afrofinchain-multilingual-web3
收藏Hugging Face2026-04-27 更新2026-04-28 收录
下载链接:
https://huggingface.co/datasets/FirstBML1/afrofinchain-multilingual-web3
下载链接
链接失效反馈官方服务:
资源简介:
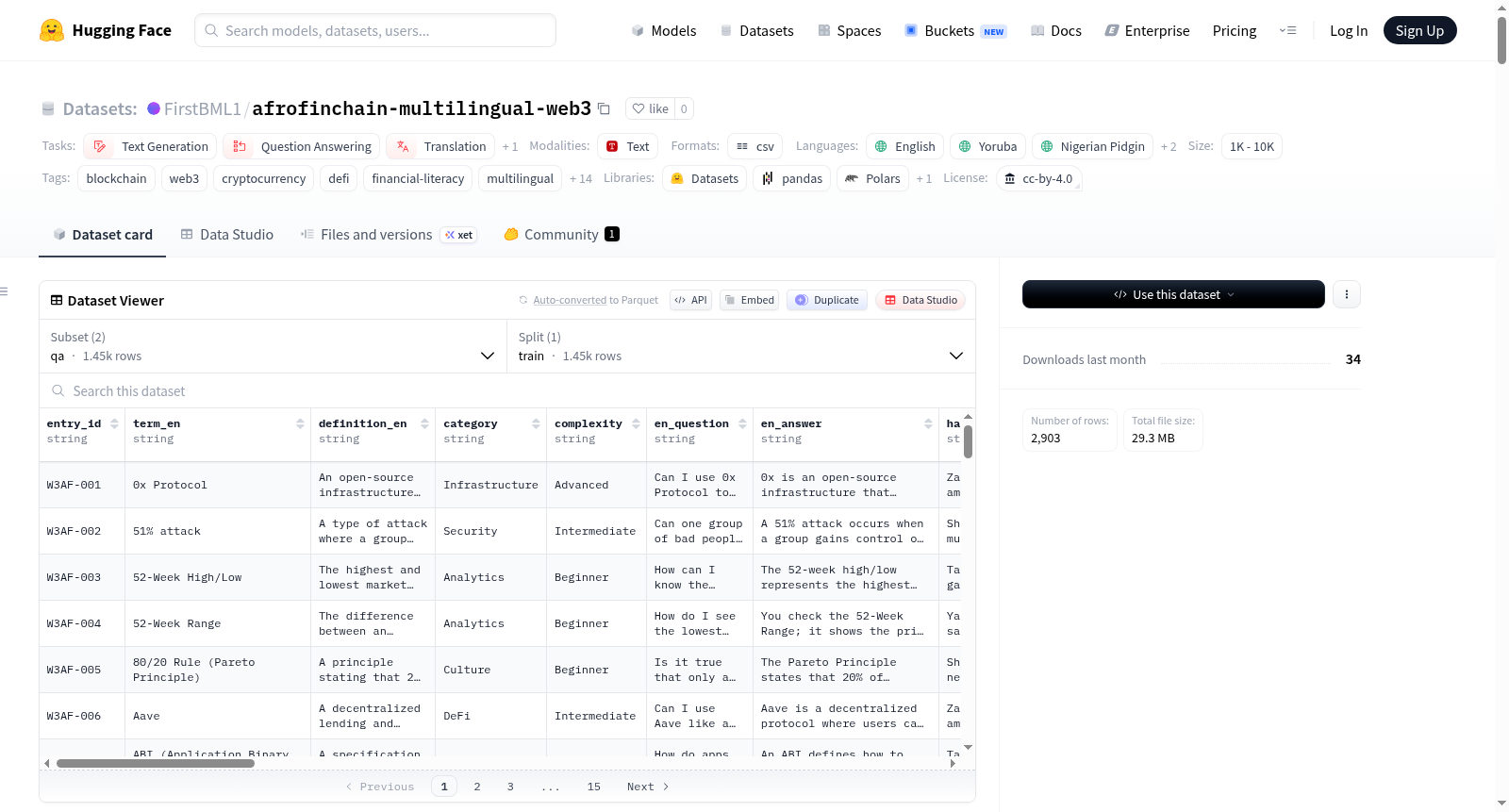
AfroFinChain是一个多语言的区块链和去中心化金融(DeFi)数据集,涵盖英语、约鲁巴语、尼日利亚皮钦语、豪萨语和伊博语。该数据集包含1,451条术语条目和1,452组问答对,旨在为低资源的非洲语言提供LLM训练、金融知识普及和对话式AI支持。数据集分为两部分:术语数据集和问答数据集,每部分都包含多语言的定义、使用示例和文化类比。术语数据集覆盖11个类别,包括基础设施、金融、文化、安全等;问答数据集则模拟了WhatsApp、Telegram等平台的真实对话场景。数据集采用CC-BY-4.0许可,目前为AI生成版本(v1.0),计划于2026年4月30日发布经过人工验证的v2.0版本。
AfroFinChain is a multilingual blockchain and decentralized finance (DeFi) dataset covering English, Yoruba, Nigerian Pidgin, Hausa, and Igbo. The dataset contains 1,451 term entries and 1,452 question-answer pairs, aiming to provide LLM training, financial literacy, and conversational AI support for low-resource African languages. The dataset is divided into two parts: a terminology dataset and a Q&A dataset, each containing multilingual definitions, usage examples, and cultural analogies. The terminology dataset covers 11 categories, including infrastructure, finance, culture, security, etc.; the Q&A dataset simulates real conversation scenarios on platforms like WhatsApp and Telegram. The dataset is licensed under CC-BY-4.0 and is currently an AI-generated version (v1.0), with a planned release of a human-verified v2.0 version on April 30, 2026.
创建时间:
2026-04-24
原始信息汇总
AfroFinChain — Multilingual Web3 & Blockchain Dataset 概述
数据集基本信息
| 属性 | 内容 |
|---|---|
| 数据集名称 | AfroFinChain — Multilingual Web3 & Blockchain Dataset |
| 语言 | 英语 (EN)、约鲁巴语 (YO)、尼日利亚皮钦语 (PCM)、豪萨语 (HA)、伊博语 (IG) |
| 领域 | 区块链、Web3、DeFi、加密货币 |
| 许可证 | CC-BY-4.0 |
| 数据集大小 | 1,000 < n < 10,000 |
| 版本状态 | v1.0 AI生成;v2.0 人工验证版预计2026年4月30日发布 |
| 托管平台 | HuggingFace |
数据集构成
第一部分:术语数据集
- 文件:
AfroFinChain_Multilingual_Web3_Terminology_EN_YO_PCM_HA_IG.csv - 条目数量: 1,451 行
- 列数: 38 列
- 类别覆盖: 11 个类别
| 类别 | 术语数量 | 涵盖范围 |
|---|---|---|
| 基础设施 (Infrastructure) | 533 | 节点、EVM、Layer-1/Layer-2、挖矿、网络 |
| 金融 (Finance) | 345 | 交易、市场、DeFi经济学、传统金融桥梁 |
| 文化 (Culture) | 151 | 俚语、社区术语、历史事件、加密人物 |
| 安全 (Security) | 134 | 威胁、漏洞、认证、隐私保护 |
| DeFi | 72 | AMM、流动性、借贷、质押、收益 |
| 共识机制 (Consensus) | 69 | PoS、PoW、验证者、最终性、分叉 |
| 分析 (Analytics) | 49 | 链上指标、图表、指标 |
| 治理 (Governance) | 35 | DAO、投票、提案、国库 |
| 钱包 (Wallets) | 29 | 钱包类型、托管、密钥管理、助记词 |
| AI代理 (AI_Agents) | 23 | 自主代理、Web3中的AI |
| 身份 (Identity) | 11 | DID、KYC/AML、假名性 |
每个条目为每种语言提供:自然语言定义、使用示例、基于尼日利亚日常生活的文化类比。
第二部分:问答数据集
- 文件:
AfroFinChain_Multilingual_Web3_QA_EN_YO_PCM_HA_IG.csv - 条数: 1,452 行
- 列数: 36 列
- 问题风格: 涵盖风险查询、比较查询、场景查询、澄清查询、实用查询等(以WhatsApp、Telegram、Twitter常用语风格撰写)
数据集结构
两个文件均按三部分结构组织,由分隔列明确划分:
| 分隔列名称 | 分隔内容 |
|---|---|
── INPUT DATA ── |
原始种子数据开始 |
── ADAPTIVE DATA OUTPUT ── |
输入部分结束 / Adaptive Data原始输出开始 |
── EXTRACTED FEATURES ── |
原始输出结束 / 后处理提取的ec_*列开始 |
术语文件重要列(提取特征部分)
ec_category— 推断类别(自动校正为11个规范值)ec_complexity— Beginner / Intermediate / Advancedec_en_definition— 生成的英文定义(最多2句)ec_yo_definition/ec_yo_analogy— 约鲁巴语定义和文化类比ec_pcm_definition/ec_pcm_analogy— 皮钦语定义和文化类比ec_ha_definition/ec_ha_analogy— 豪萨语定义和文化类比ec_ig_definition/ec_ig_analogy— 伊博语定义和文化类比(强制使用变音符号ọ、ụ、ị)
问答文件重要列(提取特征部分)
ec_en_question/ec_en_answer— 英文问题和答案ec_yo_question/ec_yo_answer— 约鲁巴语问题和答案ec_pcm_question/ec_pcm_answer— 皮钦语问题和答案ec_ha_question/ec_ha_answer— 豪萨语问题和答案ec_ig_question/ec_ig_answer— 伊博语问题和答案ec_source— 来源域名
构建流程
- 来源收集: 从12个规范区块链参考网站(如ethereum.org、bitcoin.org、ledger.com等)采集英文种子定义,使用5,106个术语的查找表进行来源映射。
- Adaptive Data生成: 使用Adaption平台的Adaptive Data功能,通过两个定制Blueprint生成所有多语言内容。
- 异常行处理: 识别并重新生成12个输出为散文格式的异常条目(如Bug Exploit、IPFS、Full Node等)。
- 后处理管道: 使用两个Python脚本(
extract_flat_columns.py和extract_qa_flat_columns.py)从enhanced_completion中提取结构化列,不覆盖原始输入数据。 - 人工验证: 计划于2026年4月30日前由母语者完成,涵盖语言准确性、文化类比相关性、技术准确性和问答直接性四个维度。
主要用例
- 多语言LLM微调(GPT、LLaMA、Mistral)
- 非洲加密货币教育对话式AI
- 跨语言迁移学习
- 新兴市场金融素养和防欺诈工具
- 低资源语言NLP研究
已知局限
- 内容为AI生成,人工验证正在进行中,部分定义可能存在语言或文化不准确之处。
- 文化类比主要基于拉各斯、卡诺/卡杜纳、埃努古/奥尼查/奥韦里地区背景,未完全覆盖各语言区域内的变体。
搜集汇总
数据集介绍
构建方式
AfroFinChain数据集以区块链与去中心化金融为知识锚点,聚焦于尼日利亚语境中五种语言(英语、约鲁巴语、尼日利亚皮钦语、豪萨语、伊博语)的跨语际映射。其构建历经五个阶段:首先从12个权威区块链平台系统性地采集英源种子定义与术语;继而依托Adaptive Data平台的定制化蓝图,针对术语与问答两种子集分别生成多语言内容,并在生成过程中嵌入丰富的文化类比;随后通过自动检测脚本识别出12个结构异常行,借助修正后的蓝图重新生成以保障数据完整性;紧接着运用后处理流水线从原始输出中提取标准化特征列,同时保留完整的审计轨迹;最终计划由母语社区与区块链从业者共同完成人类验证环节,涵盖语言自然度、文化类比贴合性、技术精确性及问答直答性四大维度。
特点
该数据集的核心特色在于其不可替代的跨领域综合性。作为首个融合Web3领域与尼日利亚低资源语言的多语料库,它巧妙地将抽象的区块链概念嵌入到当地民众熟悉的Ajo、Adashi、Isusu、Fatake等社会经济实践之中,使认知壁垒从晦涩的金融术语转化为亲切的文化经验。数据集被结构化为两大互为补充的模块:术语模块涵盖1451条记录,横跨基础设施、金融、安全、去中心化金融等11个主题类别;问答模块则包含1452对模拟WhatsApp、Telegram与Twitter交流场景的真实对话,其措辞贴近日常口语而非教材式的规范表述。此外,每项记录均包含分类层次标签(初级/中级/高级)与清晰的理论来源归属,便于检索增强生成与分层式教学应用。
使用方法
该数据集的使用方式灵活且高度适配现代自然语言处理工作流。研究人员可直接通过HuggingFace的datasets库调用数据,加载术语与问答两个子集后,借助ec_category与ec_complexity字段进行细粒度筛选,例如提取所有涉及去中心化金融的初级知识卡片。对于大语言模型的指令微调任务,结构化特征列(如ec_en_question与ec_yo_answer的多语问答对)可被直接拼接为提示-响应模板,无需额外清洗。问答模块的自然对话风格特别适合用于开发面向非洲新兴市场的加密教育聊天机器人或欺诈预警系统。数据集的CC-BY-4.0许可证确保了其在学术研究与商业项目中的广泛可用性,同时先验的后处理脚本萃取机制为跨语种迁移学习与低资源语言自然语言处理研究提供了高素质的输入语料。
背景与挑战
背景概述
AfroFinChain多语种Web3区块链数据集由Adaption Labs于2026年创作,作为Adaption未开发数据挑战赛(2025年4月至5月)的参赛作品。该数据集聚焦于解决尼日利亚低资源语言(约鲁巴语、豪萨语、伊博语、尼日利亚皮钦语)在区块链与去中心化金融教育领域的数据真空问题,通过涵盖1451个术语条目和1452个问答对,首次实现了Web3概念在非洲本土文化语境中的多语种映射。其核心研究问题在于,如何借助文化类比(如Ajo、Adashi、Isusu等当地互助储蓄体系)将抽象的区块链技术转化为普通民众可理解的金融知识,从而弥合尼日利亚因庞氏骗局泛滥与央行政策限制所导致的信任鸿沟。该数据集为低资源语言NLP、多语种大模型微调以及非洲数字金融素养普及开辟了全新路径,填补了HuggingFace平台上相关领域的空白。
当前挑战
AfroFinChain致力于解决的核心领域挑战在于,尼日利亚民众因缺乏母语区块链教育资源,无法区分合法DeFi协议与庞氏骗局,导致金融欺诈频发与正规数字金融工具被排斥。具体表现为:1451个术语需在五种语言中提供精准定义与文化类比,而非直译;问答对需模拟WhatsApp、Telegram等即时通讯场景的真实对话风格,以提升教育工具的实用性。构建挑战方面,数据集通过Adaptive Data框架生成内容时,遭遇了12行术语条目因模型忽视标记结构而输出非结构化散文文本的问题,需通过detect_broken_rows.py脚本识别并重新生成;此外,文化类比的多样性需扩展至每个语言12个以上参考池,以避免重复,同时需处理类别泄露等格式异常,最终通过后处理脚本(extract_flat_columns.py)进行自动校正和特征提取,确保数据格式统一有效。
常用场景
经典使用场景
在跨语言自然语言处理与低资源语言人工智能研究的交汇点上,AfroFinChain数据集主要被用于多语言大语言模型的指令微调与领域适配。研究者利用其结构化的术语定义与对话式问答对,针对约鲁巴语、豪萨语、伊博语及尼日利亚皮钦语等资源稀缺语言,构建面向区块链与去中心化金融领域的专业翻译、文本分类及文本生成模型。该数据集的独特之处在于其文化锚定的类比设计,使得模型不仅能够准确理解金融术语的技术内涵,还能在相应的文化语境中生成自然流畅的表达,从而为低资源语言的多模态对话系统开发提供了不可替代的训练资源。
实际应用
在实际应用层面,AfroFinChain数据集最直接的价值在于赋能面向非洲市场的加密货币教育平台与反欺诈工具开发。基于其中文化适配的对话式问答内容,开发者可构建类似WhatsApp与Telegram风格的智能客服机器人,帮助尼日利亚、加纳等地区的普通用户理解质押、流动性挖矿、地毯式抽逃等复杂概念,从而降低因信息不对称导致的投资风险。此外,该数据集还可用于构建检索增强生成系统,为金融监管机构提供本土语言的技术教育资源,以及赋能非营利组织设计针对农村社区的金融扫盲课程,真正实现从抽象知识到可操作行为的转化。
衍生相关工作
AfroFinChain数据集的诞生填补了HuggingFace平台上针对约鲁巴语、豪萨语等语言在区块链标签下的完全空白,其出现直接催生了若干衍生研究方向。一方面,研究者基于其文化类比结构开展了跨语言语义迁移学习实验,探索如何将Ajo储蓄类比等本土叙事框架迁移至其他低资源语言的金融教育场景;另一方面,该数据集的结构化设计启发了针对非洲语言的专用评价基准构建,包括术语翻译忠实度与文化适宜性的自动化评估指标。此外,其融合术语与问答的双模块架构为后续多语言专业领域数据集的建设提供了可复用的蓝图,推动了非洲本土语言在金融科技话语体系中的系统化表达进程。
以上内容由遇见数据集搜集并总结生成


