wikiHow-TIIR
收藏arXiv2025-02-18 更新2025-02-20 收录
下载链接:
https://github.com/vec-ai/wikiHow-TIIR
下载链接
链接失效反馈官方服务:
资源简介:
wikiHow-TIIR数据集是基于wikiHow教程构建的,包含15万个交错式文本-图像文档的检索语料库。该数据集通过特定的管道利用大型语言模型和文本到图像生成器自动生成交错式查询。数据集在构建过程中,通过人工标注和筛选生成了7654个高质量的查询-文档对作为测试集,其余生成的查询作为训练集。该数据集旨在解决文本-图像交错式检索任务,推动相关研究的进展。
The wikiHow-TIIR dataset is constructed based on wikiHow tutorials, which encompasses a retrieval corpus of 150,000 interleaved text-image documents. It automatically generates interleaved queries via a dedicated pipeline leveraging large language models (LLMs) and text-to-image generators. During the dataset construction process, 7,654 high-quality query-document pairs were generated as the test set through manual annotation and screening, while the remaining generated queries were used as the training set. This dataset aims to address the interleaved text-image retrieval task and promote the advancement of relevant research.
提供机构:
哈尔滨工业大学, 香港理工大学
创建时间:
2025-02-18
搜集汇总
数据集介绍
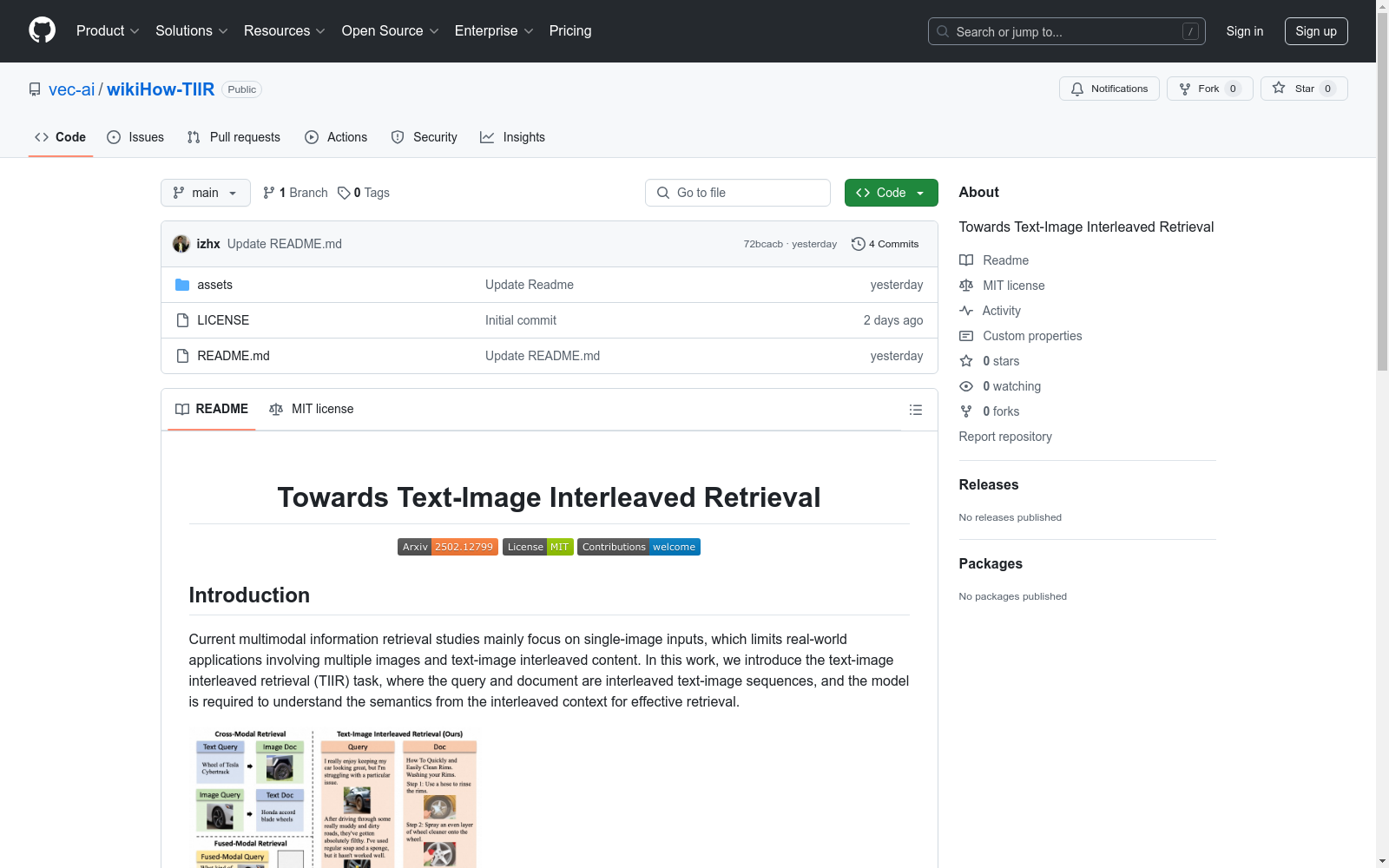
构建方式
为了解决现有多模态信息检索研究主要关注单一图像输入的问题,本研究提出了文本-图像交错检索(TIIR)任务,并构建了基于自然交错wikiHow教程的TIIR基准。通过设计特定的流水线,该基准能够生成交错的查询,从而使得模型能够理解交错上下文的语义,实现有效的检索。为了探索TIIR任务,研究团队对几个现成的检索器进行了适配,并构建了一个基于交错的 multimodal large language model (MLLM) 的密集基线。此外,还提出了一个新的 Matryoshka Multimodal Embedder (MME),用于解决 MLLM 基于的 TIIR 模型中视觉标记过多的挑战。
使用方法
使用该数据集时,需要遵循以下步骤:1) 数据预处理:对数据进行清洗、标注和过滤,确保数据的准确性和一致性;2) 模型训练:使用数据集训练 TIIR 模型,例如 MME,以实现更准确的检索;3) 模型评估:使用数据集中的测试集对模型进行评估,以验证模型的有效性和效率。
背景与挑战
背景概述
在多模态信息检索领域,当前的研究主要集中在单一图像输入上,这限制了在涉及多图像和文本-图像交错内容的现实世界应用中的应用。为了解决这一问题,研究人员Xin Zhang等人提出了文本-图像交错检索(TIIR)任务,其中查询和文档是交错的文本-图像序列,模型需要理解交错上下文的语义以实现有效检索。为了探索这一任务,他们基于自然交错的wikiHow教程构建了一个TIIR基准,并设计了一种特定的流程来生成交错查询。为了进一步研究,他们还对现有的检索器进行了适应性调整,并构建了一个基于交错的跨模态大型语言模型(MLLM)的密集基线。此外,他们还提出了一种新颖的Matryoshka多模态嵌入器(MME),该嵌入器以不同的粒度压缩视觉标记的数量,以解决基于MLLM的TIIR模型中视觉标记过多的问题。实验结果表明,现有模型的简单调整并不能始终如一地产生有效结果。与基线相比,MME通过显著减少视觉标记实现了显著的改进。他们提供了广泛的分析,并将发布数据集和代码以促进未来的研究。
当前挑战
TIIR任务面临的主要挑战包括:1)现有检索器难以有效地处理多图像和文本-图像交错内容;2)构建基于交错的MLLM的TIIR模型时,视觉标记数量过多导致计算效率低下和视觉信息在嵌入空间中的主导地位。为了解决这些问题,研究人员提出了MME,该嵌入器以不同的粒度压缩视觉标记的数量,以生成更有效的嵌入,从而提高TIIR模型的性能和效率。
常用场景
经典使用场景
wikiHow-TIIR数据集主要用于文本-图像交错检索任务,其中查询和文档都是交错排列的文本-图像序列。该数据集的经典使用场景包括但不限于:在电子商务搜索中,用户可以通过上传多张图片和文字描述来更准确地表达他们的信息需求,系统可以根据这些信息检索到最相关的商品信息;在信息检索增强生成(RAG)系统中,用户可以通过上传多张图片和文字描述来更准确地表达他们的信息需求,系统可以根据这些信息检索到最相关的文档信息。
解决学术问题
wikiHow-TIIR数据集解决了当前多模态信息检索研究中存在的单图像输入的限制问题,提出了文本-图像交错检索(TIIR)任务。该数据集通过构建基于自然交错wikiHow教程的TIIR基准,并设计了一个特定的流程来生成交错查询,从而有效地解决了多模态信息检索中的多图像和文本-图像交错内容检索问题。同时,该数据集还提出了一个新颖的Matryoshka Multimodal Embedder(MME)模型,该模型能够有效地处理多模态大语言模型(MLLM)中过多的视觉标记问题,从而提高了模型的检索效果和效率。
实际应用
wikiHow-TIIR数据集的实际应用场景包括但不限于:在电子商务搜索中,用户可以通过上传多张图片和文字描述来更准确地表达他们的信息需求,系统可以根据这些信息检索到最相关的商品信息;在信息检索增强生成(RAG)系统中,用户可以通过上传多张图片和文字描述来更准确地表达他们的信息需求,系统可以根据这些信息检索到最相关的文档信息。此外,该数据集还可以用于其他需要多模态信息检索的场景,如科学内容检索、视觉文档检索等。
数据集最近研究
最新研究方向
在多模态信息检索领域,wikiHow-TIIR数据集的提出标志着对文本-图像交错检索(TIIR)任务的深入研究。该数据集的构建旨在解决当前多模态检索研究中主要关注单一图像输入的问题,限制了涉及多图像和文本-图像交错内容的应用。通过将wikiHow教程转换为检索语料库,并设计一个高效的数据生成流程,该数据集为TIIR任务提供了一个基准。此外,研究团队还提出了一种名为Matryoshka Multimodal Embedder(MME)的新型检索模型,该模型通过压缩不同粒度的视觉标记数量来应对多模态大型语言模型(MLLM)中视觉标记过多的挑战。实验结果表明,MME模型在检索性能和效率方面都取得了显著提升。这项研究不仅为TIIR任务提供了新的研究方向,也为多模态检索的未来发展提供了有价值的见解。
相关研究论文
- 1Towards Text-Image Interleaved Retrieval哈尔滨工业大学, 香港理工大学 · 2025年
以上内容由遇见数据集搜集并总结生成


