ECHR-generation-workshop
收藏Hugging Face2024-12-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ylkhayat/ECHR-generation-workshop
下载链接
链接失效反馈官方服务:
资源简介:
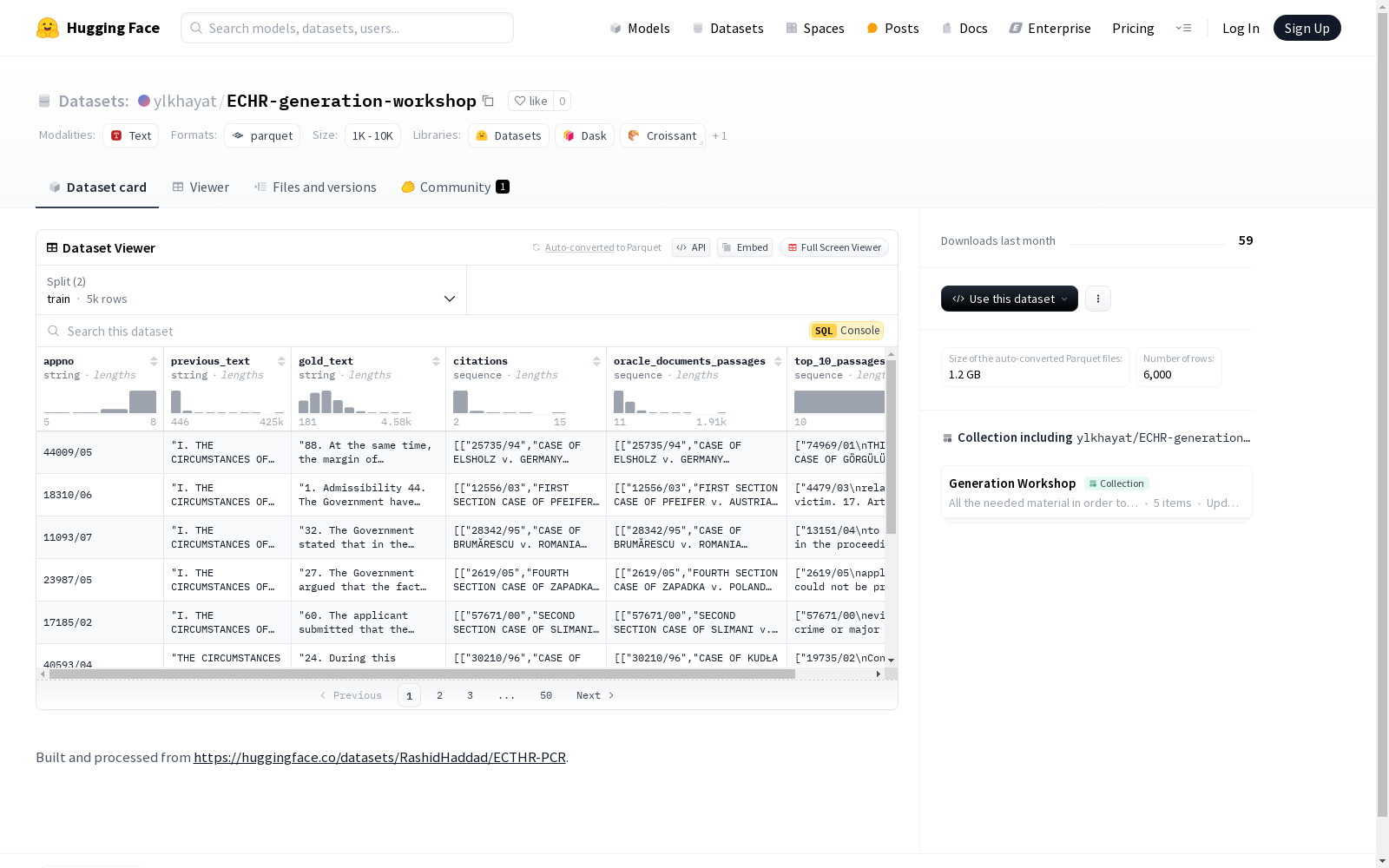
该数据集包含多个特征,如appno、previous_text、gold_text、citations、oracle_documents_passages和top_10_passages。每个特征都有其特定的数据类型。数据集分为训练集和测试集,分别包含5000和1000个样本。数据集的大小和下载大小也有明确记录。数据集的配置名为'default',包含训练和测试数据文件的路径。
创建时间:
2024-12-01
原始信息汇总
ECHR-generation-workshop 数据集概述
数据集信息
特征
- appno: 字符串类型
- previous_text: 字符串类型
- gold_text: 字符串类型
- citations: 字符串序列
- oracle_documents_passages: 字符串序列
- top_10_passages: 字符串序列
数据分割
- train:
- 样本数量: 5000
- 字节数: 2987963934
- test:
- 样本数量: 1000
- 字节数: 592084457
数据集大小
- 下载大小: 1283878279 字节
- 数据集总大小: 3580048391 字节
配置
- config_name: default
- data_files:
- train: bm25_relevant_passages_oracle_documents/train-*
- test: bm25_relevant_passages_oracle_documents/test-*
- data_files:
数据集来源
- 基于 RashidHaddad/ECTHR-PCR 构建和处理
搜集汇总
数据集介绍
构建方式
ECHR-generation-workshop数据集的构建基于欧洲人权法院(ECHR)的判例法,通过从RashidHaddad/ECTHR-PCR数据集进行处理和扩展而来。该数据集包含了多个关键特征,如案件编号(appno)、先前文本(previous_text)、黄金文本(gold_text)、引文(citations)、以及相关文档和段落的序列(oracle_documents_passages和top_10_passages)。数据集的构建过程中,采用了BM25算法来筛选相关段落,并将其分为训练集和测试集,分别包含5000和1000个样本。
特点
ECHR-generation-workshop数据集的显著特点在于其结构化的数据组织方式和丰富的法律文本信息。每个样本不仅包含案件的基本信息,还提供了详细的法律文本和相关引文,这为法律文本生成和分析提供了坚实的基础。此外,数据集通过BM25算法筛选出的相关段落,确保了数据的关联性和高质量,使其在法律领域的自然语言处理任务中具有较高的应用价值。
使用方法
ECHR-generation-workshop数据集适用于多种法律文本生成和分析任务。用户可以通过加载数据集的训练和测试部分,利用其中的案件编号、文本和引文信息进行模型训练和评估。特别地,数据集中的oracle_documents_passages和top_10_passages特征可以用于构建和优化法律文本检索系统。此外,该数据集还可用于法律文本摘要生成、法律问答系统等高级自然语言处理应用。
背景与挑战
背景概述
ECHR-generation-workshop数据集是由Rashid Haddad等人构建,专门用于欧洲人权法院(ECHR)案例文本生成的研究。该数据集的核心研究问题是如何从法律文本中自动生成相关的法律解释和判决摘要,这对于法律信息检索和自动化法律分析具有重要意义。数据集包含了案例编号、先前文本、黄金标准文本、引用、以及相关文档段落等特征,旨在支持法律文本生成模型的训练与评估。通过提供高质量的法律文本数据,该数据集为法律科技领域的发展提供了宝贵的资源,推动了法律文本自动化处理技术的进步。
当前挑战
ECHR-generation-workshop数据集在构建过程中面临多项挑战。首先,法律文本的复杂性和专业性要求数据集必须具备高度的准确性和权威性,以确保生成的文本符合法律规范。其次,数据集的构建需要处理大量的法律文档,从中提取有用的信息并进行结构化处理,这一过程涉及复杂的自然语言处理技术。此外,法律文本的多样性和变化性也为模型的训练带来了挑战,要求模型能够适应不同的法律场景和语言风格。最后,数据集的评估标准也是一个重要挑战,需要设计合理的评估指标来衡量生成文本的质量和法律准确性。
常用场景
经典使用场景
ECHR-generation-workshop数据集在法律文本生成领域中具有显著的应用价值。其经典使用场景主要体现在通过训练模型,自动生成与欧洲人权法院(ECHR)相关的法律文本,如判决书摘要或相关法律条文的解释。该数据集通过提供详细的案件编号(appno)、之前的文本(previous_text)、标准文本(gold_text)以及相关的引用和文档段落,使得模型能够学习如何从复杂的法律文档中提取关键信息并生成简洁、准确的文本。
解决学术问题
该数据集解决了法律文本生成中的多个学术研究问题,特别是在自动摘要和法律文本解释方面。通过提供结构化的法律文本和相关的引用信息,ECHR-generation-workshop数据集使得研究者能够开发出更高效、更准确的文本生成模型。这不仅有助于提高法律文本处理的自动化水平,还为法律领域的知识传播和普及提供了新的工具和方法。
衍生相关工作
基于ECHR-generation-workshop数据集,研究者们开发了多种法律文本生成模型,这些模型在多个法律文本生成任务中表现出色。例如,有研究利用该数据集训练的模型在法律文本摘要生成任务中取得了显著的成果。此外,该数据集还激发了在法律信息检索和法律知识图谱构建等领域的相关研究,推动了法律科技领域的整体发展。
以上内容由遇见数据集搜集并总结生成


