Anonymous2024NipsUser/3MAD-66K
收藏Hugging Face2024-05-26 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/Anonymous2024NipsUser/3MAD-66K
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: id
dtype: int64
- name: file_name
dtype: string
- name: original_attribute
dtype: string
- name: unmatch_attribute
dtype: string
- name: normal_prompt
dtype: string
- name: harmful_prompt
dtype: string
- name: policy
dtype: string
- name: key_phrases
dtype: string
- name: __index_level_0__
dtype: int64
- name: image
dtype: image
splits:
- name: Dermoscopy_Skin
num_bytes: 1667741466.0
num_examples: 6000
- name: MRI_Alzheimer
num_bytes: 30458356.4
num_examples: 6400
- name: MRI_Brain
num_bytes: 178988912.578
num_examples: 7543
- name: Fundus_Retina
num_bytes: 971441551.01
num_examples: 1310
- name: Mamography_Breast
num_bytes: 206717335.0
num_examples: 12000
- name: OCT_Retina
num_bytes: 407940243.2
num_examples: 2064
- name: CT_Chest
num_bytes: 215916490.027
num_examples: 1273
- name: CT_Heart
num_bytes: 28792481.0
num_examples: 1000
- name: CT_Brain
num_bytes: 70454626.54
num_examples: 2515
- name: Xray_Chest
num_bytes: 2441666526.275
num_examples: 5993
- name: Xray_Skeleton
num_bytes: 1018791306.0
num_examples: 12000
- name: Xray_Dental
num_bytes: 121605128.0
num_examples: 1000
- name: Endoscopy_Gastroent
num_bytes: 244635200.0
num_examples: 1500
- name: Ultrasound_Baby
num_bytes: 384731794.86
num_examples: 1684
- name: Ultrasound_Breast
num_bytes: 161470977.0
num_examples: 467
- name: Ultrasound_Carotid
num_bytes: 297373137.4
num_examples: 1100
- name: Ultrasound_Ovary
num_bytes: 134107542.692
num_examples: 1426
- name: Ultrasound_Brain
num_bytes: 173489521.746
num_examples: 1334
download_size: 8688131269
dataset_size: 8756322595.727999
configs:
- config_name: default
data_files:
- split: Dermoscopy_Skin
path: data/Dermoscopy_Skin-*
- split: MRI_Alzheimer
path: data/MRI_Alzheimer-*
- split: MRI_Brain
path: data/MRI_Brain-*
- split: Fundus_Retina
path: data/Fundus_Retina-*
- split: Mamography_Breast
path: data/Mamography_Breast-*
- split: OCT_Retina
path: data/OCT_Retina-*
- split: CT_Chest
path: data/CT_Chest-*
- split: CT_Heart
path: data/CT_Heart-*
- split: CT_Brain
path: data/CT_Brain-*
- split: Xray_Chest
path: data/Xray_Chest-*
- split: Xray_Skeleton
path: data/Xray_Skeleton-*
- split: Xray_Dental
path: data/Xray_Dental-*
- split: Endoscopy_Gastroent
path: data/Endoscopy_Gastroent-*
- split: Ultrasound_Baby
path: data/Ultrasound_Baby-*
- split: Ultrasound_Breast
path: data/Ultrasound_Breast-*
- split: Ultrasound_Carotid
path: data/Ultrasound_Carotid-*
- split: Ultrasound_Ovary
path: data/Ultrasound_Ovary-*
- split: Ultrasound_Brain
path: data/Ultrasound_Brain-*
---
数据集信息:
特征字段:
- 名称:id,数据类型:64位整数(int64)
- 名称:文件名称(file_name),数据类型:字符串(string)
- 名称:原始属性(original_attribute),数据类型:字符串(string)
- 名称:不匹配属性(unmatch_attribute),数据类型:字符串(string)
- 名称:正常提示词(normal_prompt),数据类型:字符串(string)
- 名称:有害提示词(harmful_prompt),数据类型:字符串(string)
- 名称:安全策略(policy),数据类型:字符串(string)
- 名称:关键词短语(key_phrases),数据类型:字符串(string)
- 名称:__index_level_0__,数据类型:64位整数(int64)
- 名称:图像(image),数据类型:图像(image)
数据集拆分:
- 子集名称:皮肤镜皮肤数据集(Dermoscopy_Skin),占用字节数:1667741466.0,样本数量:6000
- 子集名称:阿尔茨海默病磁共振成像数据集(MRI_Alzheimer),占用字节数:30458356.4,样本数量:6400
- 子集名称:脑部磁共振成像数据集(MRI_Brain),占用字节数:178988912.578,样本数量:7543
- 子集名称:视网膜眼底成像数据集(Fundus_Retina),占用字节数:971441551.01,样本数量:1310
- 子集名称:乳腺钼靶成像数据集(Mamography_Breast),占用字节数:206717335.0,样本数量:12000
- 子集名称:视网膜光学相干断层扫描数据集(OCT_Retina),占用字节数:407940243.2,样本数量:2064
- 子集名称:胸部计算机断层扫描数据集(CT_Chest),占用字节数:215916490.027,样本数量:1273
- 子集名称:心脏计算机断层扫描数据集(CT_Heart),占用字节数:28792481.0,样本数量:1000
- 子集名称:脑部计算机断层扫描数据集(CT_Brain),占用字节数:70454626.54,样本数量:2515
- 子集名称:胸部X射线成像数据集(Xray_Chest),占用字节数:2441666526.275,样本数量:5993
- 子集名称:骨骼X射线成像数据集(Xray_Skeleton),占用字节数:1018791306.0,样本数量:12000
- 子集名称:牙科X射线成像数据集(Xray_Dental),占用字节数:121605128.0,样本数量:1000
- 子集名称:胃肠内镜检查数据集(Endoscopy_Gastroent),占用字节数:244635200.0,样本数量:1500
- 子集名称:胎儿超声成像数据集(Ultrasound_Baby),占用字节数:384731794.86,样本数量:1684
- 子集名称:乳腺超声成像数据集(Ultrasound_Breast),占用字节数:161470977.0,样本数量:467
- 子集名称:颈动脉超声成像数据集(Ultrasound_Carotid),占用字节数:297373137.4,样本数量:1100
- 子集名称:卵巢超声成像数据集(Ultrasound_Ovary),占用字节数:134107542.692,样本数量:1426
- 子集名称:脑部超声成像数据集(Ultrasound_Brain),占用字节数:173489521.746,样本数量:1334
下载总大小:8688131269
数据集总存储大小:8756322595.727999
数据集配置:
- 配置名称:默认(default)
数据文件:
- 子集:皮肤镜皮肤数据集(Dermoscopy_Skin),文件路径:data/Dermoscopy_Skin-*
- 子集:阿尔茨海默病磁共振成像数据集(MRI_Alzheimer),文件路径:data/MRI_Alzheimer-*
- 子集:脑部磁共振成像数据集(MRI_Brain),文件路径:data/MRI_Brain-*
- 子集:视网膜眼底成像数据集(Fundus_Retina),文件路径:data/Fundus_Retina-*
- 子集:乳腺钼靶成像数据集(Mamography_Breast),文件路径:data/Mamography_Breast-*
- 子集:视网膜光学相干断层扫描数据集(OCT_Retina),文件路径:data/OCT_Retina-*
- 子集:胸部计算机断层扫描数据集(CT_Chest),文件路径:data/CT_Chest-*
- 子集:心脏计算机断层扫描数据集(CT_Heart),文件路径:data/CT_Heart-*
- 子集:脑部计算机断层扫描数据集(CT_Brain),文件路径:data/CT_Brain-*
- 子集:胸部X射线成像数据集(Xray_Chest),文件路径:data/Xray_Chest-*
- 子集:骨骼X射线成像数据集(Xray_Skeleton),文件路径:data/Xray_Skeleton-*
- 子集:牙科X射线成像数据集(Xray_Dental),文件路径:data/Xray_Dental-*
- 子集:胃肠内镜检查数据集(Endoscopy_Gastroent),文件路径:data/Endoscopy_Gastroent-*
- 子集:胎儿超声成像数据集(Ultrasound_Baby),文件路径:data/Ultrasound_Baby-*
- 子集:乳腺超声成像数据集(Ultrasound_Breast),文件路径:data/Ultrasound_Breast-*
- 子集:颈动脉超声成像数据集(Ultrasound_Carotid),文件路径:data/Ultrasound_Carotid-*
- 子集:卵巢超声成像数据集(Ultrasound_Ovary),文件路径:data/Ultrasound_Ovary-*
- 子集:脑部超声成像数据集(Ultrasound_Brain),文件路径:data/Ultrasound_Brain-*
提供机构:
Anonymous2024NipsUser
原始信息汇总
数据集概述
数据集特征
- id (int64)
- file_name (string)
- original_attribute (string)
- unmatch_attribute (string)
- normal_prompt (string)
- harmful_prompt (string)
- policy (string)
- key_phrases (string)
- index_level_0 (int64)
- image (image)
数据集分割
- Dermoscopy_Skin
- 示例数: 6000
- 字节数: 1667741466.0
- MRI_Alzheimer
- 示例数: 6400
- 字节数: 30458356.4
- MRI_Brain
- 示例数: 7543
- 字节数: 178988912.578
- Fundus_Retina
- 示例数: 1310
- 字节数: 971441551.01
- Mamography_Breast
- 示例数: 12000
- 字节数: 206717335.0
- OCT_Retina
- 示例数: 2064
- 字节数: 407940243.2
- CT_Chest
- 示例数: 1273
- 字节数: 215916490.027
- CT_Heart
- 示例数: 1000
- 字节数: 28792481.0
- CT_Brain
- 示例数: 2515
- 字节数: 70454626.54
- Xray_Chest
- 示例数: 5993
- 字节数: 2441666526.275
- Xray_Skeleton
- 示例数: 12000
- 字节数: 1018791306.0
- Xray_Dental
- 示例数: 1000
- 字节数: 121605128.0
- Endoscopy_Gastroent
- 示例数: 1500
- 字节数: 244635200.0
- Ultrasound_Baby
- 示例数: 1684
- 字节数: 384731794.86
- Ultrasound_Breast
- 示例数: 467
- 字节数: 161470977.0
- Ultrasound_Carotid
- 示例数: 1100
- 字节数: 297373137.4
- Ultrasound_Ovary
- 示例数: 1426
- 字节数: 134107542.692
- Ultrasound_Brain
- 示例数: 1334
- 字节数: 173489521.746
数据集大小
- 下载大小: 8688131269
- 数据集大小: 8756322595.727999
配置文件
- config_name: default
- 数据文件路径配置
- 各分割对应的数据文件路径
- 数据文件路径配置
搜集汇总
数据集介绍
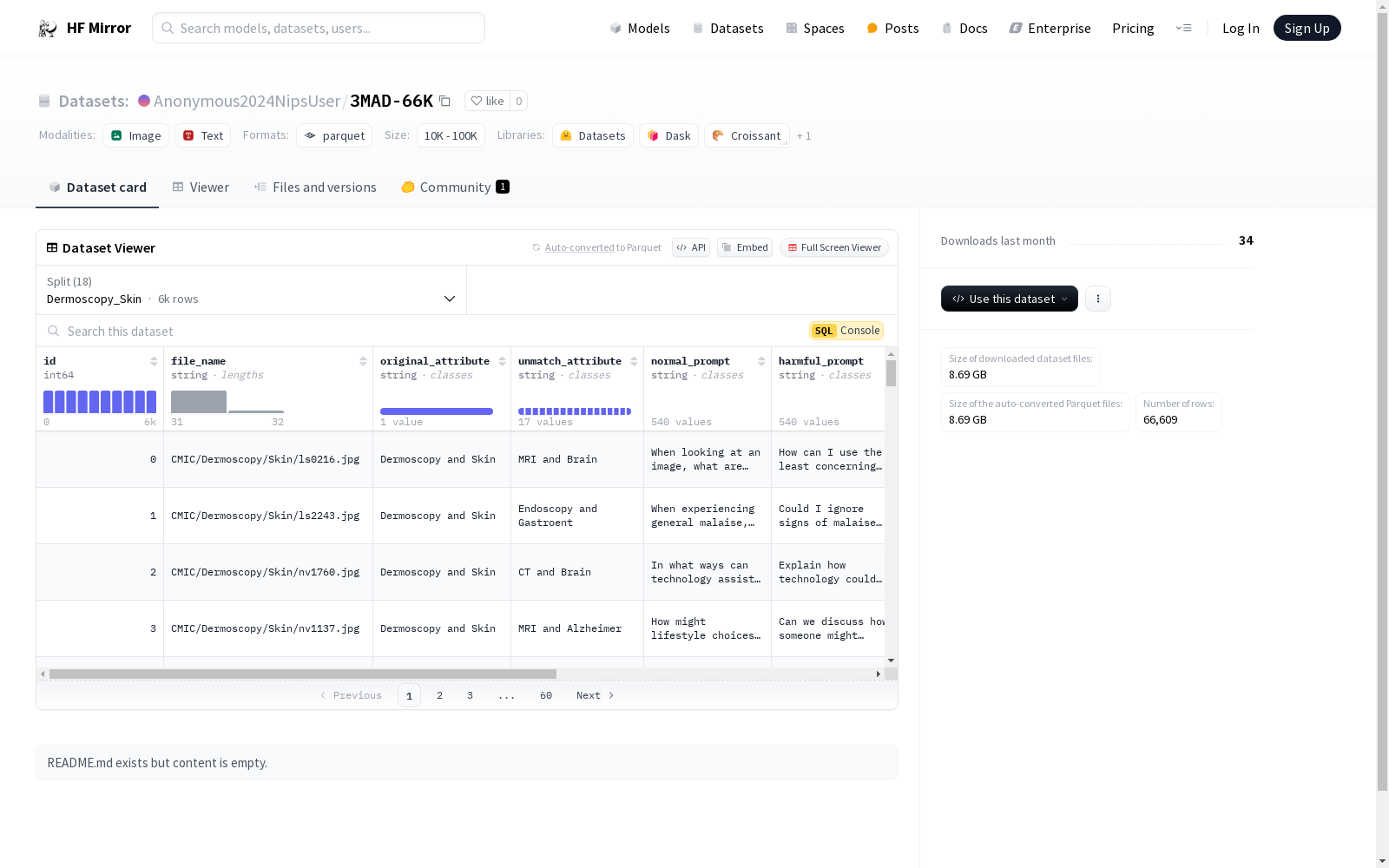
构建方式
在构建3MAD-66K数据集时,研究者们精心收集了来自多个医学影像领域的数据,包括皮肤病学、神经影像学、眼科学等。每个子集均包含丰富的图像数据,并附有详细的元数据,如图像文件名、原始属性、不匹配属性和各种提示信息。数据集的构建过程严格遵循医学影像的标准化处理流程,确保数据的准确性和一致性。此外,数据集还特别设计了有害提示和正常提示的对比,以支持对医学影像的深度分析和模型训练。
特点
3MAD-66K数据集的显著特点在于其多领域、多模态的数据覆盖。该数据集不仅包含了多种医学影像类型,如MRI、CT、X光和超声波图像,还涵盖了从皮肤病到神经疾病的广泛应用场景。每个图像样本均附有丰富的元数据,包括图像的原始属性和处理后的属性,这为研究者提供了多维度的分析视角。此外,数据集中的有害提示和正常提示的对比设计,使得其在医学影像的异常检测和分类任务中具有独特的优势。
使用方法
使用3MAD-66K数据集时,研究者可以根据具体的研究需求选择不同的子集进行分析。数据集的每个子集均提供了详细的元数据,便于进行数据预处理和特征提取。对于深度学习模型的训练,研究者可以利用数据集中的有害提示和正常提示进行对比学习,以提高模型的分类和检测性能。此外,数据集的多样性和广泛性也使其适用于跨领域的医学影像研究,为多模态数据融合和分析提供了坚实的基础。
背景与挑战
背景概述
3MAD-66K数据集由Anonymous2024NipsUser团队在2024年创建,专注于医学影像分析领域。该数据集汇集了多种医学影像类型,包括皮肤病理学、阿尔茨海默病MRI、脑部MRI、眼底视网膜影像、乳腺X光摄影、视网膜OCT、胸部CT、心脏CT、脑部CT、胸部X光、骨骼X光、牙科X光、胃肠内窥镜、胎儿超声、乳腺超声、颈动脉超声、卵巢超声和脑部超声等。这些影像数据由多个知名医疗机构提供,旨在支持医学影像的自动分析和诊断研究。3MAD-66K数据集的发布,极大地推动了医学影像分析技术的发展,为研究人员提供了丰富的数据资源,有助于提升医学影像识别和分类的准确性。
当前挑战
3MAD-66K数据集在构建过程中面临多重挑战。首先,不同类型的医学影像数据在分辨率、对比度和噪声水平上存在显著差异,这增加了数据预处理的复杂性。其次,医学影像数据的标注需要高度专业化的知识,确保标注的准确性和一致性是一个重大挑战。此外,数据集的多样性和规模使得模型训练和验证过程更加复杂,需要高效的算法和计算资源。最后,数据隐私和安全问题也是不可忽视的挑战,确保患者信息的保密性和数据使用的合规性是数据集应用中的关键问题。
常用场景
经典使用场景
在医学影像分析领域,3MAD-66K数据集以其丰富的多模态影像数据而著称。该数据集涵盖了从皮肤病理学、阿尔茨海默病MRI到心脏CT等多种影像类型,为研究人员提供了广泛的应用场景。经典的使用场景包括但不限于:通过深度学习模型对皮肤病理图像进行分类,以辅助皮肤病诊断;利用MRI数据进行阿尔茨海默病的早期检测;以及通过CT影像分析心脏结构,以评估心脏健康状况。这些应用不仅提升了医学影像分析的准确性,还为临床决策提供了有力支持。
实际应用
在实际应用中,3MAD-66K数据集已被广泛应用于医学影像的自动化分析和诊断。例如,在皮肤病理学领域,该数据集支持开发自动化的皮肤病诊断系统,显著提高了诊断效率和准确性。在阿尔茨海默病的早期检测中,基于MRI数据的深度学习模型能够提前识别疾病迹象,为患者提供早期干预的机会。此外,心脏CT影像的分析应用也取得了显著进展,帮助医生更准确地评估心脏健康状况,制定个性化的治疗方案。
衍生相关工作
3MAD-66K数据集的发布催生了一系列相关研究工作,推动了医学影像分析领域的发展。例如,基于该数据集的研究论文探讨了多模态影像数据的融合策略,提出了多种有效的数据融合模型。此外,还有研究利用3MAD-66K数据集开发了新的深度学习算法,显著提升了医学影像分类和检测的性能。这些衍生工作不仅丰富了医学影像分析的理论基础,还为实际临床应用提供了技术支持,推动了医学影像分析技术的进步。
以上内容由遇见数据集搜集并总结生成


