celeba-hq-256x256
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://huggingface.co/datasets/wittenator/celeba-hq-256x256
下载链接
链接失效反馈官方服务:
资源简介:
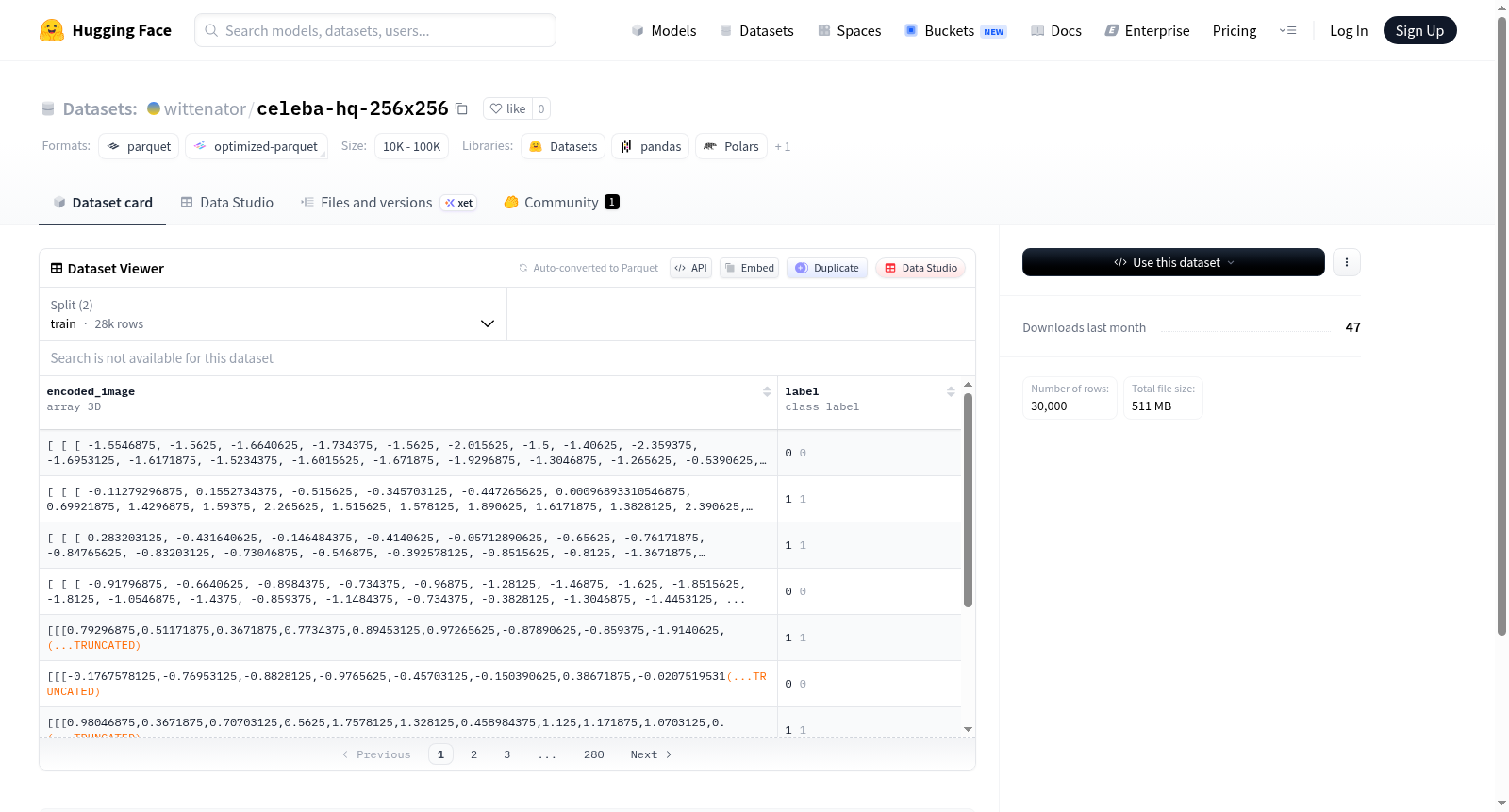
该数据集包含用于稳定扩散模型VAE(变分自编码器)训练的预处理数据,采用FP16精度优化。数据结构包含两个核心特征:1) encoded_image - 4通道的32×32浮点型三维数组,表示经过编码的图像数据;2) label - 二进制分类标签(0/1)。数据集分为28,000个训练样本(约473MB)和2,000个验证样本(约34MB),总大小约508MB。原始数据存储为分片文件形式,适用于图像生成模型的隐空间表示学习任务,特别是与SDXL(Stable Diffusion XL)架构相关的VAE训练。
创建时间:
2026-04-28
原始信息汇总
根据您提供的数据集详情页面内容,以下是该数据集的概述:
数据集名称
celeba-hq-256x256
数据集配置
- 配置名称:
madebyollin~sdxl-vae-fp16-fix
数据集特征
- encoded_image:类型为三维数组(
array3_d),形状为[4, 32, 32],数据类型为float32。 - label:类型为类别标签(
class_label),包含两个类别:0和1。
数据集划分
- 训练集(train):包含 28,000 个样本,占用 473,872,000 字节。
- 验证集(val):包含 2,000 个样本,占用 33,848,000 字节。
数据集大小
- 下载大小:510,843,343 字节(约 510.8 MB)
- 数据集总大小:507,720,000 字节(约 507.7 MB)
数据文件路径
- 训练集文件:
madebyollin~sdxl-vae-fp16-fix/train-* - 验证集文件:
madebyollin~sdxl-vae-fp16-fix/val-*
搜集汇总
数据集介绍
构建方式
CelebA-HQ-256x256数据集是基于大规模人脸属性数据集CelebA的高质量版本构建而成,通过精心筛选和超分辨率处理,保留了原数据集中约3万张明星人脸图像。在此基础上,数据集进一步采用预训练的SDXL VAE模型对图像进行编码压缩,将原始RGB图像转换为4通道的32x32潜空间特征表示,并保留了原始的二元标签信息。数据被划分为训练集(28000张)和验证集(2000张),以支持模型训练与评估。
使用方法
研究人员可通过HuggingFace Datasets库加载该数据集,指定配置名称为'madebyollin~sdxl-vae-fp16-fix',即可获取训练集与验证集的潜空间特征张量。在训练阶段,将编码后的图像特征输入到解码器或生成模型中,配合标签进行条件生成或分类学习。需要注意的是,该数据集不包含原始图像,使用前须确保具备对应的SDXL VAE解码器以重建像素空间图像。
背景与挑战
背景概述
CelebA-HQ-256x256数据集是由香港中文大学的研究团队在CelebA(CelebFaces Attributes Dataset)基础上进一步精细处理而成的高质量人脸图像数据集,创建于2018年左右。该数据集从CelebA的200K张人脸图像中精选并经过超高分辨率重建,最终生成了30,000张256×256像素的高清人脸图片,每张图像均带有40种属性标注(如发色、性别、是否戴眼镜等)。其核心研究问题集中在人脸属性编辑、生成对抗网络(GAN)的训练以及人脸图像超分辨率重建等领域。作为CelebA-HQ的衍生版本,该数据集为深度学习模型提供了兼具丰富属性标签与高清画质的人脸样本,极大地推动了人脸图像合成、属性编辑及图像生成等方向的研究进展,成为相关领域广泛使用的基准数据集之一。
当前挑战
该数据集所解决的领域挑战主要集中于高质量人脸图像的生成与属性编辑任务中,传统数据集常因图像分辨率低或标注不完整而制约模型性能,CelebA-HQ-256x256通过提供高清人脸样本及精细属性标签,为训练高保真度生成模型(如StyleGAN、VAE等)提供了标准化数据基础。在构建过程中,团队面临从低分辨率CelebA图像中恢复细节的挑战,需通过先进的超分辨率算法(如基于对抗学习的方法)确保生成图像的自然性与逼真度,同时避免伪影或失真;此外,在30,000张图像中保持属性标注的准确性,并平衡各属性类别的分布(如性别、种族多样性),以避免数据偏差对模型公平性的影响,也是构建过程中的关键难题。
常用场景
经典使用场景
CelebA-HQ-256x256数据集在人脸图像生成与编辑领域中被视为经典基准。该数据集精选自大规模名人面部数据集CelebA,并通过高分辨率处理与精细裁剪,提供了28,000张高质量、256x256像素的人脸图片,每张图片均附带经过编码的潜在特征表示与类别标签。研究者常将其用于训练生成对抗网络(GANs)与变分自编码器(VAEs),以探索面部细节的保真度与生成多样性的平衡,其潜在表征结构尤其适合作为扩散模型(如Stable Diffusion)的微调输入,促进高保真面部合成任务的推进。
解决学术问题
该数据集有效解决了学术研究中高分辨率人脸生成面临的两大核心挑战:图像质量的精细控制与多模态分布的一致性建模。借助其紧凑的潜在表示,研究人员得以规避原始像素空间的高维计算瓶颈,聚焦于语义层面的特征解耦与重组。这一特性显著推动了可控面部属性编辑、姿态迁移与年龄变换等任务的发展,为理解生成模型在结构化数据上的泛化能力提供了标准化的评估平台,深刻影响了计算机视觉与图形学交叉领域的研究范式。
实际应用
在实际应用中,CelebA-HQ-256x256推动了虚拟形象创作、智能娱乐与隐私保护领域的革新。例如,基于该数据集训练的生成模型可用于自动生成逼真的虚拟主播或游戏角色头像,极大降低美术资源制作成本。此外,其在隐私匿名化场景中展现出重要价值:通过生成替代的面部图像替换原始敏感数据,在保留视觉真实感的同时规避身份泄露风险,为社交媒体、数字营销等行业的隐私合规提供了技术支撑。
数据集最近研究
最新研究方向
CelebA-HQ-256x256数据集作为高清人脸图像的代表性资源,当前研究热点聚焦于利用其构建高质量潜在空间表示,尤其与稳定扩散(Stable Diffusion)等生成式模型的微调相结合。研究者通过SDXL-VAE等自编码器将图像编码为紧凑的32×32×4潜在特征,推动文本到图像生成、人脸属性编辑及高保真重建的前沿探索。该数据集在可控人脸合成、隐私保护领域的关键意义在于,其提供的均衡标签体系与高分辨率样本,为验证人脸生成模型的保真度与多样性提供了基准,并牵引着生成式人工智能在数字内容创作中的伦理与安全讨论。
以上内容由遇见数据集搜集并总结生成


