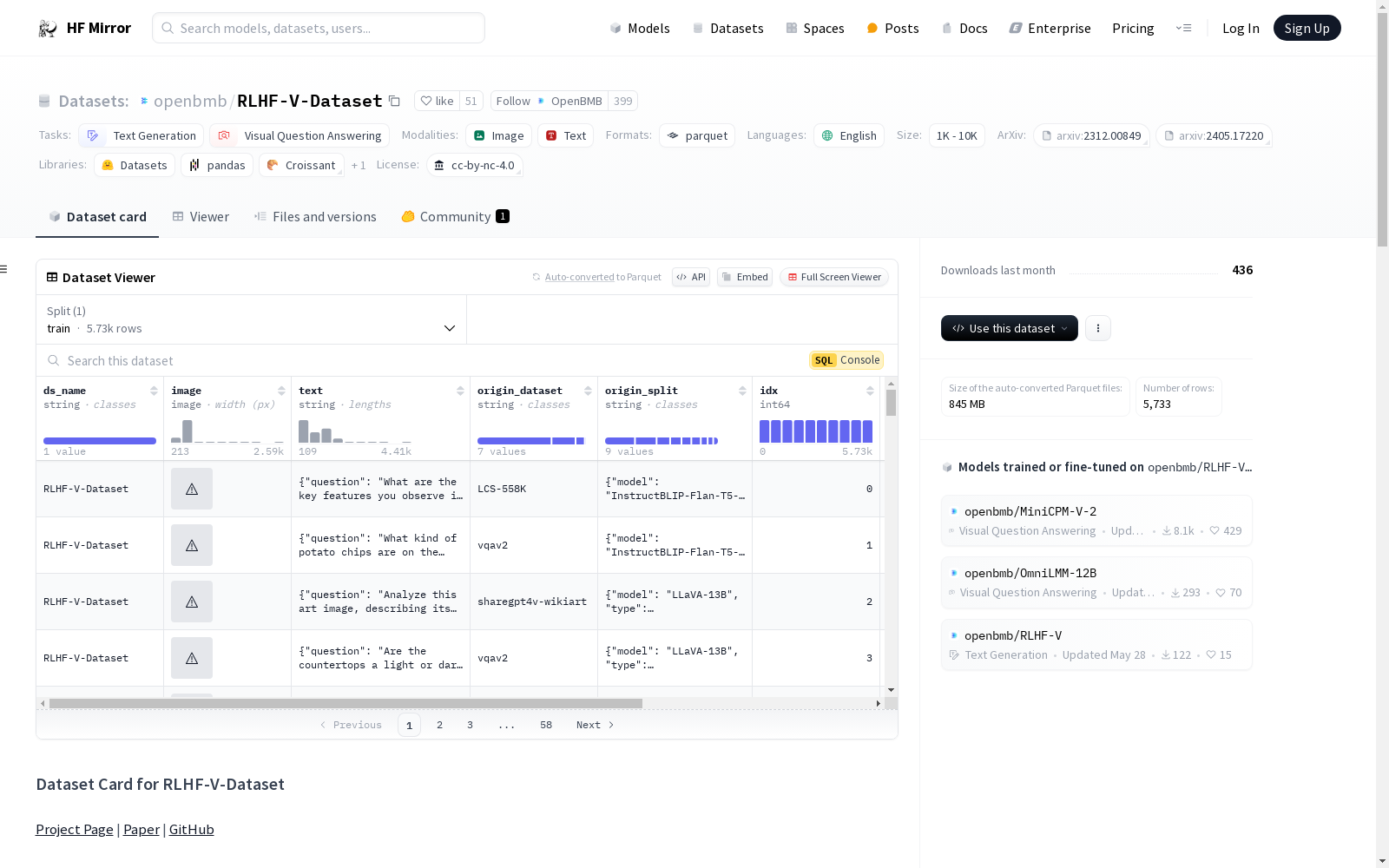
openbmb/RLHF-V-Dataset
收藏数据集卡片 for RLHF-V-Dataset
数据集概述
RLHF-V-Dataset 是用于 "RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback" 的人类偏好数据。该数据集收集了大量细粒度的段级人类修正,涵盖多样化的指令,包括详细描述和问答指令。数据集总共包含 5,733 个偏好对。
数据集信息
- 许可证: cc-by-nc-4.0
- 任务类别:
- 文本生成
- 视觉问答
- 语言: 英语
- 配置:
- 默认配置:
RLHF-V-Dataset.parquet
- 默认配置:
- 数据集特征:
ds_name: 数据集名称,类型为字符串image: 图像,类型为图像text: 偏好数据,类型为字符串origin_dataset: 原始标注数据集,类型为字符串origin_split: 每个数据项的元信息,类型为字符串idx: 数据索引,类型为整数image_path: 图像路径,类型为字符串
- 数据集名称: RLHF-V-Dataset
- 数据集大小: 1K<n<10K
数据字段
| 序号 | 键 | 描述 |
|---|---|---|
| 0 | ds_name |
数据集名称 |
| 1 | image |
包含路径和字节的字典。如果通过 load_dataset 加载,可以自动转换为 PIL 图像 |
| 2 | text |
偏好数据。每个数据项包含一个字典,键为 "question", "chosen", 和 "rejected" |
| 3 | origin_dataset |
用于标注的原始数据集,不用于训练 |
| 4 | origin_split |
每个数据项的元信息,包括我们用于生成原始答案的模型名称和问题类型("详细描述" 或 "问答") |
| 5 | idx |
数据索引 |
| 6 | image_path |
图像路径 |
引用
如果该数据集对您有帮助,请考虑引用我们的论文:
@article{yu2023rlhf, title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback}, author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others}, journal={arXiv preprint arXiv:2312.00849}, year={2023} }
@article{yu2024rlaifv, title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness}, author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong}, journal={arXiv preprint arXiv:2405.17220}, year={2024}, }