有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
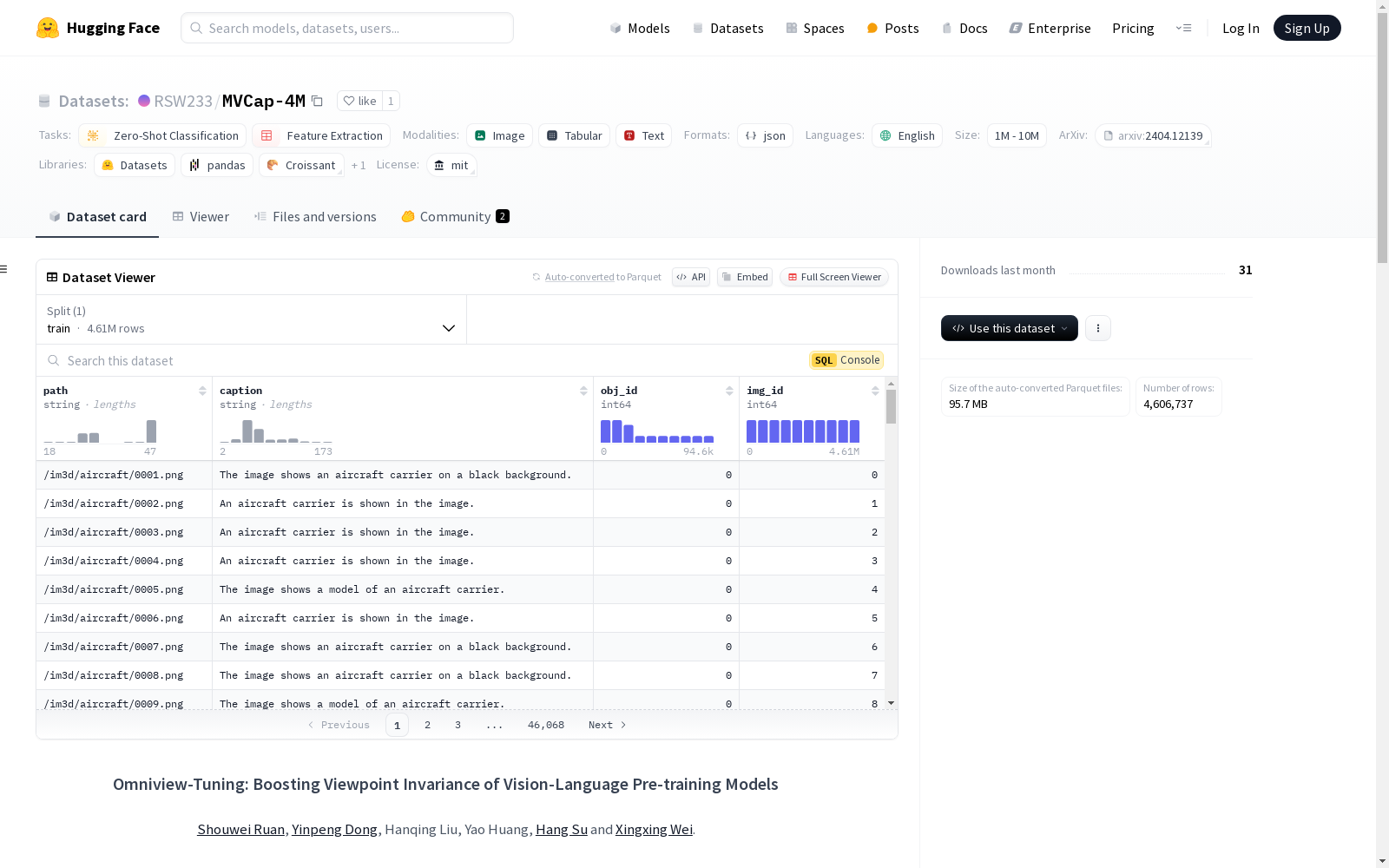
MVCap-4M 是一个大规模数据集,专为视觉-语言预训练模型的视角不变性研究设计。该数据集包含超过460万个多视角图像-文本对,涉及超过10万个对象。数据集通过整合多种3D资产和真实世界的多视角数据构建,使用视觉大型语言模型(VLLM)进行自动字幕生成,以获得语义丰富的文本描述。为确保不同视角下类别一致性,采用了类别引导提示策略。
metadata.json: 存储每个图像样本的路径、字幕、对象ID和图像ID。 json { "path": "./views/54cadb86f3db4aa6920f673aeff0d1e3/026.png", "caption": "The rocking chair in the image is made of metal and has a green cushion on it.", "obj_id": 3177, "img_id": 317726 }
源多视角图像: 从三个现有3D数据集中采样。
/views 子文件夹/im3d 子文件夹/mvimgnet 子文件夹如需引用该数据集,请参考以下格式: bibtex @article{Ruan2024Omniview, title={Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models}, author={{Shouwei Ruan, Yinpeng Dong, Hanqing Liu, Yao Huang, Hang Su, Xingxing Wei}}, journal={European Conference on Computer Vision (ECCV)}, year={2024} }
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
LIDC-IDRI
LIDC-IDRI 数据集包含来自四位经验丰富的胸部放射科医师的病变注释。 LIDC-IDRI 包含来自 1010 名肺部患者的 1018 份低剂量肺部 CT。
OpenDataLab 收录
Breast Cancer Dataset
该项目专注于清理和转换一个乳腺癌数据集,该数据集最初由卢布尔雅那大学医学中心肿瘤研究所获得。目标是通过应用各种数据转换技术(如分类、编码和二值化)来创建一个可以由数据科学团队用于未来分析的精炼数据集。
github 收录
Beijing Traffic
The Beijing Traffic Dataset collects traffic speeds at 5-minute granularity for 3126 roadway segments in Beijing between 2022/05/12 and 2022/07/25.
Papers with Code 收录
PlantVillage
在这个数据集中,39 种不同类别的植物叶子和背景图像可用。包含 61,486 张图像的数据集。我们使用了六种不同的增强技术来增加数据集的大小。这些技术是图像翻转、伽玛校正、噪声注入、PCA 颜色增强、旋转和缩放。
OpenDataLab 收录