有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
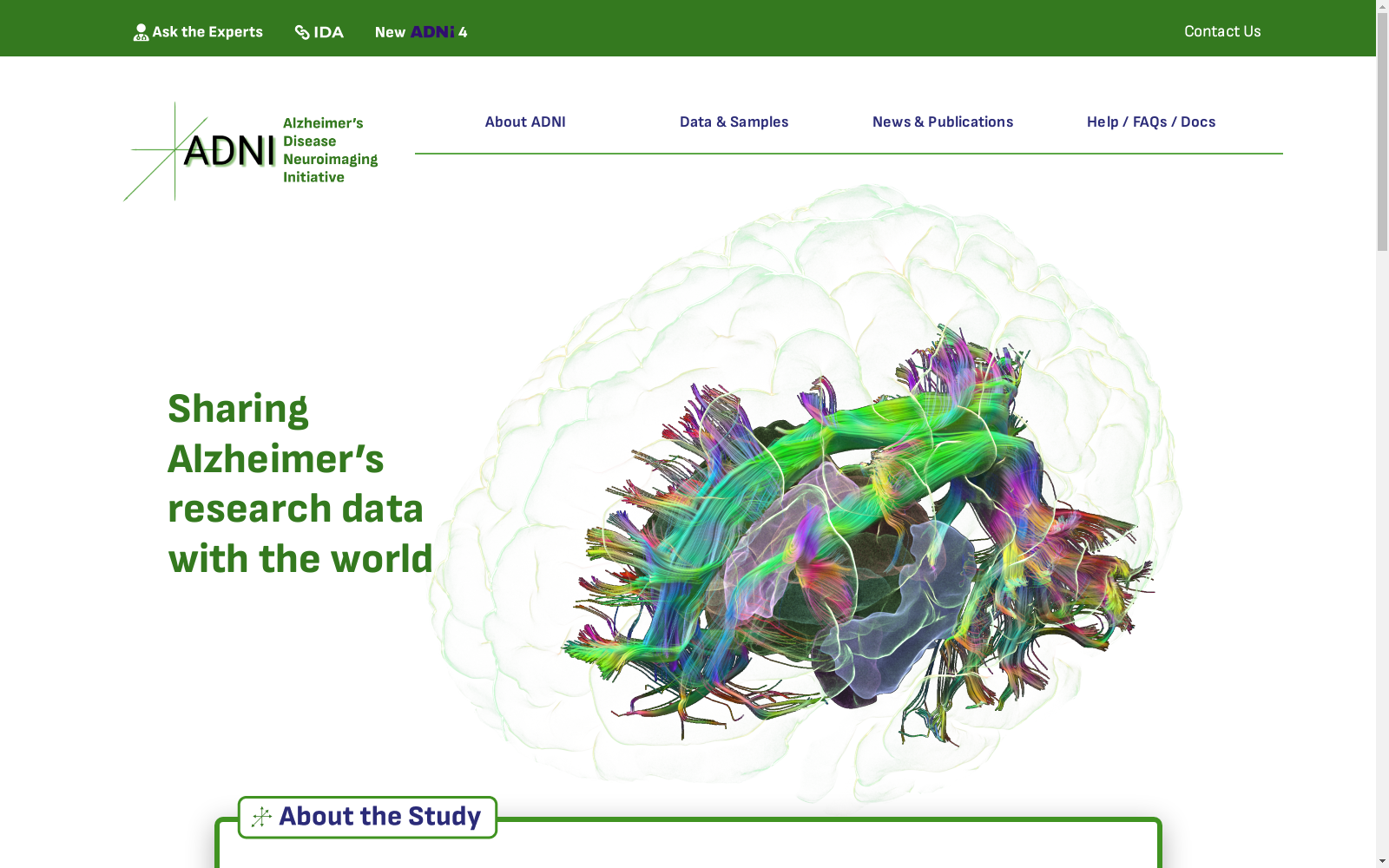
中国区域地面气象要素驱动数据集 v2.0(1951-2024)
中国区域地面气象要素驱动数据集(China Meteorological Forcing Data,以下简称 CMFD)是为支撑中国区域陆面、水文、生态等领域研究而研发的一套高精度、高分辨率、长时间序列数据产品。本页面发布的 CMFD 2.0 包含了近地面气温、气压、比湿、全风速、向下短波辐射通量、向下长波辐射通量、降水率等气象要素,时间分辨率为 3 小时,水平空间分辨率为 0.1°,时间长度为 74 年(1951~2024 年),覆盖了 70°E~140°E,15°N~55°N 空间范围内的陆地区域。CMFD 2.0 融合了欧洲中期天气预报中心 ERA5 再分析数据与气象台站观测数据,并在辐射、降水数据产品中集成了采用人工智能技术制作的 ISCCP-ITP-CNN 和 TPHiPr 数据产品,其数据精度较 CMFD 的上一代产品有显著提升。 CMFD 历经十余年的发展,其间发布了多个重要版本。2019 年发布的 CMFD 1.6 是完全采用传统数据融合技术制作的最后一个 CMFD 版本,而本次发布的 CMFD 2.0 则是 CMFD 转向人工智能技术制作的首个版本。此版本与 1.6 版具有相同的时空分辨率和基础变量集,但在其它诸多方面存在大幅改进。除集成了采用人工智能技术制作的辐射和降水数据外,在制作 CMFD 2.0 的过程中,研发团队尽可能采用单一来源的再分析数据作为输入并引入气象台站迁址信息,显著缓解了 CMFD 1.6 中因多源数据拼接和气象台站迁址而产生的虚假气候突变。同时,CMFD 2.0 数据的时间长度从 CMFD 1.6 的 40 年大幅扩展到了 74 年,并将继续向后延伸。CMFD 2.0 的网格空间范围虽然与 CMFD 1.6 相同,但其有效数据扩展到了中国之外,能够更好地支持跨境区域研究。为方便用户使用,CMFD 2.0 还在基础变量集之外提供了若干衍生变量,包括近地面相对湿度、雨雪分离降水产品等。此外,CMFD 2.0 摒弃了 CMFD 1.6 中通过 scale_factor 和 add_offset 参数将实型数据化为整型数据的压缩技术,转而直接将实型数据压缩存储于 NetCDF4 格式文件中,从而消除了用户使用数据时进行解压换算的困扰。 本数据集原定版本号为 1.7,但鉴于本数据集从输入数据到研制技术都较上一代数据产品有了大幅的改变,故将其版本号重新定义为 2.0。CMFD 2.0 的数据内容与此前宣传的 CMFD 1.7 基本一致,仅对 1983 年 7 月以后的向下短/长波辐射通量数据进行了更新,以修正其长期趋势存在的问题。
国家青藏高原科学数据中心 收录
MeSH
MeSH(医学主题词表)是一个用于索引和检索生物医学文献的标准化词汇表。它包含了大量的医学术语和概念,用于描述医学文献中的主题和内容。MeSH数据集包括主题词、副主题词、树状结构、历史记录等信息,广泛应用于医学文献的分类和检索。
www.nlm.nih.gov 收录
lmarena-ai/arena-hard-auto-v0.1
--- license: apache-2.0 dataset_info: features: - name: question_id dtype: string - name: category dtype: string - name: cluster dtype: string - name: turns list: - name: content dtype: string splits: - name: train num_bytes: 251691 num_examples: 500 download_size: 154022 dataset_size: 251691 configs: - config_name: default data_files: - split: train path: data/train-* --- ## Arena-Hard-Auto **Arena-Hard-Auto-v0.1** ([See Paper](https://arxiv.org/abs/2406.11939)) is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries sourced from Chatbot Arena. We prompt GPT-4-Turbo as judge to compare the models' responses against a baseline model (default: GPT-4-0314). Notably, Arena-Hard-Auto has the highest *correlation* and *separability* to Chatbot Arena among popular open-ended LLM benchmarks ([See Paper](https://arxiv.org/abs/2406.11939)). If you are curious to see how well your model might perform on Chatbot Arena, we recommend trying Arena-Hard-Auto. Please checkout our GitHub repo on how to evaluate models using Arena-Hard-Auto and more information about the benchmark. If you find this dataset useful, feel free to cite us! ``` @article{li2024crowdsourced, title={From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline}, author={Li, Tianle and Chiang, Wei-Lin and Frick, Evan and Dunlap, Lisa and Wu, Tianhao and Zhu, Banghua and Gonzalez, Joseph E and Stoica, Ion}, journal={arXiv preprint arXiv:2406.11939}, year={2024} } ```
hugging_face 收录
danaroth/icvl
ICVL是一个高光谱图像数据集,由Specim PS Kappa DX4高光谱相机和旋转平台进行空间扫描采集。数据集目前包含200张图像,并且会逐步增加。图像的空间分辨率为1392×1300,覆盖519个光谱波段(400-1000nm,间隔约1.25nm)。数据集提供了ENVI格式的原始数据和MAT格式的下采样数据(31个光谱通道,400-700nm,间隔10nm)。原始数据集仅包含干净的图像,用于高光谱图像去噪的测试数据来自另一篇论文。
hugging_face 收录
Global Burden of Disease (GBD)
全球疾病负担数据库(Global Burden of Disease,GBD)是一个全球性的健康数据平台,旨在提供详尽的健康数据资源,涵盖调查、人口普查、生命统计等多方面信息,为全球健康研究提供重要支持。该数据库可通过其官方网站访问,为非商业用户免费提供数据下载、共享、修改及二次开发等服务,但需遵循 IHME 免费非商业用户协议,商业用途需咨询 IHME 条款和条件。GBD 2021 数据及所有 IHME 数据均在此平台提供,是健康数据研究者的重要资源。
ghdx.healthdata.org 收录