tatsu-lab/alpaca
收藏Hugging Face2023-05-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/tatsu-lab/alpaca
下载链接
链接失效反馈官方服务:
资源简介:
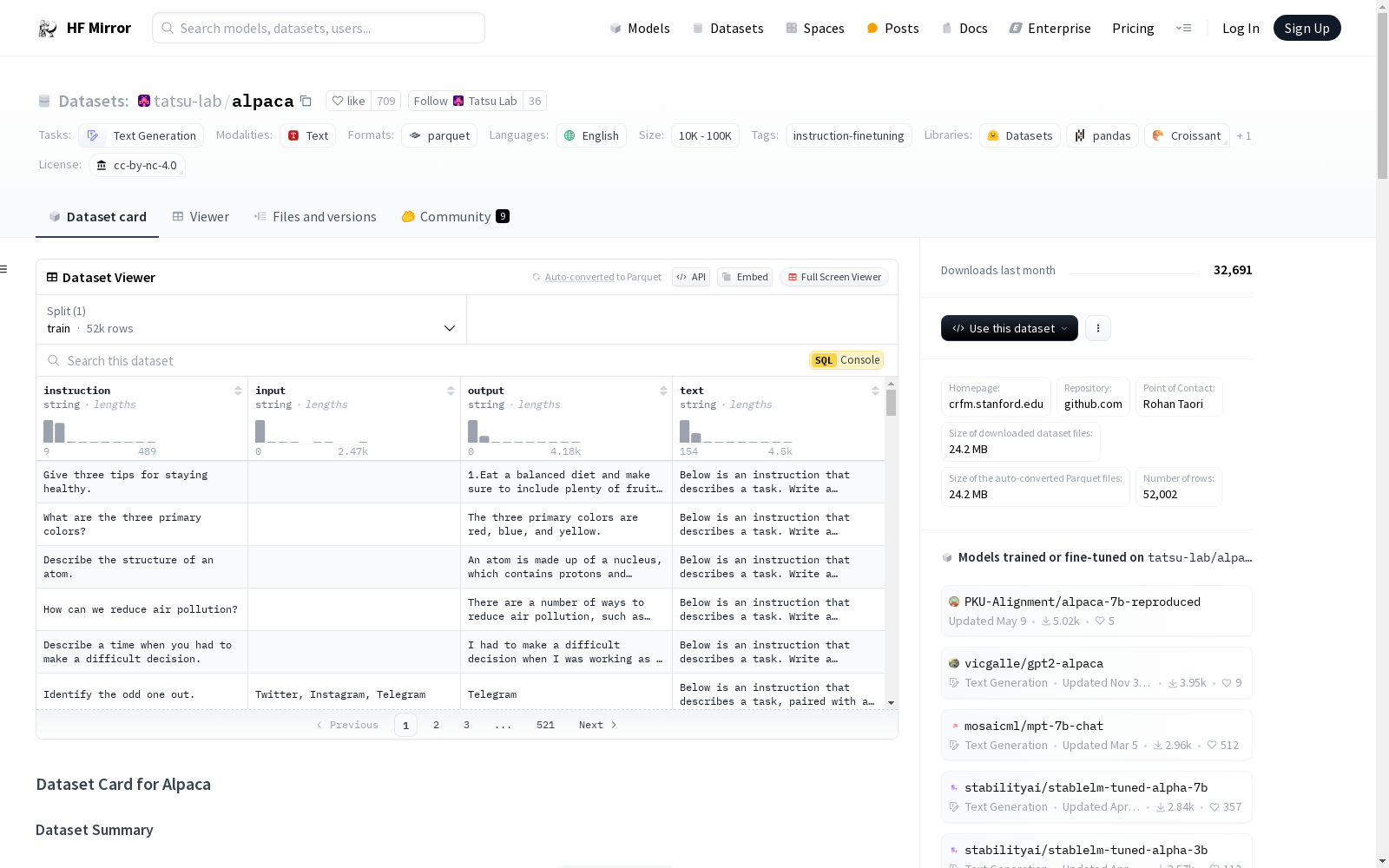
Alpaca数据集是一个包含52,000条指令和演示的数据集,这些数据由OpenAI的`text-davinci-003`引擎生成。该数据集用于指令微调语言模型,使其更好地遵循指令。数据集的生成基于Self-Instruct框架,并进行了多项修改,包括使用`text-davinci-003`引擎、编写新的提示、采用更激进的批量解码、简化数据生成管道以及为每个指令生成单个实例。这些修改显著降低了数据生成的成本,并提高了数据的多样性。数据集的结构包括指令、输入、输出和格式化文本。数据集的使用考虑了社会影响和潜在风险,并采取了相应的风险缓解措施。
The Alpaca dataset is a collection of 52,000 instructions and demonstrations generated by OpenAI's `text-davinci-003` engine. It is designed for instruction tuning of language models to enable them to better follow given instructions. Developed based on the Self-Instruct framework, the dataset incorporates several modifications, including adopting the `text-davinci-003` engine, crafting new prompts, employing more aggressive batch decoding, simplifying the data generation pipeline, and generating a single instance per instruction. These modifications have significantly reduced the cost of data generation and improved the diversity of the dataset. The structure of the dataset includes instructions, inputs, outputs, and formatted text. During the utilization of this dataset, social impacts and potential risks have been taken into consideration, and corresponding risk mitigation measures have been implemented.
提供机构:
tatsu-lab
原始信息汇总
数据集概述:Alpaca
数据集描述
- 数据集名称: Alpaca
- 数据集概要: Alpaca是一个包含52,000条指令和演示的数据集,由OpenAI的
text-davinci-003引擎生成。该数据集主要用于语言模型的指令微调,以提高模型遵循指令的能力。 - 语言: 英语(BCP-47 en)
- 许可: 创意共享非商业性许可(CC BY-NC 4.0)
数据集结构
数据实例
- 示例: json { "instruction": "Create a classification task by clustering the given list of items.", "input": "Apples, oranges, bananas, strawberries, pineapples", "output": "Class 1: Apples, Oranges Class 2: Bananas, Strawberries Class 3: Pineapples", "text": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
Instruction:
Create a classification task by clustering the given list of items.
Input:
Apples, oranges, bananas, strawberries, pineapples
Response:
Class 1: Apples, Oranges Class 2: Bananas, Strawberries Class 3: Pineapples", }
数据字段
- instruction: 描述模型应执行的任务,每个指令都是唯一的。
- input: 任务的上下文或输入,约40%的示例包含此字段。
- output:
text-davinci-003生成的指令答案。 - text: 使用作者提供的模板格式化的
instruction、input和output。
数据分割
- 训练集: 52002条记录
数据集创建
数据生成
- 生成引擎: 使用
text-davinci-003引擎生成指令数据。 - 生成策略: 采用更积极的批量解码,一次生成20条指令,显著降低数据生成成本。
- 数据简化: 简化数据生成流程,不再区分分类和非分类指令,每个指令仅生成一个实例。
使用考虑
社会影响
- 风险与利益: 发布此数据集可能带来风险,如增加有害内容传播的可能性,但同时也为学术界提供了进行指令遵循语言模型研究的工具。
- 风险缓解措施: 实施内容过滤和输出水印技术,以及严格的非商业使用条款。
数据局限性
- 数据质量: 由于数据由语言模型生成,可能包含错误或偏见,建议用户谨慎使用并探索改进方法。
搜集汇总
数据集介绍
构建方式
Alpaca数据集由52,000条指令和演示组成,这些数据是通过OpenAI的`text-davinci-003`引擎生成的。构建过程中,研究者基于[Self-Instruct框架](https://github.com/yizhongw/self-instruct)进行了改进,主要调整包括使用`text-davinci-003`引擎替代`davinci`,设计了新的提示模板,采用更激进的批量解码策略,简化了数据生成流程,并减少了每个指令的实例数量。这些改进使得数据集的生成成本大幅降低,仅为500美元以下,同时生成的数据在多样性上显著优于Self-Instruct框架发布的数据。
特点
Alpaca数据集的主要特点在于其高度的多样性和低成本生成。数据集包含52,000条独特的指令,涵盖了广泛的文本生成任务。此外,数据集的生成过程经过优化,减少了分类与非分类任务之间的差异,并简化了数据生成流程,使得数据集在结构上更加统一和高效。尽管数据由语言模型生成,可能存在一定的错误或偏见,但其多样性和低成本特性使其成为指令微调语言模型的理想选择。
使用方法
Alpaca数据集主要用于预训练语言模型的指令微调,旨在提升模型遵循指令的能力。用户可以通过加载数据集并使用其中的`instruction`、`input`和`output`字段进行模型训练。数据集的结构设计使得用户能够轻松地将指令与相应的输入和输出配对,从而进行有效的模型微调。此外,数据集的提示模板可用于进一步优化模型的训练过程,确保模型能够更好地理解和执行各种文本生成任务。
背景与挑战
背景概述
Alpaca数据集由斯坦福大学的Tatsu-Lab团队于2023年创建,旨在通过52,000条由OpenAI的`text-davinci-003`引擎生成的指令和示例,提升语言模型在指令遵循任务中的表现。该数据集基于Self-Instruct框架,通过简化数据生成流程和采用更高效的批量解码技术,显著降低了数据生成成本。Alpaca的发布不仅为学术界提供了用于指令调优的标准数据集,还推动了对指令遵循语言模型的深入研究,有望在语言模型的指令理解和生成能力上取得突破。
当前挑战
Alpaca数据集在构建过程中面临的主要挑战包括:首先,如何通过优化生成流程降低数据生成成本,同时保持数据的多样性和质量;其次,如何确保生成的指令数据能够有效提升语言模型的指令遵循能力。此外,尽管Alpaca数据集在初步研究中表现出较高的多样性,但其由语言模型生成,不可避免地存在错误和偏见,这要求用户在使用时需谨慎,并探索新的方法来过滤和改进数据中的不完美之处。
常用场景
经典使用场景
Alpaca数据集的经典使用场景主要集中在语言模型的指令微调任务中。通过提供52,000条独特的指令及其对应的生成结果,该数据集能够帮助预训练语言模型更好地理解和执行用户指令。具体而言,研究者可以利用Alpaca数据集对模型进行微调,使其在面对复杂任务时表现出更高的准确性和多样性,从而提升模型的实用性和泛化能力。
解决学术问题
Alpaca数据集解决了语言模型在指令遵循方面的常见学术问题。传统的语言模型在处理多样化指令时往往表现不佳,而Alpaca通过大规模的指令生成和微调,显著提升了模型对复杂指令的理解和执行能力。这不仅推动了指令微调技术的发展,还为后续研究提供了高质量的数据基础,有助于探索更先进的模型训练方法和评估标准。
衍生相关工作
Alpaca数据集的发布催生了一系列相关研究工作,特别是在指令微调和语言模型性能提升方面。许多研究者基于Alpaca数据集开发了新的微调方法和模型架构,进一步提升了语言模型在指令遵循任务中的表现。此外,Alpaca的成功也激发了对大规模指令生成技术的深入研究,推动了数据生成和模型训练技术的创新与发展。
以上内容由遇见数据集搜集并总结生成


