VALUENET
收藏arXiv2021-12-13 更新2024-06-21 收录
下载链接:
https://liang-qiu.github.io/ValueNet/
下载链接
链接失效反馈官方服务:
资源简介:
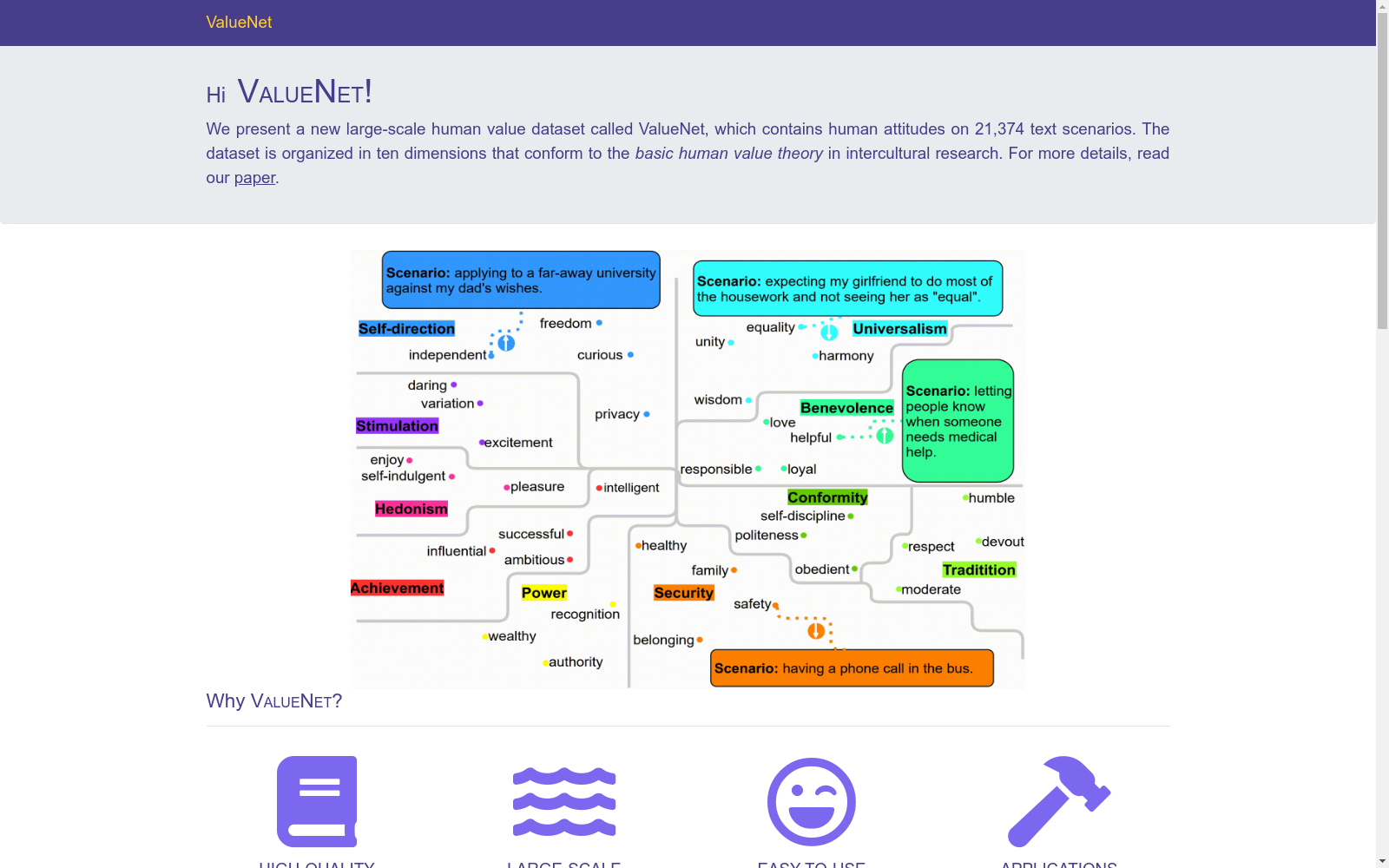
VALUENET是一个大规模的人类价值观数据集,由加州大学洛杉矶分校视觉、认知、学习和自主中心与微软研究院共同创建。该数据集包含21,374个文本场景,涉及十个与跨文化研究中基本人类价值观理论相符的维度。数据集通过精心策划的社会场景和关键词进行组织,旨在通过这些场景反映人类对不同价值观的态度。VALUENET的应用领域包括个性化对话生成和情感识别模型,旨在通过价值观模型提升对话系统的社会智能和情感智能,解决对话系统中价值观建模不足的问题。
VALUENET is a large-scale human values dataset co-created by the Center for Vision, Cognition, Learning and Autonomy at the University of California, Los Angeles and Microsoft Research. This dataset contains 21,374 text scenarios covering ten dimensions that align with the theory of basic human values in cross-cultural research. Organized through carefully curated social scenarios and keywords, it aims to reflect human attitudes towards different values via these scenarios. The application areas of VALUENET include personalized dialogue generation and emotion recognition models, which are designed to enhance the social and emotional intelligence of dialogue systems through value models, addressing the issue of insufficient value modeling in dialogue systems.
提供机构:
加州大学洛杉矶分校视觉、认知、学习和自主中心
创建时间:
2021-12-13
搜集汇总
数据集介绍
构建方式
VALUENET数据集的构建遵循了严谨的社会科学方法论与计算语言学技术的结合。其核心流程始于从大规模社会常识知识库SOCIAL-CHEM-101中,依据施瓦茨基本价值观理论定义的十个维度,通过词形还原、词干提取及GloVe词向量空间邻近性分析,系统性地检索出21,374个与价值观相关的社会场景文本。随后,研究团队通过亚马逊众包平台,设计了一套包含严格筛选机制和资格测试的标注流程,由经过培训的标注者对每个场景在特定价值观维度下的态度进行标注,最终通过多数同意原则保留高质量样本,形成了覆盖广泛日常社会情境的结构化知识库。
使用方法
该数据集的核心应用在于训练能够理解和建模人类价值观的计算模型。研究人员通常采用基于Transformer的预训练语言模型,通过定制化的输入格式,将社会场景文本与特定的价值观维度提示符相结合,进行回归或分类训练,以学习场景在十个价值观维度上的效用分布。训练得到的价值模型可作为通用模块,通过提供额外的价值特征,增强个性化对话生成、情感识别及共情回应生成等情感智能相关任务的性能。例如,在个性化对话任务中,价值模型输出的向量可用于计算智能体角色设定与生成回应之间的价值对齐度,并作为强化学习的奖励信号,引导生成更符合角色价值观的对话。
背景与挑战
背景概述
在对话系统研究领域,构建具备社会智能的代理体一直是核心目标之一,而人类价值观建模是实现这一目标的关键环节。VALUENET数据集由加州大学洛杉矶分校视觉、认知、学习与自主中心与微软研究院的研究团队于2021年共同创建,旨在填补价值观驱动对话系统研究的数据空白。该数据集基于跨文化研究中施瓦茨基本价值观理论构建,收录了21,374个文本场景的人类态度标注,涵盖自我导向、普遍主义等十个维度。其核心研究问题在于如何量化并建模人类价值观,以指导对话系统生成符合特定价值取向的响应,从而推动个性化对话生成、共情响应等任务的发展,为构建具有深层社会认知能力的对话系统奠定了数据基础。
当前挑战
VALUENET数据集面临的挑战主要体现在两个层面。在领域问题层面,其旨在解决的价值观建模任务本身具有高度抽象性和主观性,如何将模糊的人类价值概念转化为可计算的连续效用分布,并确保模型在不同文化语境下的泛化能力,构成了首要的理论与方法论挑战。在构建过程层面,数据收集依赖于众包平台标注,但价值观判断易受标注者个人背景影响,导致初始标注者间一致性仅为64.9%;同时,不同价值维度的样本数量存在显著不均衡,例如仁慈维度样本过多,而享乐主义维度样本较少,这种分布偏差可能影响模型学习的公平性与全面性。此外,如何设计有效的提示机制引导预训练语言模型关注特定价值维度,亦是模型构建中的技术难点。
常用场景
经典使用场景
在对话系统与情感计算领域,VALUENET数据集为构建基于人类价值观的智能体提供了关键支撑。其最经典的应用场景在于训练和评估能够理解并遵循施瓦茨基本价值观理论的对话模型。研究者利用该数据集中的两万余条社会场景标注,训练Transformer架构的价值回归模型,从而量化文本在十个价值维度上的效用分布。这种价值建模使得对话系统能够超越表层语义,深入理解话语背后的人类动机与偏好,为生成符合特定价值导向的回应奠定基础。
解决学术问题
VALUENET数据集有效解决了对话系统中人类价值观显式建模缺失的核心学术问题。传统研究多集中于常识推理或社会规范,而该数据集首次将跨文化研究中成熟的施瓦茨价值观理论大规模引入自然语言处理领域。它使得研究者能够定量分析文本如何促进或威胁特定价值目标,从而将抽象的价值概念转化为可计算的效用分数。这一工作填补了情感智能对话系统中价值驱动建模的空白,为理解人格、态度与话语之间的深层关联提供了可操作的数据与模型框架。
实际应用
该数据集的实际应用主要体现在提升个性化与共情对话系统的性能上。通过将从VALUENET学习到的价值模型作为奖励函数,结合强化学习对生成式对话代理进行微调,在PERSONA-CHAT数据集上实现了最先进的个性化对话生成效果。同时,将价值向量作为额外特征融入情感识别模型,显著提升了在EMPATHETICDIALOGUES数据集上的情绪分类准确率,进而改善了共情回应的生成质量。这些应用展示了价值模型在使对话系统更具社会意识与用户适配性方面的实用潜力。
数据集最近研究
最新研究方向
在对话系统领域,VALUENET数据集正推动前沿研究聚焦于价值驱动的人工智能交互。该数据集基于施瓦茨基本价值理论,构建了涵盖21,374个社会场景的多维度知识库,为探索人类价值在自然语言处理中的建模提供了新范式。当前研究热点集中于利用Transformer架构学习价值效用分布,并将其整合至情感智能对话任务中,例如通过强化学习优化个性化对话生成,在PERSONA-CHAT数据集上实现性能突破;同时,价值特征作为辅助信息显著提升了共情对话中的情绪识别准确率,进而增强响应生成质量。这些进展不仅深化了对人类价值与语言行为关联的理解,也为构建更具社会意识与伦理对齐的对话系统奠定了数据与理论基础,标志着对话智能从功能导向向价值感知演进的关键一步。
相关研究论文
- 1ValueNet: A New Dataset for Human Value Driven Dialogue System加州大学洛杉矶分校视觉、认知、学习和自主中心 · 2021年
以上内容由遇见数据集搜集并总结生成


