SHARE
收藏arXiv2024-10-28 更新2024-10-30 收录
下载链接:
https://anonymous.4open.science/r/SHARE-AA1E/SHARE.json
下载链接
链接失效反馈官方服务:
资源简介:
SHARE数据集是由西江大学创建的一个开放领域长期对话数据集,基于电影剧本构建。该数据集不仅包含对话中明确揭示的个人角色信息和事件,还隐含提取了共享记忆。数据集大小为119,087条对话,涵盖了多种电影类型,如浪漫、喜剧和动作。创建过程中,使用了电影剧本解析器和大型语言模型(LLMs)来提取和映射信息。SHARE数据集的应用领域主要在于增强长期对话的连贯性和吸引力,旨在解决现有对话系统在处理长期共享记忆方面的不足。
The SHARE dataset is an open-domain long-term dialogue dataset developed by Xijiang University, built upon film scripts. It not only includes explicit personal character information and events revealed in the dialogues, but also implicitly extracts shared memories. The dataset contains 119,087 dialogues spanning multiple film genres such as romance, comedy, and action. During its development, film script parsers and large language models (LLMs) were employed to extract and map relevant information. The primary application of the SHARE dataset is to enhance the coherence and appeal of long-term dialogues, with the goal of addressing the limitations of current dialogue systems in processing long-term shared memories.
提供机构:
西江大学
创建时间:
2024-10-28
原始信息汇总
数据集概述
基本信息
- 数据集名称: SHARE
- 数据集类型: JSON
- 数据集地址: https://anonymous.4open.science/r/SHARE-AA1E/SHARE.json
描述
该数据集是一个JSON格式的文件,存储在匿名GitHub平台上。数据集的具体内容未在提供的HTML文本中详细描述。
搜集汇总
数据集介绍
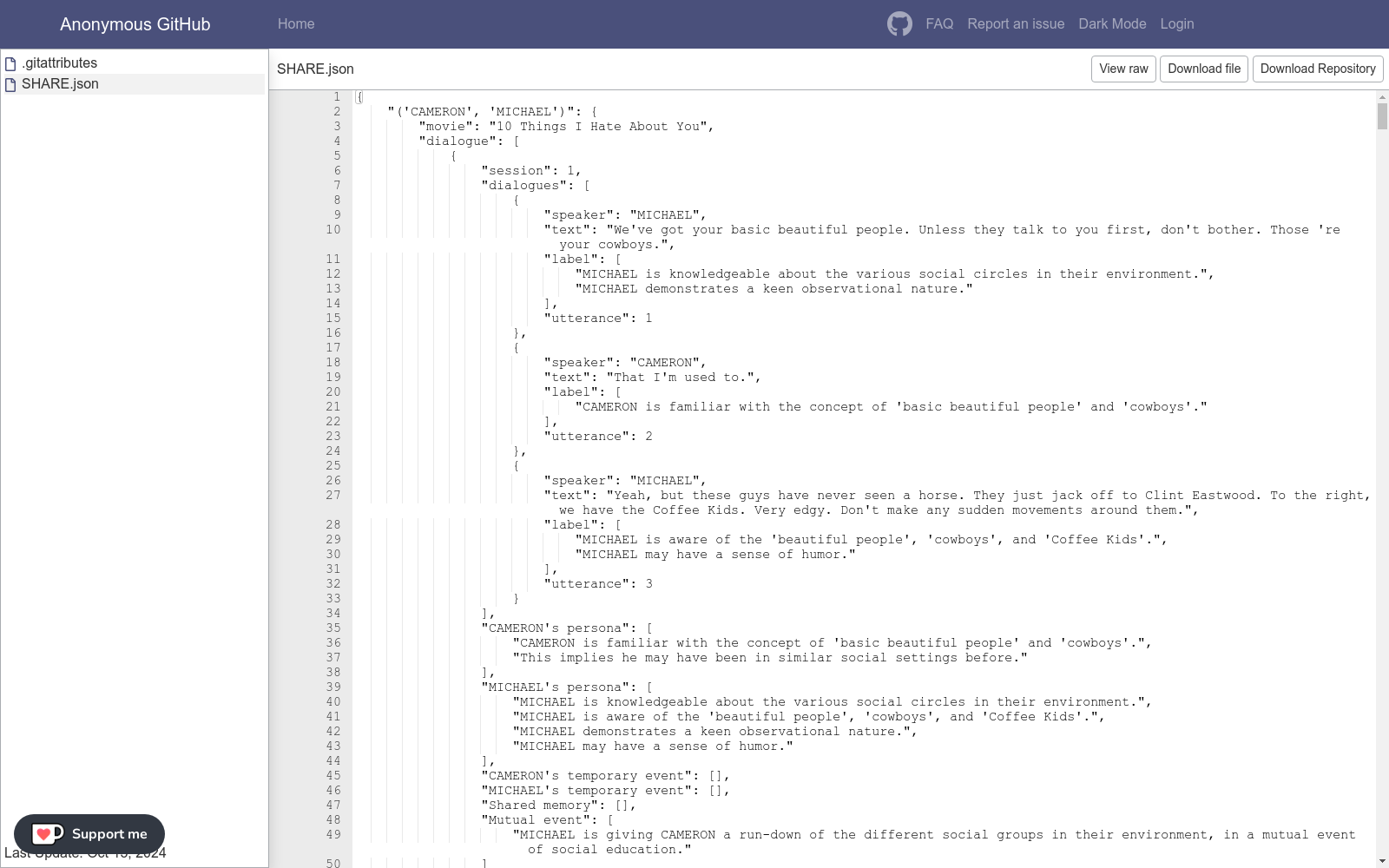
构建方式
SHARE数据集的构建基于电影剧本,这些剧本被视为共享记忆的丰富来源。首先,利用电影剧本解析器将剧本结构化为对话形式。随后,通过大型语言模型(LLMs)对每个说话者的个人资料和短期事件进行总结,并从对话中隐含地提取共享记忆。最后,将这些信息映射到相应的对话内容进行标注。这一过程不仅解决了通过众包收集对话数据的高成本问题,还避免了仅依赖对话中显性事件的局限性。
特点
SHARE数据集的显著特点在于其包含了共享记忆的信息,这是现有长期对话数据集中所缺乏的。该数据集不仅涵盖了个人的角色信息和事件,还特别强调了两人之间的共享记忆,这些记忆在增强对话的连贯性和吸引力方面起着关键作用。此外,数据集的多样性得益于从多种类型的电影中提取对话,确保了角色关系和事件的丰富性。
使用方法
SHARE数据集可用于训练和评估长期对话系统,特别是那些旨在利用共享记忆来增强对话连贯性和吸引力的系统。研究者可以通过该数据集开发和测试新的对话生成模型,这些模型能够有效地管理和利用共享记忆。此外,数据集还可用于验证现有对话框架的有效性,如EPISODE框架,该框架专门设计用于在长期对话中总结和管理共享记忆。
背景与挑战
背景概述
在人机交互领域,长期对话系统的研究日益受到重视。SHARE数据集由Sogang大学的Eunwon Kim、Chanho Park和Buru Chang团队于2024年创建,旨在通过利用共享记忆来增强长期对话的吸引力和可持续性。该数据集从电影剧本中提取,包含了两个个体之间的对话,不仅涵盖了个人信息的摘要和事件,还隐含了可提取的共享记忆。SHARE数据集的引入填补了现有数据集中缺乏共享记忆的空白,为研究如何利用共享记忆来提升长期对话的自然性和连贯性提供了宝贵的资源。
当前挑战
构建SHARE数据集面临多个挑战。首先,通过众包收集包含共享记忆的对话数据成本高昂,需要手动创建情境并让众包工作者进行角色扮演。其次,使用大型语言模型(LLMs)从对话中显式提取事件信息时,往往会忽略隐含的共享记忆。为解决这些问题,研究团队从电影剧本中收集长期对话数据,利用电影剧本中对话传达共享记忆的特点。此外,数据集中共享记忆的提取和标注也面临技术上的挑战,需要精确地从对话中识别和分类共享记忆,以确保数据集的质量和可用性。
常用场景
经典使用场景
SHARE数据集的经典使用场景在于其能够支持长期对话系统的开发与优化。通过利用电影剧本中的共享记忆信息,该数据集为研究者提供了一个丰富的资源,用于训练和评估对话模型在处理长期对话中的表现。具体而言,SHARE数据集被广泛应用于构建能够维持长期对话连贯性和吸引力的对话系统,特别是在涉及共享记忆和个性化对话内容的场景中。
解决学术问题
SHARE数据集解决了长期对话系统中常见的学术研究问题,特别是在如何有效管理和利用共享记忆以增强对话的连贯性和吸引力方面。传统的对话数据集往往缺乏对共享记忆的考虑,导致模型在处理长期对话时表现不佳。SHARE通过引入共享记忆信息,为研究者提供了一个新的视角,使得对话系统能够更好地反映对话双方的关系和历史,从而提升对话的自然度和用户满意度。
衍生相关工作
SHARE数据集的发布催生了一系列相关的经典工作,特别是在长期对话管理和共享记忆利用方面。例如,EPISODE框架基于SHARE数据集开发,通过有效地管理和更新共享记忆,显著提升了长期对话的连贯性和吸引力。此外,许多研究者利用SHARE数据集进行实验,验证了共享记忆在对话系统中的重要性,并提出了多种优化策略,如记忆选择和更新机制,进一步推动了该领域的发展。
以上内容由遇见数据集搜集并总结生成


