haizelabs/calligraphy-bench
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/haizelabs/calligraphy-bench
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: "Calligraphy Bench: Can AI Write Chinese Calligraphy?"
language:
- zh
- en
license: apache-2.0
size_categories:
- n<1K
task_categories:
- image-to-image
tags:
- calligraphy
- benchmark
- evaluation
- agent
- tldraw
- chinese
- art
dataset_info:
config_name: default
splits:
- name: test
---
# Calligraphy Bench
**Can AI agents draw Chinese calligraphy stroke-by-stroke?**
88 of the hardest Chinese characters from 20 master calligraphers, drawn by 4 frontier AI agents on a tldraw canvas using programmatic stroke commands. Each output is evaluated on stroke correctness, stroke ordering, visual fidelity, and pairwise preference ranking.
## Task
Given a reference calligraphy image (provided as a vision message — no file access), an AI agent must:
1. Draw the character stroke-by-stroke via MCP tools (`create_stroke`, `update_stroke`, etc.)
2. Control position, pressure (thick-thin variation), and size for each stroke
3. Capture and submit the final output via `save_document`
No tracing, no bitmap copying, no image generation models — only programmatic strokes on a tldraw canvas through MCP tools.
## Models Evaluated
| Model | Stroke Recall | Stroke Order | Fidelity | Pairwise Win Rate |
|-------|:---:|:---:|:---:|:---:|
| GPT-5.4 | 86% | 82% | 2.2/5 | **75%** |
| Claude Opus 4.6 | 89% | 77% | 1.6/5 | 60% |
| Kimi K2.5 | 83% | 79% | 1.3/5 | 34% |
| GLM-5 | 71% | 78% | 1.3/5 | 30% |
## Evaluation Metrics
- **Stroke Recall**: What fraction of reference strokes does the agent reproduce? (vision judge)
- **Stroke Order**: Of matched strokes, what fraction are drawn in correct canonical order? (vision judge)
- **Fidelity Verdict**: 1-5 scale comparing visual similarity to reference (vision judge)
- **Pairwise Win Rate**: Head-to-head comparison using MJ1 judge (Tinker, round-robin all pairs)
## Data Fields
- `task_id`: Unique identifier for the character+calligrapher combination
- `character`: The Chinese character
- `pinyin`: Romanized pronunciation
- `definition`: English meaning
- `stroke_count`: Number of canonical strokes
- `style_difficulty`: 1-5 difficulty rating
- `calligrapher`: Name of the master calligrapher
- `reference_image`: Original calligraphy by the master calligrapher
Each row is one character (88 total). This dataset contains only task inputs — model outputs and evaluation results are available on the [benchmark website](https://calligraphybench.com).
## Usage
```python
from datasets import load_dataset
ds = load_dataset("haizelabs/calligraphy-bench", split="test")
print(f"{len(ds)} characters")
# Browse tasks
for row in ds:
print(f"{row['character']} ({row['pinyin']}) — {row['calligrapher']}, {row['stroke_count']} strokes")
```
## Harness
Agents are run via [OpenHands SDK](https://github.com/All-Hands-AI/OpenHands) with MCP tools on a tldraw canvas. To submit your model for evaluation, contact [Haize Labs](https://haizelabs.com).
## Citation
```bibtex
@misc{calligraphy-bench-2026,
title={Calligraphy Bench: Can AI Write Chinese Calligraphy?},
year={2026},
url={https://huggingface.co/datasets/haizelabs/calligraphy-bench}
}
```
提供机构:
haizelabs
搜集汇总
数据集介绍
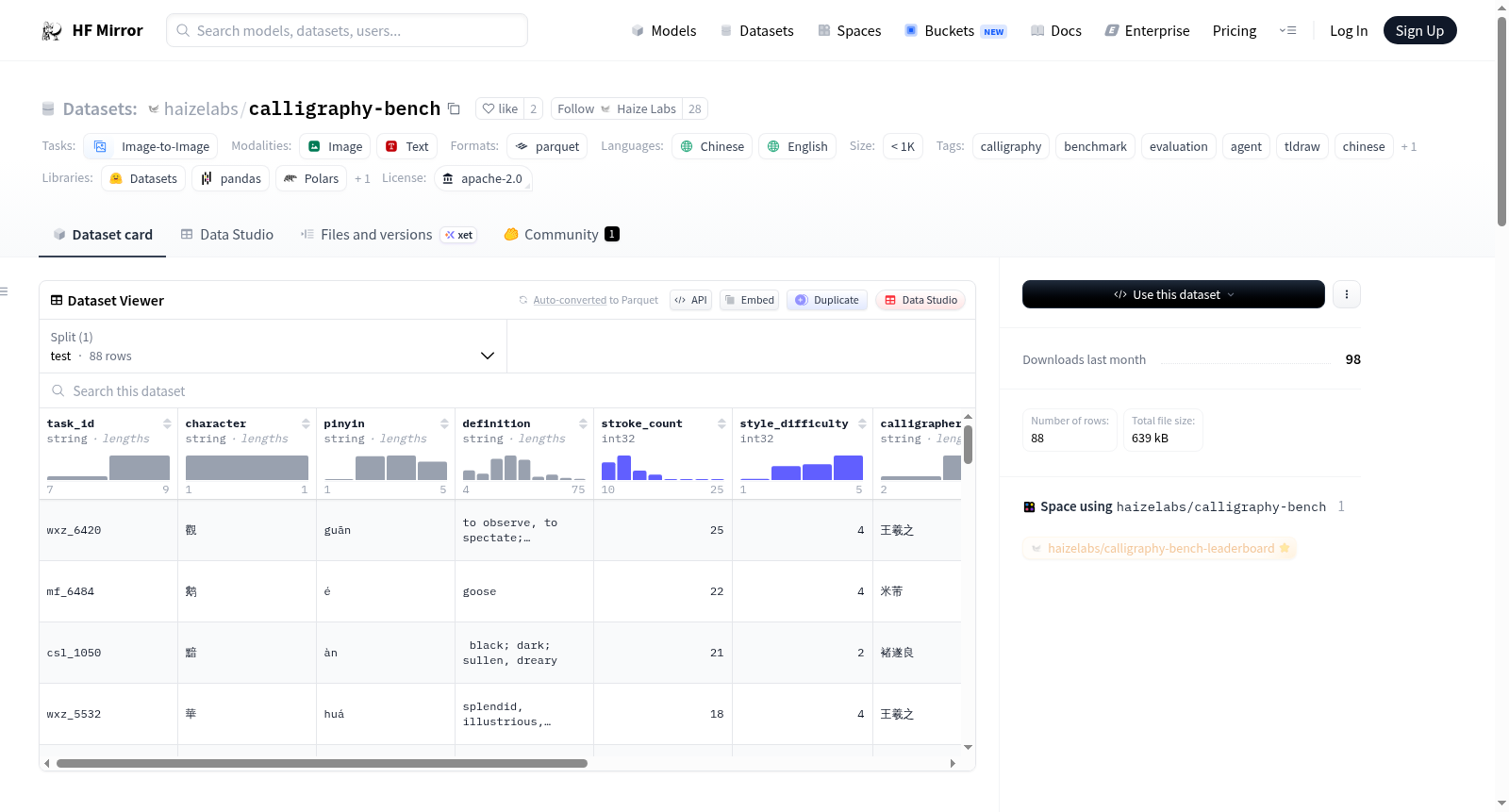
构建方式
在书法艺术与人工智能交叉领域,Calligraphy Bench数据集精心选取了20位书法大师笔下的88个最具挑战性的汉字,构建了一个专注于笔画级复现的评估基准。数据集的构建过程严格遵循程序化笔画生成原则,通过tldraw画布上的MCP工具(如create_stroke、update_stroke)记录笔画命令,完全避免了图像追踪或位图复制。每个字符均附有拼音、英文释义、标准笔画数及风格难度评级,确保了任务定义的清晰性与可操作性。
特点
该数据集的核心特点在于其多维度、细粒度的评估体系,涵盖了笔画召回率、笔画顺序正确性、视觉保真度以及成对偏好排名四大指标。数据集不仅提供了书法大师的原始作品作为视觉参考,还限定了智能体必须通过程序化指令逐笔绘制,从而精准检验模型对书法笔画结构、笔压变化与空间布局的理解能力。其小规模(少于1000样本)但高难度的设计,使其成为衡量前沿AI智能体在复杂艺术创作任务上性能的试金石。
使用方法
研究人员可通过Hugging Face的datasets库直接加载数据集,便捷地访问所有字符任务及其元数据。使用OpenHands SDK结合MCP工具在tldraw画布上运行智能体,即可进行模型评估或任务复现。数据集本身仅包含任务输入,完整的模型输出与评估结果需参考基准网站。该设计鼓励开发者遵循严格的程序化笔画生成范式,推动AI在传统艺术形式上的精确复现与创造性理解。
背景与挑战
背景概述
在人工智能与数字艺术交叉领域,模拟人类精细动作与审美表达一直是一项前沿挑战。Calligraphy Bench数据集于2026年由Haize Labs研究团队创建,核心研究问题是评估AI智能体能否以程序化笔触逐笔绘制中国书法。该数据集精选了20位书法大师的88个高难度汉字,要求AI通过MCP工具在tldraw画布上控制笔画的位点、压力与尺寸,从而推动具身智能在文化遗产数字化与创造性任务中的能力边界,为多模态AI的精细动作生成与艺术理解设立了新的基准。
当前挑战
该数据集旨在解决图像到笔触序列生成的领域挑战,即要求AI从静态书法图像中解构出正确的笔画数量、顺序及动态笔压特征,而非简单进行图像分类或生成。构建过程中的挑战包括:从历代名家作品中筛选兼具艺术价值与结构复杂度的字符;建立可量化评估笔画召回率、顺序正确性与视觉保真度的多维度评价体系;以及设计一套禁止使用位图复制或图像生成模型、仅允许通过程序化笔触工具交互的严格测试框架,以确保评估聚焦于AI的结构化理解与执行能力。
常用场景
经典使用场景
在人工智能与数字艺术交叉领域,Calligraphy Bench数据集为评估AI代理的笔画级生成能力提供了基准。该数据集的核心应用场景在于,要求AI代理依据给定的书法参考图像,通过程序化工具在画布上逐笔绘制汉字,模拟人类书法家的创作过程。这一过程不仅测试了模型对视觉信息的解析能力,更强调了其对笔画顺序、位置、压力变化等精细控制的理解,为研究智能体在结构化艺术任务中的表现设立了标准化的测试环境。
衍生相关工作
围绕Calligraphy Bench数据集,已衍生出一系列聚焦于AI艺术生成与评估的经典研究工作。这些工作主要沿着两个方向展开:一是开发更先进的视觉-动作规划模型与多模态智能体架构,以提升在笔画级控制任务上的性能;二是构建更精细、更全面的评估体系,例如引入人类审美偏好的大规模众包评估,或结合更复杂的几何与风格相似性度量。这些研究共同推动了AI在理解与生成非西方书写系统及结构化艺术形式方面的技术进步。
数据集最近研究
最新研究方向
在数字艺术与人工智能交叉领域,Calligraphy Bench数据集正推动智能体对复杂视觉任务的程序化生成能力研究。该数据集聚焦于中国书法这一富含文化内涵的艺术形式,要求AI模型通过笔画级指令在画布上精确重构字符,而非依赖图像生成技术。前沿探索集中在多模态智能体的空间推理与运动规划上,如何将视觉输入转化为连贯的笔画序列成为核心挑战。研究热点涉及智能体对笔压、顺序及形态的细粒度控制,旨在超越传统图像生成,实现更具解释性与可控性的艺术创作。这一方向不仅检验了AI对结构化艺术的理解深度,也为机器人书写、文化遗产数字化等应用提供了新的评估基准。
以上内容由遇见数据集搜集并总结生成


