MS-ASL
收藏arXiv2019-11-21 更新2024-06-21 收录
下载链接:
https://www.microsoft.com/en-us/research/project/ms-asl/
下载链接
链接失效反馈官方服务:
资源简介:
MS-ASL是由微软创建的大型美国手语数据集,包含超过25,000个标注视频,涵盖200多名不同的手语使用者。数据集在真实且不受限制的环境中录制,包含1000种不同的手势类别。创建过程中,研究团队利用了公开的视频分享平台和光学字符识别技术来获取和处理视频数据。MS-ASL的应用领域主要集中在手语识别技术的发展,旨在解决手语识别中的挑战,如手语使用者的多样性和手势的复杂性。
MS-ASL is a large-scale American Sign Language (ASL) dataset developed by Microsoft. It comprises over 25,000 annotated videos involving more than 200 unique sign language signers. The dataset was recorded in realistic, unconstrained environments and covers 1,000 distinct gesture categories. During its development, the research team utilized public video sharing platforms and optical character recognition (OCR) technology to acquire and process the video data. The primary application scope of MS-ASL focuses on advancing sign language recognition technologies, aiming to address key challenges in sign language recognition such as the diversity of sign language users and the complexity of gestures.
提供机构:
微软
创建时间:
2018-12-04
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,手语识别因其多模态异步整合特性而极具挑战性,MS-ASL数据集的构建旨在填补大规模公开美国手语资源的空白。该数据集通过采集公共视频分享平台上的美国手语教学与交流视频,利用光学字符识别技术自动提取视频中的字幕、标题及描述文本,进而获取标注信息。随后,通过人脸检测与识别技术对视频中的手语者进行追踪与聚类,实现了对222名不同手语者的独立标识。为确保数据质量,研究团队对超过8秒的视频进行了人工修剪,并依据美国手语教程书籍合并了语义相近的标注类别,最终形成了包含1000个手势类别、超过25,000个标注视频的大规模数据集。
特点
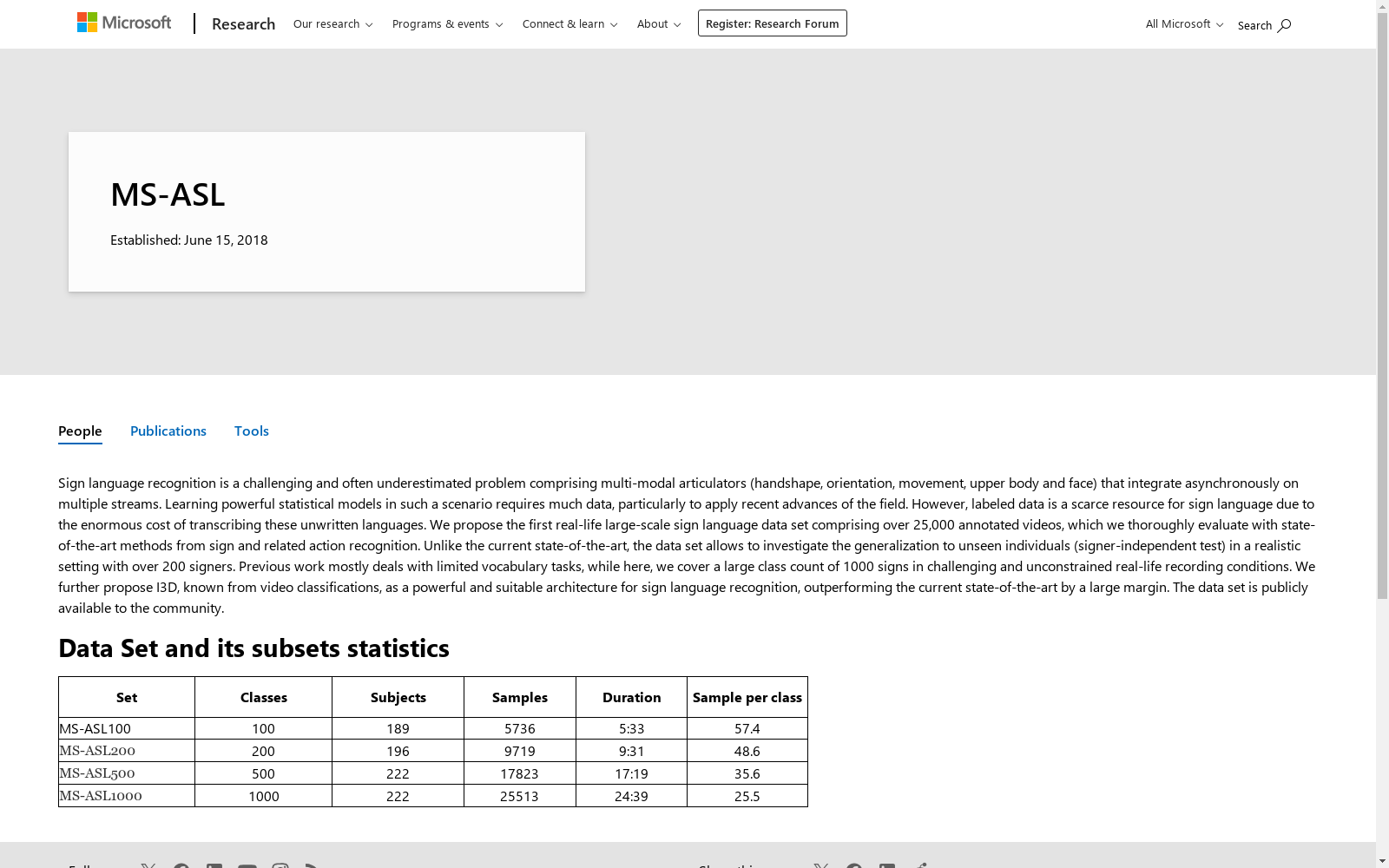
MS-ASL数据集在现有手语资源中展现出显著优势,其核心特点在于规模宏大且贴近真实应用场景。数据集涵盖了1000个美国手语词汇,视频样本总量超过25,000个,总时长约24小时,为深度学习模型训练提供了充足的数据支持。尤为突出的是,数据集包含了222名不同的手语者,并严格划分了训练集、验证集与测试集,确保了手语者独立性,这对于评估模型在未见手语者上的泛化能力至关重要。此外,所有视频均来源于非受控的真实录制环境,背景、光照、视角及着装存在高度多样性,同时涵盖了地域方言带来的手势变异,极大地增强了数据集的现实挑战性。
使用方法
为促进手语识别研究的可复现性与公平比较,MS-ASL数据集提供了清晰的使用框架。数据集按词汇频率划分为ASL100、ASL200、ASL500和ASL1000四个子集,每个子集均包含严格手语者独立的训练、验证与测试划分。研究者可基于这些子集进行模型训练与评估,建议采用平均每类准确率与平均每类前五准确率作为核心评估指标,以应对数据类别不平衡问题。数据集中每个视频均提供了经检测的手语者边界框,可直接用于模型输入。基准实验表明,基于RGB视频的I3D网络架构在该数据集上表现优异,可作为强基线模型;同时,数据集也支持基于2D-CNN-LSTM、人体关键点等方法的性能验证,为探索非侵入式手语识别技术提供了多样化实验平台。
背景与挑战
背景概述
在计算机视觉领域,手语识别长期被视为一项复杂且被低估的挑战,其涉及手形、方向、动作、上半身及面部等多模态异步整合的视觉流。传统方法多依赖外部设备或受控环境,限制了实际应用。2019年,微软研究院的Hamid Reza Vaezi Joze与Oscar Koller等人推出了MS-ASL数据集,旨在填补美国手语大规模公开数据的空白。该数据集包含超过25,000个标注视频,涵盖1,000个词汇类别及222名独立手语者,其核心研究问题聚焦于非侵入式、仅基于RGB视频的大词汇量孤立手语识别,并在真实无约束的录制条件下推进了手语者无关的泛化能力研究。MS-ASL的发布为深度学习模型在该领域的应用提供了关键数据支撑,显著推动了手语识别技术向实用化迈进。
当前挑战
MS-ASL数据集所针对的手语识别领域,其核心挑战在于处理高维异步多模态信号,并需在无外部传感器辅助下,仅从RGB视频中精准解析细微的手部形态与运动变化。构建该数据集时,研究人员面临多重困难:首先,从公开网络视频中自动化收集与标注面临巨大挑战,需结合光学字符识别、人脸检测与跟踪等技术以提取有效片段,并需手动修剪与审核约25%的数据以确保质量。其次,手语作为无文字语言,同一语义可能对应多种手势变体,需依据教程书籍进行语义映射以合并同类标志。此外,为实现手语者无关的评估,需通过人脸嵌入聚类识别222名独立手语者,并在类别与手语者样本不均衡约束下优化数据划分,这一过程极具复杂性。
常用场景
经典使用场景
在计算机视觉与手语识别领域,MS-ASL数据集为孤立美国手语词汇的识别任务提供了大规模、真实场景的基准测试平台。该数据集包含超过2.5万个标注视频,涵盖1000个手语词汇,由222位不同手语者录制,确保了数据的多样性与真实性。其经典使用场景在于为深度学习模型,特别是三维卷积神经网络(如I3D),提供了充足的训练与验证数据,以评估模型在复杂光照、背景及视角变化下的泛化能力。研究者常利用该数据集进行模型性能的横向比较,推动手语识别技术向实用化迈进。
解决学术问题
MS-ASL数据集有效解决了手语识别研究中长期存在的若干关键学术问题。首先,它通过提供大规模、多手语者的真实场景数据,显著缓解了训练数据稀缺的困境,使得深度学习模型能够充分学习手语的复杂时空特征。其次,数据集严格划分了训练集与测试集的手语者,为评估模型在未见手语者上的泛化性能(即手语者独立性)提供了可靠基准。此外,其涵盖的1000个词汇量突破了以往数据集的局限,支持大规模词汇量的孤立词识别研究,为探索手语的语言学特性与计算机视觉技术的结合奠定了数据基础。
衍生相关工作
MS-ASL数据集的发布催生了一系列围绕美国手语识别的经典研究工作。其本身提出的基于I3D网络的基线方法,为后续研究确立了强大的性能标杆。许多后续工作在此基础上进行改进,例如探索多模态融合(结合RGB视频与光流信息)、引入更精细的手部关键点检测、或设计针对手语时序特性的新型网络架构。该数据集也常被用于迁移学习研究,以其预训练模型作为起点,提升在其他规模较小或不同手语数据集上的性能。此外,围绕数据增强、解决类别不平衡以及处理手语同义词歧义等挑战的研究,也大量以MS-ASL作为核心实验平台,持续推动着手语识别领域的算法进步。
以上内容由遇见数据集搜集并总结生成


