DexGraspNet 3.0
收藏arXiv2025-07-04 更新2025-07-05 收录
下载链接:
https://jiaweihe.com/dexvlg
下载链接
链接失效反馈官方服务:
资源简介:
DexGraspNet 3.0 是一个大规模的合成灵巧抓握数据集,包含 1.74 亿个与语义部分映射的灵巧抓握姿态,覆盖了 17.4 万个对象,并配有详细的分部分描述。该数据集通过高效的抓握合成流程生成,并结合了 SAMesh 和 GPT-4o 等先进模型进行部分分割和描述。DexGraspNet 3.0 用于训练 DexVLG 模型,该模型能够生成与语言指令对齐的通用抓握姿态,并在模拟和真实世界的实验中取得了优异的性能。
DexGraspNet 3.0 is a large-scale synthetic dexterous grasping dataset. It contains 174 million dexterous grasping poses mapped to semantic parts, covering 174,000 objects, with detailed per-part descriptions. This dataset is generated via an efficient grasping synthesis pipeline, and incorporates advanced models such as SAMesh and GPT-4o for part segmentation and description generation. DexGraspNet 3.0 is designed for training the DexVLG model, which can generate language-aligned general-purpose grasping poses and achieves excellent performance in both simulation and real-world experiments.
提供机构:
BAAI, Galbot, THU, PKU, CASIA, SJTU, EIT
创建时间:
2025-07-04
原始信息汇总
DexVLG: Dexterous Vision-Language-Grasp Model at Scale
基本信息
- 发表会议:ICCV 2025
- 作者:Jiawei He1,2, Danshi Li2, Xinqiang Yu*2, Zekun Qi2,3, Wenyao Zhang2,6,7, Jiayi Chen2,4, Zhaoxiang Zhang†5, Zhizheng Zhang†2, Li Yi†3, He Wang†1,2,4
- 机构:BAAI, Galbot, THU, PKU, CASIA, SJTU, EIT
- 论文:arXiv:2507.02747
- 代码:未提供具体链接
主要贡献
- 构建了大规模合成灵巧抓取数据集DexGraspNet3.0,包含带描述的抓取姿势(描述抓取部位和风格)。
- 基于DexGraspNet3.0数据集训练了语言指令抓取姿势预测模型DexVLG,该模型能在真实实验中为不同物体生成语言对齐且可泛化的抓取姿势。
数据集详情
- 名称:DexGraspNet 3.0
- 规模:1.7亿个灵巧抓取姿势
- 覆盖对象:174,000个
- 数据特性:映射到语义部位的抓取姿势,带有详细部位级描述
模型性能
- 零样本泛化能力:超过76%的执行成功率
- 仿真测试:在部位抓取准确率上达到state-of-the-art
- 真实场景:成功实现部位对齐抓取
技术特点
- 输入:单视角RGBD
- 架构:结合VLM和基于flow-matching的姿势头
- 功能:生成与语言指令对齐的桌面物体抓取姿势
引用格式
bibtex @article{dexvlg25, title={DexVLG: Dexterous Vision-Language-Grasp Model at Scale}, author={He, Jiawei and Li, Danshi and Yu, Xinqiang and Qi, Zekun and Zhang, Wenyao and Chen, Jiayi and Zhang, Zhaoxiang and Zhang, Zhizheng and Yi, Li and Wang, He}, journal={arXiv preprint arXiv:2507.02747}, year={2025} }
搜集汇总
数据集介绍
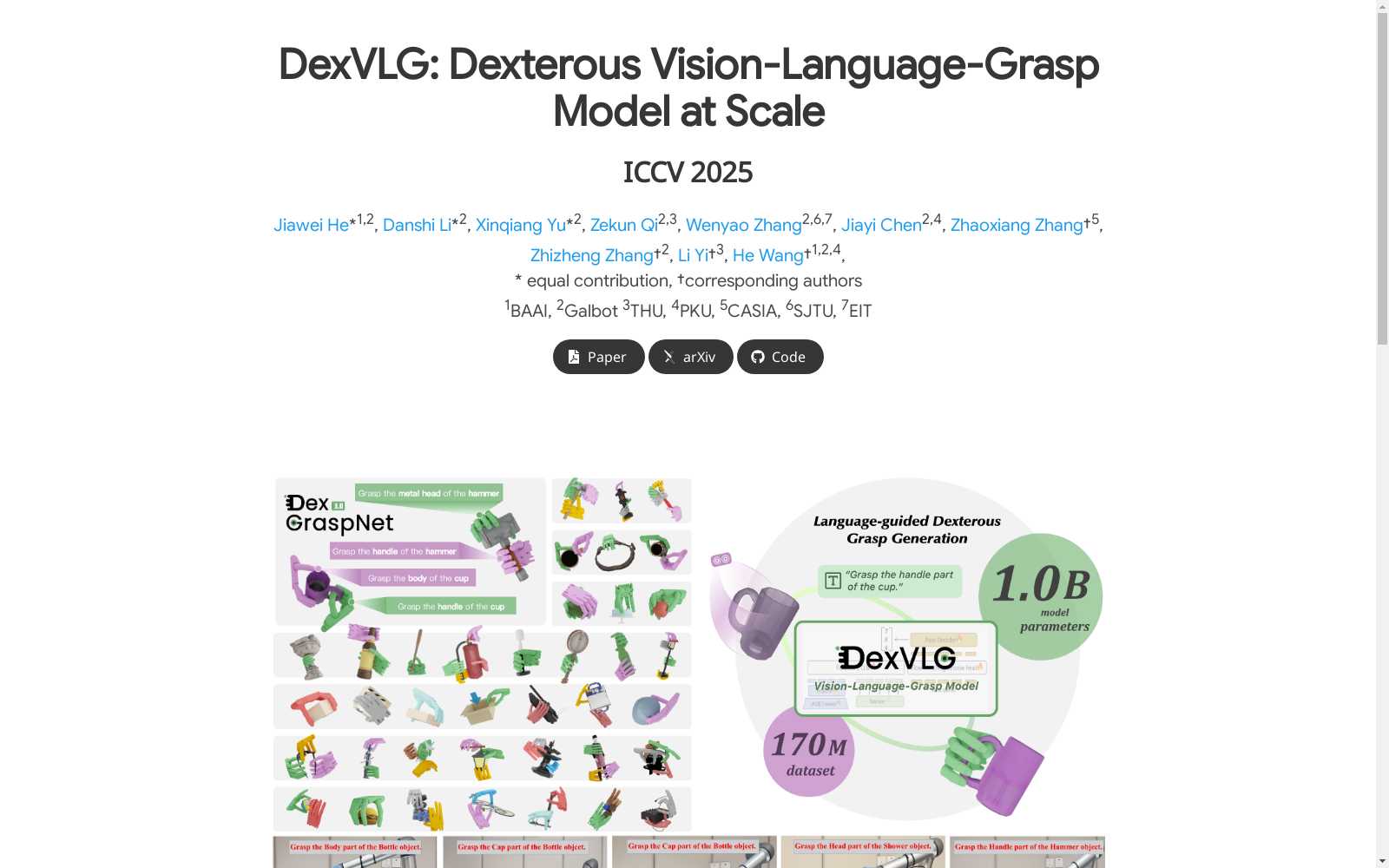
构建方式
DexGraspNet 3.0数据集通过大规模合成方法构建,涵盖了17亿个灵巧抓取姿态,覆盖了17.4万个物体。数据集的构建过程包括物体准备、语义分割、抓取姿态生成以及物理验证。首先,从Objaverse数据集中筛选并处理物体,利用SAMesh进行零样本几何分割,并通过GPT-4o生成语义标注。随后,采用基于梯度的优化方法生成抓取姿态,结合物理模拟验证其稳定性。每个抓取姿态均配有详细的语义描述,确保其功能性与人类抓取行为一致。
使用方法
DexGraspNet 3.0数据集主要用于训练和评估视觉-语言-动作模型,如DexVLG。用户可以通过输入单视角RGBD点云和语言指令,生成符合语义的灵巧抓取姿态。数据集还支持在仿真和真实环境中进行基准测试,评估模型的抓取成功率和语义对齐能力。此外,研究人员可利用数据集进行抓取生成、语义分割和多模态学习等任务的深入研究。
背景与挑战
背景概述
DexGraspNet 3.0是由BAAI、Galbot等机构的研究团队于2025年推出的一个大规模灵巧抓取数据集,旨在解决机器人灵巧手功能抓取的数据匮乏问题。该数据集包含1.7亿个灵巧抓取姿态,覆盖17.4万个Objaverse对象,每个姿态都通过物理仿真验证并配有描述抓取部位和风格的语义标注。作为首个融合视觉-语言-动作多模态信息的大规模灵巧抓取数据集,它突破了传统抓取数据仅关注力学稳定性的局限,将语义理解引入抓取生成领域,为构建通用机器人操作系统提供了关键数据支撑。
当前挑战
该数据集面临的核心挑战体现在两个方面:在领域问题层面,需解决灵巧手功能抓取的语义对齐难题,即如何根据语言指令精确抓取指定功能部位(如锤柄而非锤头);在构建过程层面,需克服大规模高质量抓取数据合成的技术瓶颈,包括基于物理的抓取稳定性验证、语义部位分割的一致性,以及多模态标注的自动化生成。特别地,将1.7亿个抓取姿态与174k对象的语义部位精准匹配,需要创新性地结合几何分析与语言模型的能力。
常用场景
经典使用场景
DexGraspNet 3.0数据集在机器人灵巧抓取领域具有广泛的应用场景,特别是在需要语义对齐和功能性抓取的任务中。该数据集通过模拟生成了1.7亿个灵巧抓取姿态,覆盖了17.4万个对象,每个抓取姿态都配有详细的语义描述和部分级注释。这使得DexGraspNet 3.0成为训练视觉-语言-抓取(VLG)模型的理想选择,尤其是在需要生成与语言指令对齐的抓取姿态的场景中。例如,在家庭服务机器人或工业自动化中,机器人需要根据用户的自然语言指令(如“抓住杯子的把手”)生成相应的抓取姿态。
解决学术问题
DexGraspNet 3.0解决了灵巧抓取领域中的多个关键学术问题。首先,它填补了大规模语义感知灵巧抓取数据集的空白,为研究语义对齐的抓取生成提供了丰富的数据支持。其次,该数据集通过结合物理模拟验证和语义标注,确保了抓取姿态的稳定性和语义准确性。此外,DexGraspNet 3.0还支持零样本泛化研究,使得模型能够在未见过的对象和部分上表现良好。这些特性为灵巧抓取的泛化能力和实际应用提供了重要的研究基础。
实际应用
在实际应用中,DexGraspNet 3.0数据集为机器人抓取任务的实现提供了强大的支持。例如,在家庭服务机器人中,机器人可以根据用户的指令(如“抓住锤子的金属头”)生成相应的抓取姿态,从而完成特定的功能性任务。在工业自动化中,该数据集可以用于训练机器人执行复杂的装配或搬运任务,提高生产效率和灵活性。此外,DexGraspNet 3.0还支持虚拟现实和增强现实中的交互应用,为用户提供更自然的物体操作体验。
数据集最近研究
最新研究方向
近年来,DexGraspNet 3.0数据集在机器人灵巧抓取领域引起了广泛关注。该数据集通过结合大规模合成数据和语言指令对齐的抓取姿态预测模型DexVLG,推动了视觉-语言-动作(VLA)系统在复杂任务中的应用。研究重点包括语义感知的灵巧抓取生成、基于物理仿真的抓取验证以及语言引导的抓取姿态优化。前沿方向聚焦于如何利用大规模预训练模型提升抓取的泛化能力,特别是在零样本场景下的表现。该数据集的出现填补了语义感知灵巧抓取数据稀缺的空白,为机器人操作任务提供了更接近人类行为范式的解决方案。
相关研究论文
- 1DexVLG: Dexterous Vision-Language-Grasp Model at ScaleBAAI, Galbot, THU, PKU, CASIA, SJTU, EIT · 2025年
以上内容由遇见数据集搜集并总结生成


