0174|u003eu003c|sound_0494|u003eu003c|sound_0212|u003eu003c|sound_0212|u003eu003c|sound_0218|u003eu003c|sound_0212|u003eu003c|sound_0445|u003eu003c|sound_0445|u003eu003c|sound_0401|u003eu003c|sound_0262|u003eu003c|sound_0350|u003eu003c|sound_0177|u003eu003c|sound_0177|u003eu003c|sound_0113|u003eu003c|sound_0018|u003eu003c|sound_0018|u003eu003c|sound_0018|u003eu003c|sound_0321|u003eu003c|sound_0321|u003eu003c|sound_0482|u003eu003c|sound_0482|u003eu003c|sound_0482|u003eu003c|sound_0105|u003eu003c|sound_0366|u003eu003c|sound_0366|u003eu003c|sound_0141|u003eu003c|sound_0213|u003eu003c|sound_0213|u003eu003c|sound_0115|u003eu003c|sound_0187|u003eu003c|sound_0483|u003eu003c|sound_0483|u003eu003c|sound_0230|u003eu003c|sound_0118|u003eu003c|sound_0445|u003eu003c|sound_0007|u003eu003c|sound_0333|u003eu003c|sound_0141|u003eu003c|sound_0386|u003eu003c|sound_0323|u003eu003c|sound_0323|u003eu003c|sound_0031|u003eu003c|sound_0445|u003eu003c|sound_0445|u003eu003c|sound_0445|u003eu003c|sound_0045|u003eu003c|sound_0045|u003eu003c|sound_0416|u003eu003c|sound_0103|u003eu003c|sound_0476|u003eu003c|sound_0476|u003eu003c|sound_0476|u003eu003c|sound_0015|u003eu003c|sound_0015|u003eu003c|sound_0368|u003eu003c|sound_0368|u003eu003c|sound_0368|u003eu003c|sound_0291|u003eu003c|sound_0290|u003eu003c|sound_0290|u003eu003c|sound_0451|u003eu003c|sound_0453|u003eu003c|sound_0451|u003eu003c|sound_0322|u003eu003c|sound_0091|u003eu003c|sound_0091|u003eu003c|sound_0322|u003eu003c|sound_0091|u003eu003c|sound_0091|u003eu003c|sound_0371|u003eu003c|sound_0322|u003eu003c|sound_0168|u003eu003c|sound_0091|u003eu003c|sound_0322|u003eu003c|sound_0206|u003eu003c|sound_0486|u003eu003c|sound_0170|u003eu003c|sound_0389|u003eu003c|sound_0342|u003eu003c|sound_0314|u003eu003c|sound_0314|u003eu003c|sound_0285|u003eu003c|sound_0275|u003eu003c|sound_0384|u003eu003c|sound_0384|u003eu003c|sound_0143|u003eu003c|sound_0216|u003eu003c|sound_0393|u003eu003c|sound_0184|u003eu003c|sound_0445|u003eu003c|sound_0270|u003eu003c|sound_0141|u003eu003c|sound_0141|u003eu003c|sound_0020|u003eu003c|sound_0020|u003eu003c|sound_0315|u003eu003c|sound_0315|u003eu003c|sound_0387|u003eu003c|sound_0163|u003eu003c|sound_0475|u003eu003c|sound_0254|u003eu003c|sound_0298|u003eu003c|sound_0298|u003eu003c|sound_0230|u003eu003c|sound_0110|u003eu003c|sound_0110|u003eu003c|sound_0110|u003eu003c|sound_0110|u003eu003c|sound_0257|u003eu003c|sound_0474|u003eu003c|sound_0282|u003eu003c|sound_0395|u003eu003c|sound_0395|u003eu003c|sound_0346|u003eu003c|sound_0105|u003eu003c|sound_010