jainr3/diffusiondb-pixelart
收藏Hugging Face2023-05-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/jainr3/diffusiondb-pixelart
下载链接
链接失效反馈官方服务:
资源简介:
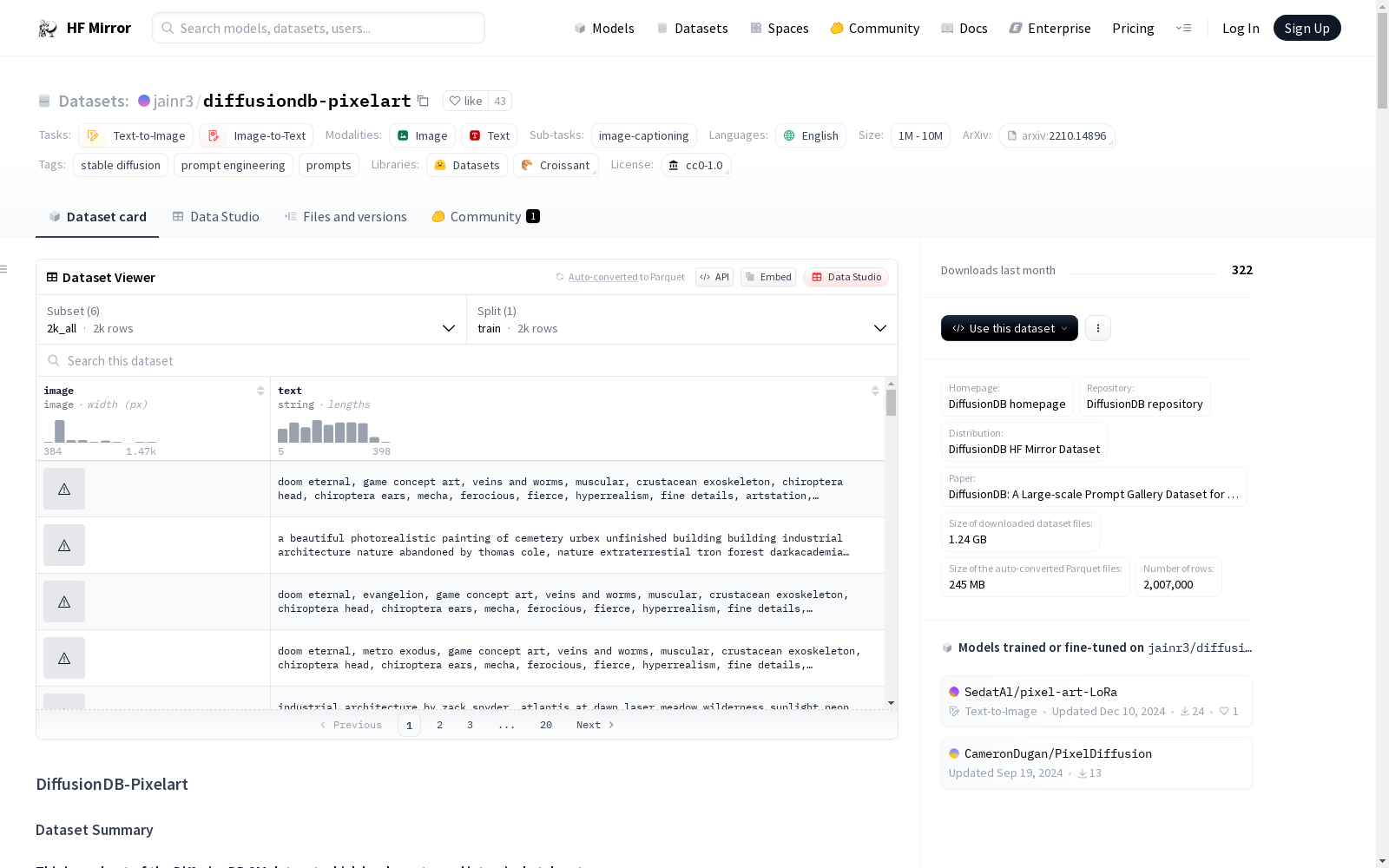
DiffusionDB-Pixelart是DiffusionDB 2M数据集的一个子集,包含了2000张像素风格的图像。这些图像是通过Stable Diffusion模型生成的,使用了真实用户提供的提示和超参数。数据集的主要目的是帮助研究人员理解文本到图像生成模型的提示与生成结果之间的关系,并支持相关研究任务。
DiffusionDB-Pixelart is a subset of the DiffusionDB 2M dataset, consisting of 2000 pixel-art style images. These images were generated using the Stable Diffusion model, with prompts and hyperparameters provided by real users. The primary goal of this dataset is to help researchers understand the relationship between prompts and generated results of text-to-image generation models, and to support relevant research tasks.
提供机构:
jainr3
原始信息汇总
DiffusionDB-Pixelart 数据集概述
数据集描述
数据集摘要
- 名称: DiffusionDB-Pixelart
- 类型: 像素风格艺术子集
- 来源: 从DiffusionDB 2M数据集中提取,包含2000个示例
- 内容: 包含1400万张由Stable Diffusion模型生成的图像,使用真实用户提供的提示和超参数
- 格式: 图像为PNG格式
支持的任务和排行榜
- 任务: 文本到图像生成、图像到文本
- 任务ID: image-captioning
- 应用: 研究提示与生成模型之间的交互、检测深度伪造、设计人机交互工具
语言
- 主要语言: 英语
- 其他语言: 西班牙语、中文、俄语
子集
- 子集名称: DiffusionDB-pixelart
- 图像数量: 2000
- 唯一提示数量: 约1500
- 大小: 约1.6GB
- 存储结构: 图像存储在
images/目录下,元数据存储在metadata.parquet文件中
数据集结构
数据实例
- 实例描述: 每个图像文件名与对应的提示和超参数存储在JSON文件中
- 示例: 图像
ec9b5e2c-028e-48ac-8857-a52814fd2a06.png及其在part-000001.json中的键值对
数据字段
- 键: 唯一图像名称
- p: 文本提示
数据集元数据
- 元数据表:
metadata.parquet - 格式: 列式存储,支持高效查询单个列
- 示例行: 包含图像名称、提示、部分ID、种子、步骤、配置、采样器、宽度、高度、用户名、时间戳、图像NSFW评分、提示NSFW评分
数据分割
- 分割方式: 2000张图像分割成多个文件夹,每个文件夹包含1000张图像和一个JSON文件
加载数据子集
- 方法: 使用Hugging Face Datasets Loader加载预定义的16个DiffusionDB子集
数据集创建
数据收集与规范化
- 来源: 从官方Stable Diffusion Discord服务器收集用户生成的图像
- 许可证: CC0 1.0 Universal Public Domain Dedication
个人和敏感信息
- 处理: 移除Discord用户名,匿名化处理以保护用户隐私
使用数据集的考虑
社会影响
- 目的: 帮助理解大型文本到图像生成模型
- 潜在风险: 可能包含未被NSFW过滤器检测到的有害图像
偏见讨论
- 数据源偏见: 数据来自早期使用Stable Diffusion的用户,可能不代表所有用户群体
其他已知限制
- 泛化性: 某些研究结果可能不适用于其他文本到图像生成模型
搜集汇总
数据集介绍
构建方式
DiffusionDB-Pixelart 数据集构建于 DiffusionDB 2M 数据集之上,该数据集包含了 14 万张由 Stable Diffusion 使用真实用户指定的文本提示和超参数生成的图像。为了生成 DiffusionDB-Pixelart,研究人员将这些图像转换为像素艺术风格,并从中抽取了 2000 个样本,以适应不同的研究需求。数据集采用了模块化文件结构,将图像和提示信息以 JSON 格式存储,方便用户快速加载和使用。
特点
DiffusionDB-Pixelart 数据集具有以下特点:1)规模庞大,包含 2000 张像素艺术风格的图像;2)文本提示多样,涵盖了多种语言,包括英语、西班牙语、中文和俄语;3)数据结构清晰,图像和提示信息以 JSON 格式存储,方便用户快速加载和使用;4)包含元数据信息,如图像名称、文本提示、种子、步数、配置参数、采样器等,方便用户进行进一步的分析和研究。
使用方法
用户可以通过以下方式使用 DiffusionDB-Pixelart 数据集:1)使用 Hugging Face Datasets Loader 库加载数据集;2)直接下载数据集并解压,然后使用 Python 等编程语言进行访问和处理。在加载数据集时,用户可以选择不同的子集,以满足不同的研究需求。此外,数据集还提供了元数据信息,方便用户进行进一步的分析和研究。
背景与挑战
背景概述
DiffusionDB-Pixelart数据集是DiffusionDB 2M数据集的一个子集,已被转换为像素艺术风格。DiffusionDB是第一个大规模的文本到图像提示数据集,包含由真实用户使用提示和超参数生成的1400万张图像。DiffusionDB提供了两个子集(DiffusionDB 2M和DiffusionDB Large)来支持不同的需求。像素化版本的数据是从DiffusionDB 2M中提取的,只有2000个示例。该数据集旨在帮助研究人员更好地理解大型文本到图像生成模型,并设计出能够帮助用户更容易使用这些模型的工具。
当前挑战
DiffusionDB-Pixelart数据集面临的挑战包括:1)数据集的规模和多样性为研究人员提供了理解提示和生成模型之间相互作用的机会,但同时也带来了处理和分析大规模数据的挑战;2)由于数据集来源于Discord服务器,可能会存在一定的偏见,例如,早期用户可能是AI艺术爱好者,其提示风格可能并不代表普通用户;3)数据集可能包含不适宜工作的图像,因此需要设置适当的阈值来过滤这些内容。
常用场景
经典使用场景
DiffusionDB-Pixelart 数据集作为首个大规模文本到图像提示数据集,在图像生成和人工智能领域具有重要的应用价值。它主要被用于研究和开发文本到图像生成模型,特别是那些需要高分辨率和像素艺术的模型。例如,研究人员可以使用这个数据集来训练和测试新的文本到图像生成算法,以及设计新的提示工程技术来改善图像生成的效果和效率。
衍生相关工作
DiffusionDB-Pixelart 数据集衍生了许多相关的研究工作,包括但不限于:1. 提示工程技术的研究:研究人员利用这个数据集来研究和开发新的提示工程技术,以改善图像生成的效果和效率。2. 文本到图像生成模型的研究:研究人员利用这个数据集来训练和测试新的文本到图像生成算法,以及设计新的图像生成模型。3. 深度伪造检测技术的研究:研究人员利用这个数据集来研究和开发深度伪造检测技术,以识别和防止虚假图像的生成和传播。
数据集最近研究
最新研究方向
DiffusionDB-Pixelart 数据集在文本到图像生成模型领域的研究方向主要集中在理解和优化提示与生成模型之间的交互,以及如何编写有效的提示。该数据集提供了一个前所未有的规模和多样性,使得研究人员能够更深入地探索这些模型如何响应不同的提示,以及如何设计工具来帮助用户更轻松地生成图像。此外,DiffusionDB-Pixelart 数据集还可以用于检测深度伪造,以及设计人机交互工具来帮助用户更轻松地使用这些模型。
以上内容由遇见数据集搜集并总结生成


