semanta-crypto-assets
收藏Hugging Face2026-05-17 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/SemantaAI/semanta-crypto-assets
下载链接
链接失效反馈官方服务:
资源简介:
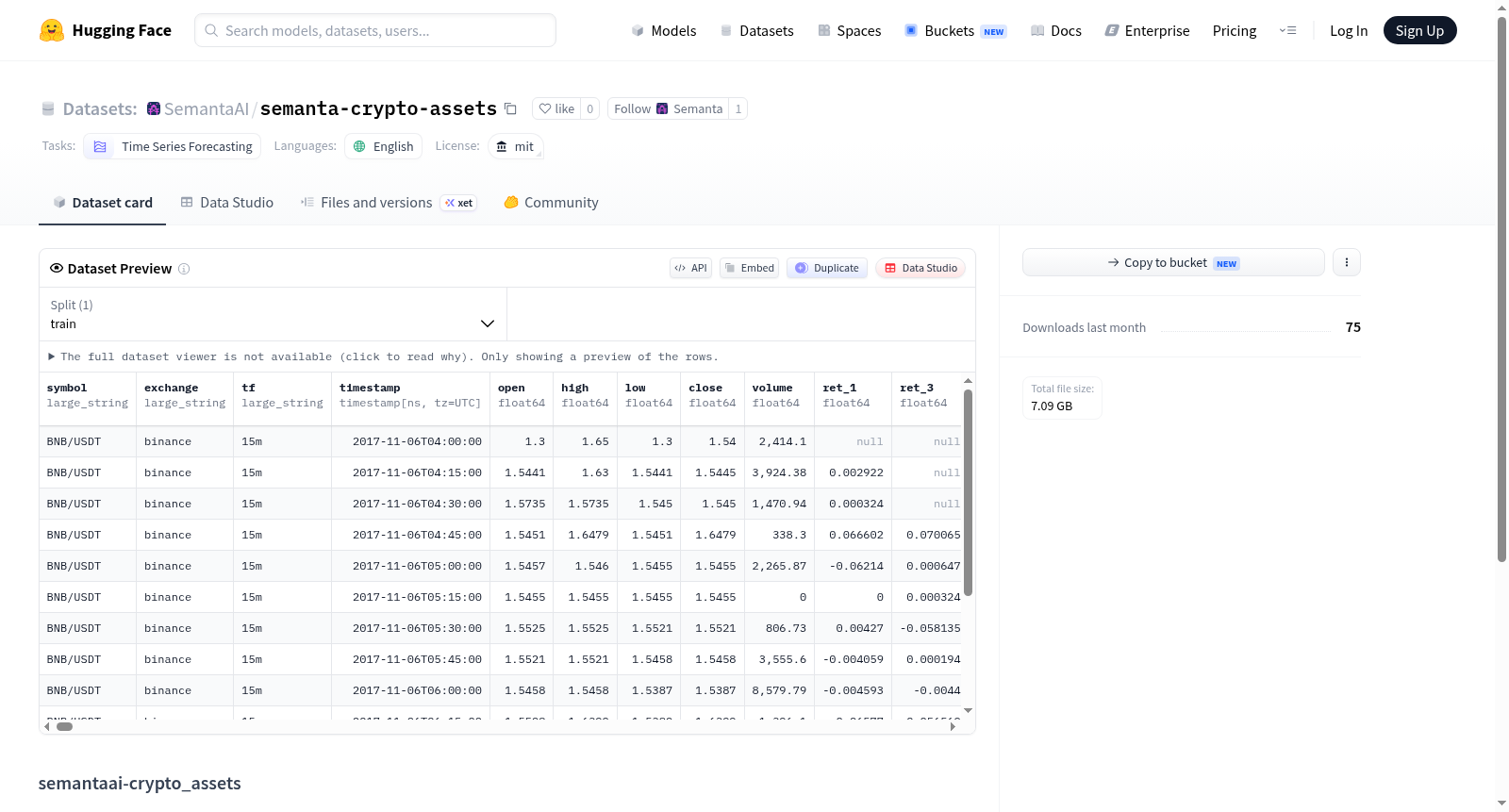
semantaai-crypto_assets 是一个由 Semanta AI 提供的加密货币市场数据集,采用统一的 raw(原始)和 gold(标准/精炼)双格式标准。数据集包含 4,182,508 行 raw 数据和 6,026,532 行 gold 数据,最后更新时间为 UTC 2026-05-17T11:39:09.295802+00:00,目标结束时间为 UTC 2026-05-17T23:55:00+00:00。该数据集主要用于时间序列预测任务,语言为英语。
semantaai-crypto_assets is a cryptocurrency market dataset provided by Semanta AI, adopting a unified dual-format standard of raw (original) and gold (standard/refined). The dataset contains 4,182,508 rows of raw data and 6,026,532 rows of gold data, with the last update time at UTC 2026-05-17T11:39:09.295802+00:00 and a target end time of UTC 2026-05-17T23:55:00+00:00. This dataset is primarily used for time series forecasting tasks, and the language is English.
创建时间:
2026-05-12
搜集汇总
数据集介绍
构建方式
该数据集由Semanta AI构建,旨在提供统一标准的加密货币市场数据。其构建方式融合了原始数据(raw)与精炼数据(gold)两种形态,前者保留了未经处理的初始市场记录,后者则经过清洗与标准化处理,以提升数据质量与一致性。数据条目分别达到4182508行和6026532行,覆盖广泛的市场活动。更新机制基于UTC时间戳,目标截止时间为2026年5月17日,确保了时间序列的完整性与时效性,为时序预测任务奠定了坚实基础。
特点
数据集最显著的特点在于其双重标准架构,即同时提供raw与gold两种版本,分别满足不同分析需求。raw版本适用于原始信号挖掘与自定义清洗,而gold版本则直接用于模型训练与评估。此外,其规模宏大,包含数百万行记录,具备高密度时间点覆盖,支持细粒度时序分析。数据集以英文标注,遵循MIT许可证开放使用,降低了学术与商业应用的门槛,凸显了其通用性与可访问性。
使用方法
该数据集专为时间序列预测任务设计,适用于加密货币价格、交易量等市场指标的建模与验证。使用时,用户可根据需求选择raw或gold版本:若需自定义预处理流程,应优先采用raw数据;若追求高效性与标准化,可直接加载gold数据开展实验。数据以统一格式存储,便于集成至主流机器学习框架(如PyTorch、TensorFlow)中。建议结合分时切割与滚动窗口策略,以适配预测模型对序列依赖性的要求。
背景与挑战
背景概述
在数字资产与加密货币市场蓬勃发展的背景下,高频金融时间序列数据成为量化分析与预测的核心基础。Semanta AI 研究团队于2026年发布了 semanta-crypto-assets 数据集,旨在为加密货币市场的时序预测任务提供统一化、高质量的标准化数据资源。该数据集整合了原始(raw)与黄金标准(gold)两种层级,涵盖超过四百万条原始记录与六百万条经过清洗标注的高质量样本,数据截止至2026年5月17日,为相关领域的算法验证与模型训练提供了极具规模与权威性的基准。作为面向时序预测的专业数据集,它填补了加密货币领域缺乏统一公开高质量数据集的空白,推动了金融时间序列分析、资产价格波动建模及风险管理等方向的研究进展。
当前挑战
该数据集所解决的领域核心挑战在于加密货币市场的高噪声、非平稳性与数据质量一致性不足。一方面,市场受政策、舆情与交易者情绪等多重因素影响,时间序列呈现复杂非线性特征,传统统计模型难以捕捉其动态规律,亟需统一的高频基准数据以支撑深度学习等先进建模方法。另一方面,数据构建过程中面临原始数据存在缺失、异常值与时间戳不一致等问题,需设计稳健的清洗与对齐流程,从超过四百万条原始记录中提炼出六百万余条优质样本,并确保跨交易所数据格式与时间频次的标准化,这对数据整合与质量控制提出了极高要求。
常用场景
经典使用场景
在加密资产时间序列预测这一前沿领域,semanta-crypto-assets数据集以其规范的raw与gold双标准格式,为研究者提供了统一的市场数据基石。该数据集涵盖海量历史行情记录,原始数据行数逾418万,经质量清洗后的黄金标准数据行数更超过602万,时间跨度直至2026年5月。研究人员可将其用于构建多尺度价格预测模型,例如通过长短期记忆网络或Transformer架构捕捉加密货币价格波动的时序依赖模式,抑或利用注意力机制挖掘不同资产间的联动效应,从而在分钟级粒度上实现收益率与波动率的精准预判。
衍生相关工作
围绕semanta-crypto-assets数据集,学术界与工业界已衍生出多项标志性研究工作。在模型层面,研究者基于该数据开发了融合图神经网络与因果推断的加密资产收益预测框架,在解释模型的可解释性方面取得突破;在数据工程领域,有团队利用raw与gold标准间的统计差异提出了自适应数据清洗管道,显著提升了训练数据的信噪比。此外,该数据集还被用于验证对抗性攻击对时间序列模型的影响,以及评估联邦学习在隐私保护型加密资产预测中的可行性,这些衍生工作共同推动了加密资产数据分析方法的体系化与标准化。
数据集最近研究
最新研究方向
该数据集聚焦于加密资产领域的高频时间序列预测,通过提供统一规范的原始数据与标准化黄金数据集,为加密货币市场波动建模、交易策略优化及风险评估奠定了坚实基础。随着2026年全球加密市场规模的持续扩张与监管框架的日趋完善,此类高质量、大容量的时序数据在量化金融与人工智能交叉研究中扮演着关键角色。当前前沿方向包括利用深度学习模型捕捉非平稳市场特征、挖掘多资产间的隐性关联,以及构建鲁棒性更强的异常检测系统,以应对高波动环境下的市场冲击,推动金融科技在去中心化资产数据分析中的创新应用。
以上内容由遇见数据集搜集并总结生成


