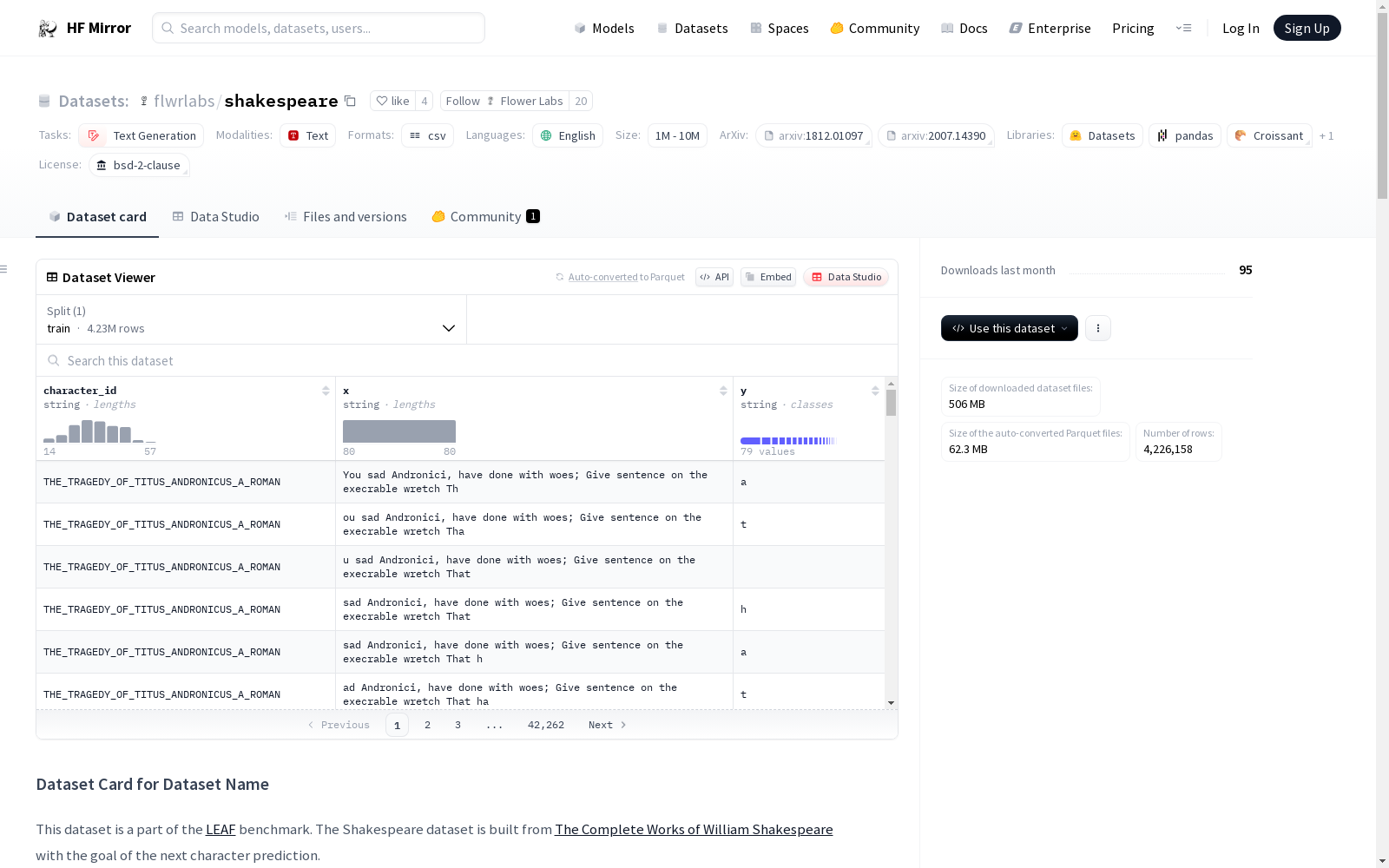
flwrlabs/shakespeare
收藏数据集卡片
数据集详情
数据集描述
- 数据集名称: Shakespeare
- 数据集来源: LEAF
- 语言: 英语
- 许可证: BSD 2-Clause License
- 数据集大小: 1M<n<10M
- 任务类别: 文本生成
数据集结构
-
数据文件:
shakespeare.csvsplit: train
-
数据列:
character_id: str - 表示角色和剧目的唯一ID(在联邦学习设置中表示节点)x: str - 80个字符的文本y: str - 紧随x的单个字符
数据集用途
- 直接用途: 该数据集设计用于联邦学习(FL)设置。推荐使用Flower Dataset和Flower框架。
数据集创建
- 创建理由: 作为LEAF基准测试的一部分。
- 源数据: The Complete Works of William Shakespeare
- 源数据生产者: William Shakespeare
数据集分割
- 数据集分割: 仅包含训练集分割。分割在每个节点上进行(无集中式数据集)。
数据集引用
- BibTeX:
@article{DBLP:journals/corr/abs-1812-01097, author = {Sebastian Caldas and Peter Wu and Tian Li and Jakub Kone{v{c}}n{y} and H. Brendan McMahan and Virginia Smith and Ameet Talwalkar}, title = {{LEAF:} {A} Benchmark for Federated Settings}, journal = {CoRR}, volume = {abs/1812.01097}, year = {2018}, url = {http://arxiv.org/abs/1812.01097}, eprinttype = {arXiv}, eprint = {1812.01097}, timestamp = {Wed, 23 Dec 2020 09:35:18 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-1812-01097.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
@article{DBLP:journals/corr/abs-2007-14390, author = {Daniel J. Beutel and Taner Topal and Akhil Mathur and Xinchi Qiu and Titouan Parcollet and Nicholas D. Lane}, title = {Flower: {A} Friendly Federated Learning Research Framework}, journal = {CoRR}, volume = {abs/2007.14390}, year = {2020}, url = {https://arxiv.org/abs/2007.14390}, eprinttype = {arXiv}, eprint = {2007.14390}, timestamp = {Mon, 03 Aug 2020 14:32:13 +0200}, biburl = {https://dblp.org/rec/journals/corr/abs-2007-14390.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }