BEE-spoke-data/gutenberg-en-v1-clean
收藏Hugging Face2024-05-12 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/BEE-spoke-data/gutenberg-en-v1-clean
下载链接
链接失效反馈官方服务:
资源简介:
---
license: odc-by
task_categories:
- text-generation
dataset_info:
- config_name: default
features:
- name: text
dtype: string
- name: score
dtype: float64
- name: sha256
dtype: string
- name: word_count
dtype: int64
splits:
- name: train
num_bytes: 3368495537.116657
num_examples: 9930
- name: validation
num_bytes: 194379156.4860627
num_examples: 571
- name: test
num_bytes: 188763796.8902655
num_examples: 563
download_size: 2241829581
dataset_size: 3751638490.492985
- config_name: raw
features:
- name: text
dtype: string
- name: label
dtype: string
- name: score
dtype: float64
- name: sha256
dtype: string
- name: word_count
dtype: int64
splits:
- name: train
num_bytes: 3444846235
num_examples: 9978
- name: validation
num_bytes: 198350533
num_examples: 574
- name: test
num_bytes: 193610734
num_examples: 565
download_size: 2332500435
dataset_size: 3836807502
- config_name: v1.0
features:
- name: text
dtype: string
- name: label
dtype: string
- name: score
dtype: float64
- name: sha256
dtype: string
- name: word_count
dtype: int64
splits:
- name: train
num_bytes: 3384868097
num_examples: 9978
- name: validation
num_bytes: 195405579
num_examples: 574
- name: test
num_bytes: 189439446
num_examples: 565
download_size: 2317475462
dataset_size: 3769713122
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
- config_name: raw
data_files:
- split: train
path: raw/train-*
- split: validation
path: raw/validation-*
- split: test
path: raw/test-*
- config_name: v1.0
data_files:
- split: train
path: v1.0/train-*
- split: validation
path: v1.0/validation-*
- split: test
path: v1.0/test-*
---
# gutenberg - clean
```yml
dataset_info:
- config_name: default
features:
- name: text
dtype: string
- name: label
dtype: string
- name: score
dtype: float64
- name: sha256
dtype: string
- name: word_count
dtype: int64
splits:
- name: train
num_bytes: 3384868097
num_examples: 9978
- name: validation
num_bytes: 195405579
num_examples: 574
- name: test
num_bytes: 189439446
num_examples: 565
download_size: 2317462261
dataset_size: 3769713122
```
## default config
has (mostly) fixed newlines vs. `v1.0`
TODO: more words
## v1.0
the v1.0 config has cleaned up whitespace:
```
{'label': 'clean',
'score': 0.8587704300880432,
'sha256': '4f45d16cbf81871d0ae27f99bd9a15ff83dfc5bb0010868c3b16f52638b579c7',
'word_count': 10116}
A GOOD-FOR-NOTHING
By Hjalmar Hjorth Boyesen
By permission of Charles Scribner's Sons.
Copyright, 1876, by James R. Osgood & Co
I
Ralph Grimm was born a gentleman, He had the misfortune of coming into
the world some ten years later than might reasonably have been expected.
Colonel Grim and his lady had celebrated twelve anniversaries of their
wedding-day, and had given up all hopes of ever having a son and heir,
when this late comer startled them by his unexpected appearance. The
only previous addition to the family had been a daughter, and she was
then ten summers old.
Ralph was a very feeble child, and could only with great difficulty be
persuaded to retain his hold of the slender thread which bound him to
existence. He was rubbed with whiskey, and wrapped in cotton, and given
mare's milk to drink, and God knows what not, and the Colonel swore a
round oath of paternal delight when at last the infant stopped gasping
in that distressing way and began to breathe like other human b
```
> in the above, you may notice that all lines are actually hard-wrapped (it is not just for display). this is now mostly fixed in the default
## 'raw' config
some examples will look like:
```
{'label': 'clean',
'score': 0.6050848364830017,
'sha256': '02da96e0ca0beae1a3bd8919f04a775849393d730a307b451a8a82a9c012e086',
'word_count': 81683}
Hutchinson and PG Distributed Proofreaders
ATLANTIC MONTHLY.
A MAGAZINE OF LITERATURE, ART, AND POLITICS.
VOL. V.--JUNE, 1860. NO. XXXII.
THE FUTURE OF AMERICAN RAILWAYS.
The condition of our railways, and their financial prospects, should
interest all of us. It has become a common remark, that railways have
benefited everybody but their projectors. There is a strong doubt in the
minds of many intelligent persons, whether _any_ railways have actually
paid a return on the capital invested in them. It is believed that one of
two results inevitably takes place: in the one case, there is not business
enough to earn a dividend; in the other, although the apparent net earnings
are large enough to pay from six to eight per cent. on the cost, yet in a
few years it is discovered that the machine has been wearing itself out so
fast that the cost of renewal has absorbed more than the earnings, and the
deficiency has been made up by creating new capital or running in debt, to
```
许可证:odc-by
任务类别:
- 文本生成(text-generation)
数据集信息:
- 配置名:default
特征:
- 名称:text,数据类型:字符串(string)
- 名称:score,数据类型:64位浮点数(float64)
- 名称:sha256,数据类型:字符串(string)
- 名称:word_count,数据类型:64位整数(int64)
数据集划分:
- 名称:训练集(train),字节数:3368495537.116657,样本数:9930
- 名称:验证集(validation),字节数:194379156.4860627,样本数:571
- 名称:测试集(test),字节数:188763796.8902655,样本数:563
下载大小:2241829581,数据集总大小:3751638490.492985
- 配置名:raw
特征:
- 名称:text,数据类型:字符串(string)
- 名称:label,数据类型:字符串(string)
- 名称:score,数据类型:64位浮点数(float64)
- 名称:sha256,数据类型:字符串(string)
- 名称:word_count,数据类型:64位整数(int64)
数据集划分:
- 名称:训练集,字节数:3444846235,样本数:9978
- 名称:验证集,字节数:198350533,样本数:574
- 名称:测试集,字节数:193610734,样本数:565
下载大小:2332500435,数据集总大小:3836807502
- 配置名:v1.0
特征:
- 名称:text,数据类型:字符串(string)
- 名称:label,数据类型:字符串(string)
- 名称:score,数据类型:64位浮点数(float64)
- 名称:sha256,数据类型:字符串(string)
- 名称:word_count,数据类型:64位整数(int64)
数据集划分:
- 名称:训练集,字节数:3384868097,样本数:9978
- 名称:验证集,字节数:195405579,样本数:574
- 名称:测试集,字节数:189439446,样本数:565
下载大小:2317475462,数据集总大小:3769713122
配置项:
- 配置名:default,数据文件:
- 划分:训练集,路径:data/train-*
- 划分:验证集,路径:data/validation-*
- 划分:测试集,路径:data/test-*
- 配置名:raw,数据文件:
- 划分:训练集,路径:raw/train-*
- 划分:验证集,路径:raw/validation-*
- 划分:测试集,路径:raw/test-*
- 配置名:v1.0,数据文件:
- 划分:训练集,路径:v1.0/train-*
- 划分:验证集,路径:v1.0/validation-*
- 划分:测试集,路径:v1.0/test-*
# 古腾堡(Gutenberg)- 清洗版
yml
dataset_info:
- config_name: default
features:
- name: text
dtype: string
- name: label
dtype: string
- name: score
dtype: float64
- name: sha256
dtype: string
- name: word_count
dtype: int64
splits:
- name: train
num_bytes: 3384868097
num_examples: 9978
- name: validation
num_bytes: 195405579
num_examples: 574
- name: test
num_bytes: 189439446
num_examples: 565
download_size: 2317462261
dataset_size: 3769713122
## 默认配置
相较于v1.0配置,该配置已(基本)修复换行问题。
待办事项:补充更多说明文本。
## v1.0 配置
v1.0配置已优化空白字符处理:
{'label': 'clean',
'score': 0.8587704300880432,
'sha256': '4f45d16cbf81871d0ae27f99bd9a15ff83dfc5bb0010868c3b16f52638b579c7',
'word_count': 10116}
> **《一无是处的家伙》**
> 作者:Hjalmar Hjorth Boyesen
> 经Charles Scribner's Sons许可转载
> 版权所有©1876,James R. Osgood & Co
>
> 第一章
> 拉尔夫·格里姆生来便是绅士。可不幸的是,他来到世上的时间比预期晚了整整十年。格里姆上校与夫人已经庆祝了十二次结婚周年纪念日,早已放弃了拥有子嗣继承人的希望,直到这位迟来的访客以意料之外的降生让他们惊喜万分。这个家庭此前唯一的新成员是一个女儿,当时她已经年满十岁。
>
> 拉尔夫是个体弱多病的婴孩,仅能勉强维系住连接生命的纤细丝线。人们用威士忌擦拭他的身体,以棉布包裹保暖,投喂母奶,天知道还用过多少偏方。当这个婴儿终于不再痛苦地喘息,开始像常人一样平稳呼吸时,上校激动地许下了为人父的喜悦誓言。(原文此处截断)
> 在上文示例中,你可观察到所有文本行均为硬换行(并非仅为展示效果)。该问题在默认配置中已基本修复。
## raw 配置
部分示例样式如下:
{'label': 'clean',
'score': 0.6050848364830017,
'sha256': '02da96e0ca0beae1a3bd8919f04a775849393d730a307b451a8a82a9c012e086',
'word_count': 81683}
Hutchinson and PG Distributed Proofreaders
ATLANTIC MONTHLY.
A MAGAZINE OF LITERATURE, ART, AND POLITICS.
VOL. V.--JUNE, 1860. NO. XXXII.
THE FUTURE OF AMERICAN RAILWAYS.
The condition of our railways, and their financial prospects, should
interest all of us. It has become a common remark, that railways have
benefited everybody but their projectors. There is a strong doubt in the
minds of many intelligent persons, whether _any_ railways have actually
paid a return on the capital invested in them. It is believed that one of
two results inevitably takes place: in the one case, there is not business
enough to earn a dividend; in the other, although the apparent net earnings
are large enough to pay from six to eight per cent. on the cost, yet in a
few years it is discovered that the machine has been wearing itself out so
fast that the cost of renewal has absorbed more than the earnings, and the
deficiency has been made up by creating new capital or running in debt, to
提供机构:
BEE-spoke-data
原始信息汇总
数据集概述
许可证
- 许可证类型:odc-by
任务类别
- 文本生成
数据集配置
配置名称:default
- 特征:
- text: string
- score: float64
- sha256: string
- word_count: int64
- 分割:
- train:
- 字节数: 3368495537.116657
- 样本数: 9930
- validation:
- 字节数: 194379156.4860627
- 样本数: 571
- test:
- 字节数: 188763796.8902655
- 样本数: 563
- train:
- 下载大小: 2241829581
- 数据集大小: 3751638490.492985
配置名称:raw
- 特征:
- text: string
- label: string
- score: float64
- sha256: string
- word_count: int64
- 分割:
- train:
- 字节数: 3444846235
- 样本数: 9978
- validation:
- 字节数: 198350533
- 样本数: 574
- test:
- 字节数: 193610734
- 样本数: 565
- train:
- 下载大小: 2332500435
- 数据集大小: 3836807502
配置名称:v1.0
- 特征:
- text: string
- label: string
- score: float64
- sha256: string
- word_count: int64
- 分割:
- train:
- 字节数: 3384868097
- 样本数: 9978
- validation:
- 字节数: 195405579
- 样本数: 574
- test:
- 字节数: 189439446
- 样本数: 565
- train:
- 下载大小: 2317475462
- 数据集大小: 3769713122
数据文件路径
配置名称:default
- 训练集: data/train-*
- 验证集: data/validation-*
- 测试集: data/test-*
配置名称:raw
- 训练集: raw/train-*
- 验证集: raw/validation-*
- 测试集: raw/test-*
配置名称:v1.0
- 训练集: v1.0/train-*
- 验证集: v1.0/validation-*
- 测试集: v1.0/test-*
搜集汇总
数据集介绍
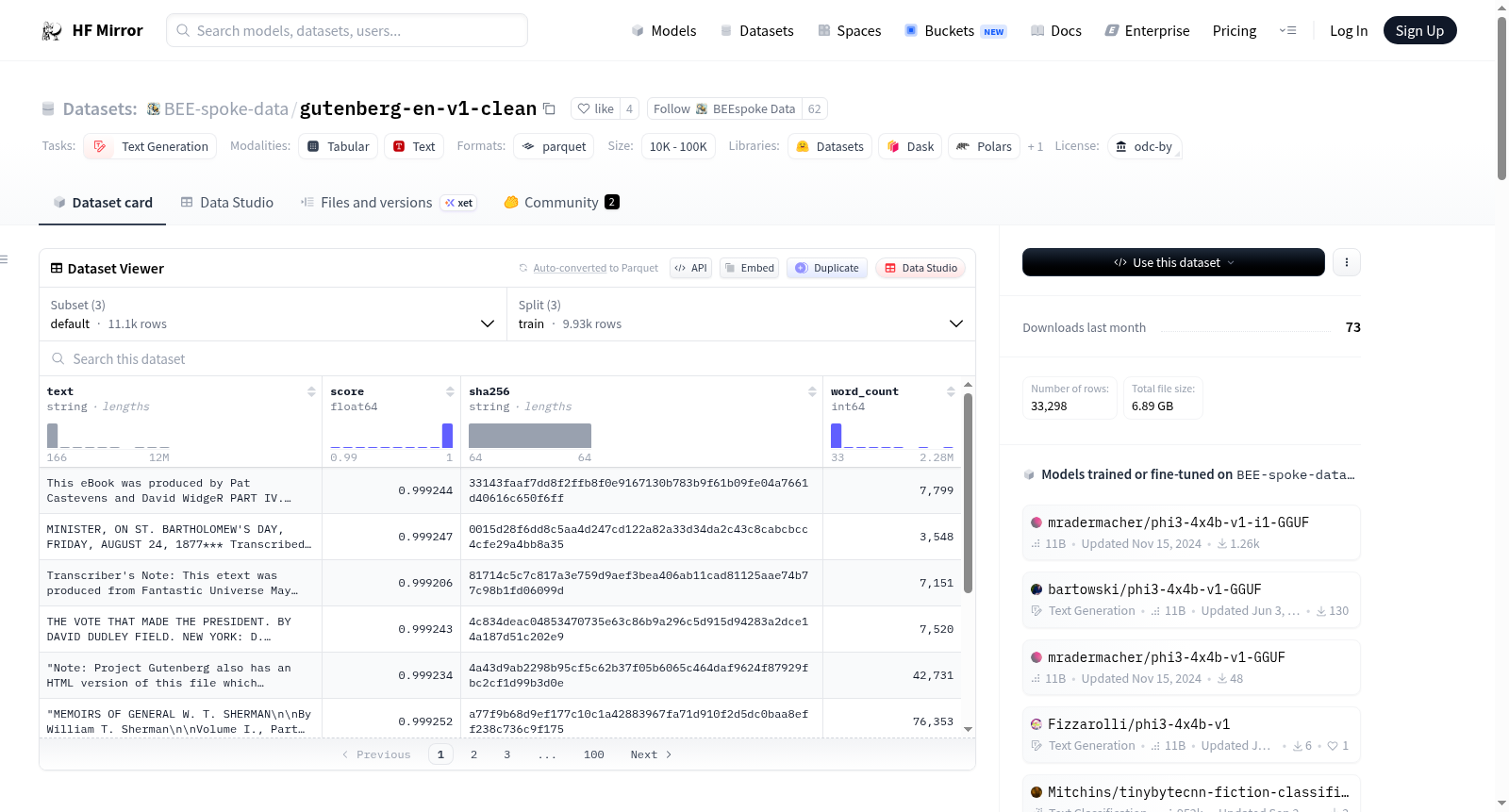
构建方式
在数字人文与自然语言处理领域,高质量文本语料的构建是推动模型训练与评估的关键。BEE-spoke-data/gutenberg-en-v1-clean数据集源自古登堡计划,通过系统化的清洗流程精炼而成。原始文本经过自动化处理,移除了冗余的元数据、格式化标记以及非标准空白字符,确保了内容的纯净性与一致性。该数据集提供了三种配置版本,包括默认配置、原始配置及v1.0配置,每种配置均经过严格的分割,划分为训练集、验证集与测试集,并附带文本质量评分、哈希校验及词数统计等元数据,为研究者提供了可靠的结构化语料基础。
特点
该数据集在文学与语言学研究领域展现出独特价值,其核心特征在于文本的深度清洗与多维度标注。每一文本样本均附有质量评分,反映了内容的可读性与完整性,便于用户根据需求筛选高置信度语料。哈希值字段确保了数据的完整性与可追溯性,有效支持了版本控制与重复检测。此外,数据集涵盖小说、散文等多种文学体裁,语言风格典雅丰富,为语言模型训练提供了多样化的语境素材。其分版本设计允许用户灵活选择原始或优化后的文本格式,适应不同预处理需求,增强了数据集的实用性与适应性。
使用方法
在文本生成与语言建模任务中,该数据集可直接应用于模型训练与评估。用户可通过HuggingFace平台加载指定配置,如默认配置或v1.0配置,获取已分割的训练、验证与测试子集。文本字段可直接输入至生成模型进行预训练或微调,而质量评分与词数统计可用于样本加权或数据过滤,优化训练效果。对于研究场景,哈希值支持数据完整性验证,确保实验的可复现性。数据集兼容主流深度学习框架,用户可依据任务需求,结合元数据字段进行定制化处理,例如构建基于评分的分层抽样或跨版本对比分析,以深化语言模型的性能探索。
背景与挑战
背景概述
在自然语言处理领域,高质量文本语料库的构建对于推动语言模型的发展至关重要。BEE-spoke-data/gutenberg-en-v1-clean数据集基于古登堡计划这一历史悠久的数字图书馆资源,由相关研究团队精心整理而成,旨在为文本生成任务提供纯净、结构化的英文语料。该数据集的核心研究问题聚焦于如何从海量公共领域文献中提取并标准化文本数据,以支持现代机器学习模型的训练与评估。其创建不仅延续了古登堡计划在文化遗产数字化方面的贡献,更为语言模型的预训练与微调提供了可靠的基础资源,对促进生成式人工智能技术的进步具有显著影响力。
当前挑战
该数据集致力于解决文本生成领域中高质量训练数据稀缺的挑战,尤其在处理历史文献时,需克服文本格式不一致、噪声干扰以及语言风格变迁等问题。构建过程中的主要挑战包括:原始文本中的硬换行符、多余空白字符以及非标准排版结构的清理与规范化;同时,在保持文本语义完整性的前提下,有效过滤低质量或无关内容,确保数据纯净度。此外,数据集的版本管理也面临挑战,需平衡不同配置间的兼容性与优化改进,以维护数据的一致性与可用性。
常用场景
经典使用场景
在自然语言处理领域,大规模文本语料库是训练语言模型的基础资源。BEE-spoke-data/gutenberg-en-v1-clean数据集源自古登堡计划,收录了经过清洗和评分的英文文学作品,其经典使用场景在于为生成式预训练模型提供高质量的训练数据。该数据集通过严格的文本筛选和格式化处理,确保了语料的连贯性与规范性,使得研究人员能够基于这些纯净文本,有效训练和评估语言模型的生成能力、风格模仿及语义理解等核心任务。
实际应用
在实际应用中,该数据集被广泛用于开发智能写作助手、文学创作工具以及教育领域的语言学习系统。基于其纯净的文学文本,企业可以训练模型生成连贯的叙事内容,辅助作者进行创意写作或自动生成报告。同时,在数字人文研究中,该数据集支持文本风格分析、作者识别和历史语言变迁研究,为文化遗产的数字化保存与智能检索提供了关键数据支撑。
衍生相关工作
围绕该数据集,衍生了一系列经典研究工作。例如,基于其文本训练的开源语言模型被用于探索生成式人工智能的伦理边界和可控性。在学术领域,该数据集常作为基准,推动了如GPT系列模型在文学风格迁移、文本摘要和对话生成等任务的性能评估。此外,相关研究还聚焦于利用评分机制优化数据选择策略,为低资源语言模型的预训练提供了方法论借鉴。
以上内容由遇见数据集搜集并总结生成


