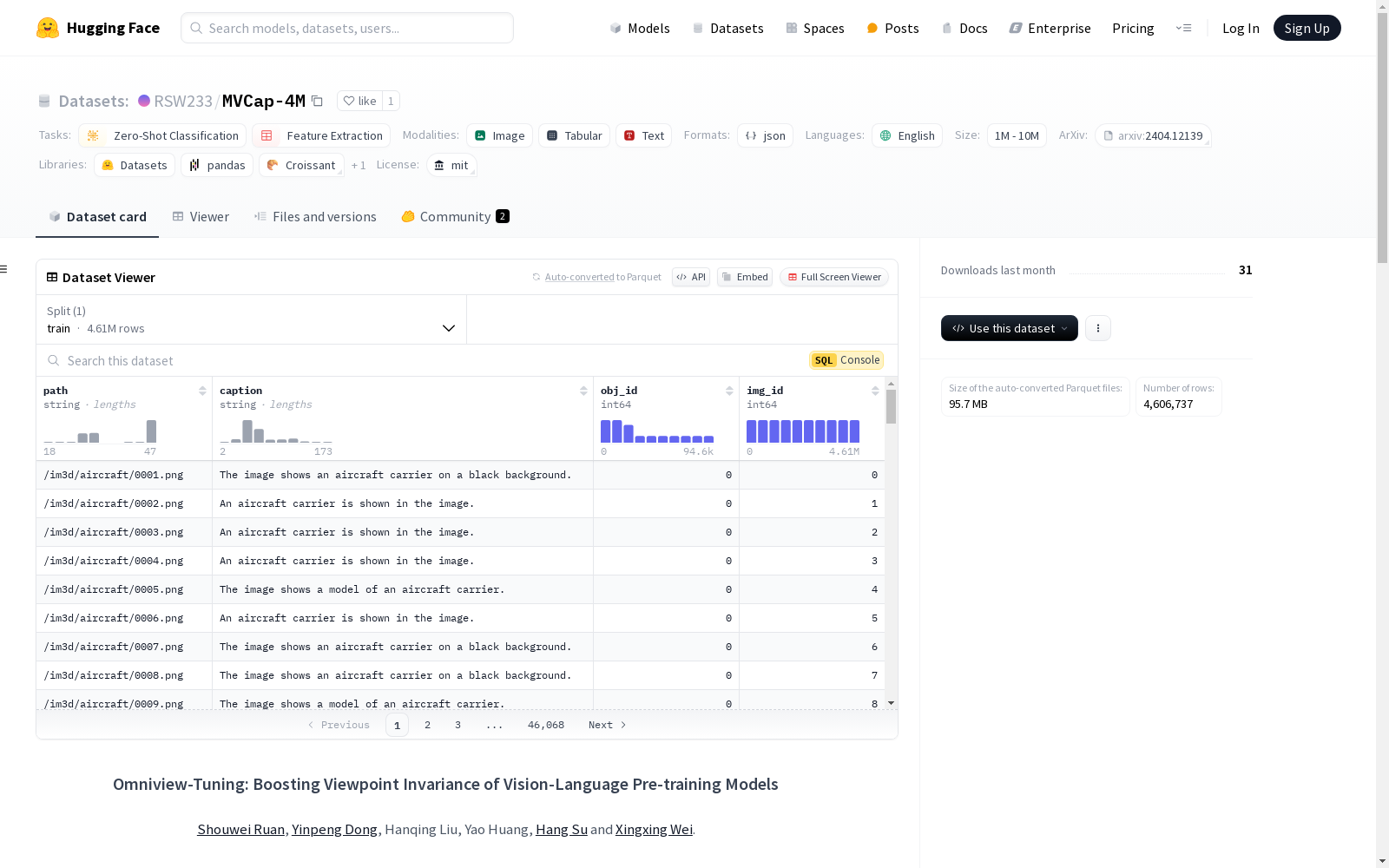
MVCap-4M
收藏Hugging Face2024-07-04 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/RSW233/MVCap-4M
下载链接
链接失效反馈官方服务:
资源简介:
MVCap-4M数据集是一个大规模的多视角图像-文本对数据集,专门用于视觉-语言预训练(VLP)模型的视角不变性研究。该数据集包含超过460万对多视角图像-文本对,涵盖超过10万个对象。数据集的构建结合了多种3D资产和真实世界的多视角数据,通过广泛的选择和渲染多视角图像,并利用视觉大型语言模型(VLLM)进行自动标题生成,以获得语义丰富的文本描述。此外,为了确保不同视角下类别的一致性,实施了类别引导的提示策略。
MVCap-4M dataset is a large-scale multi-view image-text pair dataset specifically developed for research on viewpoint invariance in vision-language pre-training (VLP) models. It contains over 4.6 million multi-view image-text pairs, covering more than 100,000 objects. The dataset construction integrates multiple 3D assets and real-world multi-view data, via extensive selection and rendering of multi-view images, and leverages visual large language models (VLLM) for automatic caption generation to obtain semantically rich text descriptions. Furthermore, to ensure the consistency of categories across different viewpoints, a category-guided prompting strategy is implemented.
创建时间:
2024-07-04
原始信息汇总
MVCap-4M 数据集概述
数据集信息
- 名称: MVCap-4M
- 语言: 英语
- 任务类别:
- 零样本分类
- 特征提取
- 数据规模: 1M<n<10M
- 配置:
- 默认配置
- 数据文件:
- 训练集: metadata.json
数据集描述
MVCap-4M 是一个大规模数据集,专为视觉-语言预训练模型的视角不变性研究设计。该数据集包含超过460万个多视角图像-文本对,涉及超过10万个对象。数据集通过整合多种3D资产和真实世界的多视角数据构建,使用视觉大型语言模型(VLLM)进行自动字幕生成,以获得语义丰富的文本描述。为确保不同视角下类别一致性,采用了类别引导提示策略。
数据文件结构
-
metadata.json: 存储每个图像样本的路径、字幕、对象ID和图像ID。 json { "path": "./views/54cadb86f3db4aa6920f673aeff0d1e3/026.png", "caption": "The rocking chair in the image is made of metal and has a green cushion on it.", "obj_id": 3177, "img_id": 317726 }
-
源多视角图像: 从三个现有3D数据集中采样。
- Objavers-80k: 存储在
/views子文件夹 - IM3D: 存储在
/im3d子文件夹 - MVImgNet: 存储在
/mvimgnet子文件夹
- Objavers-80k: 存储在
引用
如需引用该数据集,请参考以下格式: bibtex @article{Ruan2024Omniview, title={Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models}, author={{Shouwei Ruan, Yinpeng Dong, Hanqing Liu, Yao Huang, Hang Su, Xingxing Wei}}, journal={European Conference on Computer Vision (ECCV)}, year={2024} }
搜集汇总
数据集介绍
构建方式
MVCap-4M数据集的构建过程体现了多视角图像与文本对的高效整合。该数据集通过融合多种3D资产和真实世界的多视角数据,精心挑选并渲染了来自现有数据集的多视角图像。为了生成语义丰富的文本描述,研究团队采用了视觉大语言模型(VLLM)进行自动化标注,并引入了类别引导的提示策略,确保不同视角下的文本描述在类别上保持一致。这一构建方式不仅减少了人工标注的负担,还提升了数据集的多样性和准确性。
特点
MVCap-4M数据集以其大规模和多视角特性脱颖而出,包含超过460万对多视角图像-文本对,涵盖超过10万个对象。其独特之处在于,数据集不仅提供了丰富的多视角图像,还通过自动化生成的文本描述为每张图像提供了语义信息。此外,数据集的多视角特性使其特别适合用于研究视觉-语言预训练模型在视角不变性方面的表现,为相关领域的研究提供了宝贵的资源。
使用方法
使用MVCap-4M数据集时,用户可以通过`metadata.json`文件访问每张图像的路径、文本描述、对象ID和图像ID等信息。数据集的多视角图像分别存储在不同的子文件夹中,如`/views`、`/im3d`和`/mvimgnet`,便于用户根据需求进行调用。该数据集特别适用于视觉-语言预训练模型的训练和评估,尤其是在多视角场景下的表现测试。用户可以通过引用相关论文,进一步了解数据集的应用场景和技术细节。
背景与挑战
背景概述
MVCap-4M数据集由Shouwei Ruan、Yinpeng Dong等研究人员于2024年提出,旨在推动视觉-语言预训练模型(VLP)在视角不变性方面的研究。该数据集包含超过460万对多视角图像-文本对,涵盖超过10万个对象,结合了多种3D资产和真实世界的多视角数据。通过使用视觉大语言模型(VLLM)自动生成语义丰富的文本描述,并采用类别引导提示策略确保不同视角下文本描述的一致性,MVCap-4M为视角不变性研究提供了丰富的数据支持。该数据集在ECCV 2024会议上发布,对视觉-语言预训练模型的进一步发展具有重要意义。
当前挑战
MVCap-4M数据集在构建过程中面临多重挑战。首先,多视角图像-文本对的生成需要从现有数据集中广泛选择和渲染多视角图像,这一过程对数据质量和多样性提出了高要求。其次,自动生成文本描述时,如何确保不同视角下描述的语义一致性和准确性是一个关键问题。为此,研究团队采用了类别引导提示策略,但仍需克服模型生成描述时的偏差和错误。此外,数据集的规模庞大,涉及超过460万对图像-文本对,这对数据存储、处理和标注的效率提出了挑战。如何高效管理和利用这些数据,同时保持数据的一致性和质量,是未来研究需要解决的重要问题。
常用场景
经典使用场景
MVCap-4M数据集在视觉-语言预训练模型的研究中扮演着关键角色,特别是在提升模型对多视角图像的鲁棒性方面。该数据集通过提供超过460万对多视角图像-文本对,涵盖了超过10万个对象,为研究者提供了一个丰富的实验平台。经典的使用场景包括训练和评估视觉-语言模型在多视角图像下的表现,尤其是在零样本分类和特征提取任务中,模型能够通过该数据集学习到不同视角下的语义一致性。
实际应用
在实际应用中,MVCap-4M数据集被广泛应用于增强视觉-语言模型在现实场景中的表现。例如,在自动驾驶和机器人视觉系统中,模型需要处理来自不同视角的图像输入,并生成准确的语义描述。该数据集通过提供多视角图像和对应的文本描述,帮助模型在实际应用中更好地理解和处理多视角信息,从而提高系统的整体性能和可靠性。
衍生相关工作
MVCap-4M数据集的发布催生了一系列相关研究工作,特别是在多视角视觉-语言模型领域。基于该数据集,研究者们提出了多种改进模型视角不变性的方法,如视角不变特征提取和多视角语义对齐技术。这些工作不仅进一步验证了数据集的实用性,还为视觉-语言模型的未来发展提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


