VIDGEN-1M
收藏arXiv2024-08-06 更新2024-08-07 收录
下载链接:
https://sais-fuxi.github.io/projects/vidgen-1m
下载链接
链接失效反馈官方服务:
资源简介:
VIDGEN-1M是由复旦大学和上海人工智能科学院联合创建的大型视频文本生成数据集,包含100万个高质量视频片段及其详细描述性合成字幕。该数据集通过多阶段精细筛选流程创建,确保了视频与字幕间的高时空一致性。数据集内容涵盖广泛,字幕平均长度为89.3字,能准确捕捉视频中的动态元素。VIDGEN-1M主要用于训练和评估文本到视频生成模型,旨在提高模型生成视频的质量和准确性。
VIDGEN-1M is a large-scale video-text generation dataset jointly created by Fudan University and Shanghai AI Laboratory. It contains 1 million high-quality video clips and their detailed descriptive synthetic subtitles. Constructed through a multi-stage meticulous screening pipeline, this dataset ensures high spatiotemporal consistency between the videos and their corresponding subtitles. The dataset covers a wide range of content, with an average subtitle length of 89.3 words, which can accurately capture the dynamic elements in the videos. VIDGEN-1M is primarily used for training and evaluating text-to-video generation models, aiming to improve the quality and accuracy of model-generated videos.
提供机构:
复旦大学 上海人工智能科学院
创建时间:
2024-08-06
搜集汇总
数据集介绍
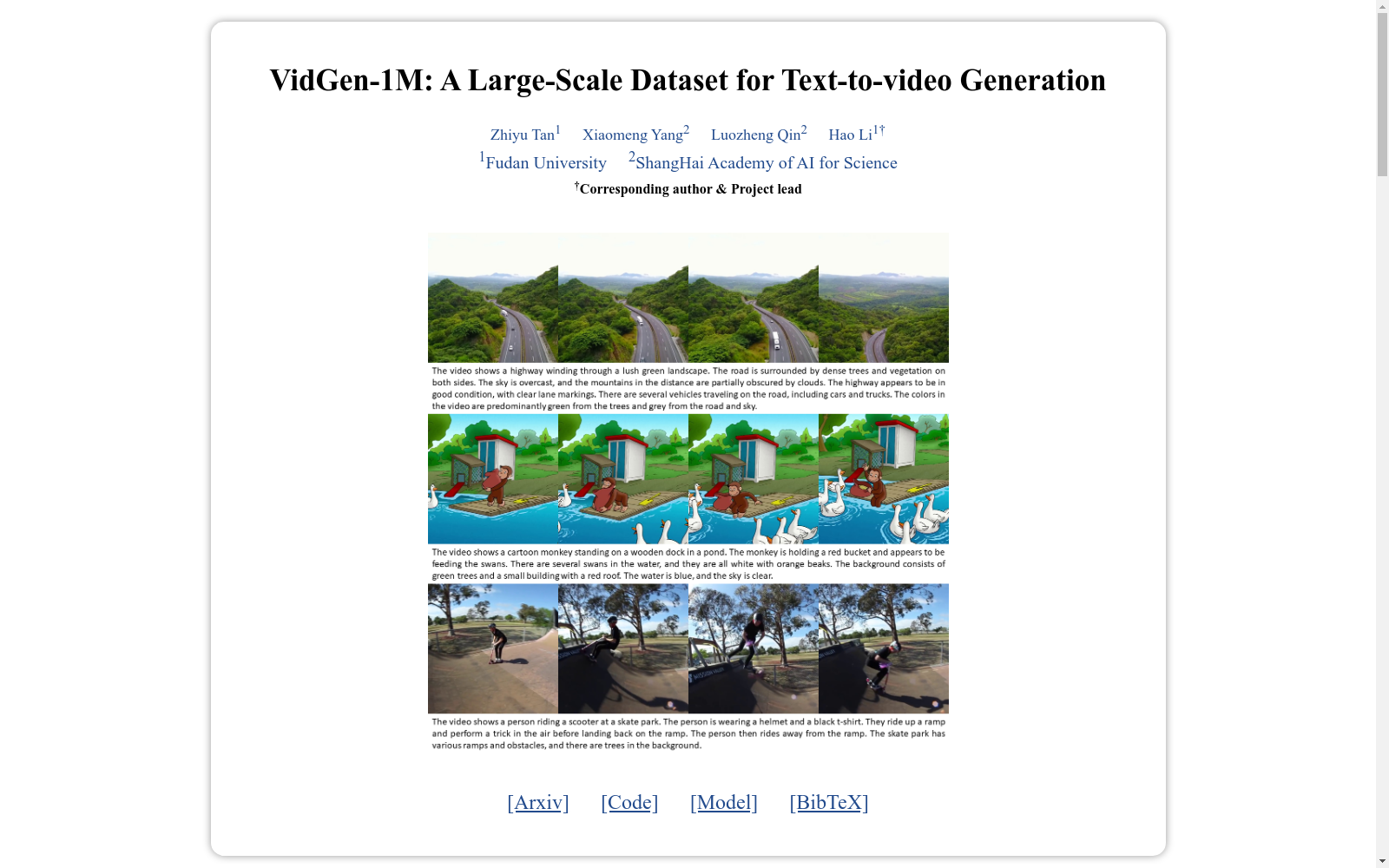
构建方式
VIDGEN-1M数据集的构建过程采用了多阶段的数据筛选策略,首先进行粗略筛选,包括场景分割、视频标记、过滤和采样,以减少后续阶段的计算负担。随后进入字幕生成阶段,利用VILA模型为视频生成描述性字幕。最后进行精细筛选,采用大型语言模型LLAMA3.1进一步校准视频字幕,确保文本与视频的一致性和时间一致性。
使用方法
使用VIDGEN-1M数据集训练文本到视频生成模型时,首先需要对模型进行预训练,以便模型能够理解和生成高质量的视频内容。随后,将模型与VIDGEN-1M数据集进行联合训练,使模型能够学习到丰富的语义和视觉信息,从而生成更真实、更高质量的动态视频内容。
背景与挑战
背景概述
在文本到视频生成领域,高质量的视频-文本对对于训练文本到视频模型至关重要。然而,现有的用于训练这些模型的视频-文本数据集存在一些显著的缺点,包括低时间一致性、低质量的标题、低质量的视频和失衡的数据分布。VIDGEN-1M数据集的创建旨在解决这些问题,它是一个大规模的数据集,包含高质量的、开放领域的视频和详细的描述性标题,旨在为文本到视频模型提供更好的训练数据。
当前挑战
VIDGEN-1M数据集的创建面临的主要挑战包括:1)现有数据集的低质量标题,缺乏与视频的一致性和详细的描述;2)现有数据集的低质量视频,影响模型生成的视频质量;3)时间不一致性,导致模型训练不稳定;4)数据失衡,主要是由来自互联网的视频组成,导致数据分布不均。为了解决这些问题,VIDGEN-1M数据集采用了粗到细的数据筛选策略,确保了高质量的视频和详细的时间一致的标题。
常用场景
经典使用场景
VIDGEN-1M数据集主要用于训练文本到视频的生成模型。该数据集通过粗到精的编辑策略,确保了高质量的视频和详细的字幕,具有优异的时间一致性。当用于训练视频生成模型时,该数据集的实验结果超越了其他模型,是训练文本到视频生成模型的理想选择。
解决学术问题
VIDGEN-1M数据集解决了现有视频文本数据集存在的几个问题,包括字幕质量低、视频质量差、时间不一致和数据不平衡。这些问题的存在导致训练文本到视频生成模型时出现不稳定训练和性能差的问题。VIDGEN-1M数据集通过其高质量的视频和详细的字幕,以及优异的时间一致性,有效解决了这些问题,为文本到视频生成模型的训练提供了更准确和详细的数据。
实际应用
VIDGEN-1M数据集在实际应用中具有广泛的应用前景。它可以用于训练各种视频生成模型,如Latte、SORA、OpenSora和W.A.L.T等。此外,VIDGEN-1M数据集还可以用于视频检索、视频理解和视频生成等领域的研究。通过提供高质量的视频和详细的字幕,VIDGEN-1M数据集有助于提高视频生成模型的效果,推动视频生成技术的发展。
数据集最近研究
最新研究方向
VIDGEN-1M数据集的推出,标志着文本到视频生成领域的重要进展。该数据集通过精心设计的数据处理流程,确保了视频的高质量、详细的文本描述以及时间一致性,从而显著提升了文本到视频生成模型的表现。VIDGEN-1M的引入,解决了现有数据集中存在的低质量描述、低视频质量、时间不一致和数据不平衡等问题,为研究者提供了更为精准和全面的训练数据。这一数据集的发布,有望推动文本到视频生成模型在真实世界场景中的应用,例如视频内容创作、视频编辑和视频摘要生成等。VIDGEN-1M数据集的构建方法和高质量特性,也为未来大规模视频文本数据集的创建提供了重要的参考和借鉴。
相关研究论文
- 1VidGen-1M: A Large-Scale Dataset for Text-to-video Generation复旦大学 上海人工智能科学院 · 2024年
以上内容由遇见数据集搜集并总结生成


