Dexterous World Models (DWM) dataset
收藏arXiv2025-12-20 更新2025-12-23 收录
下载链接:
https://snuvclab.github.io/dwm/
下载链接
链接失效反馈官方服务:
资源简介:
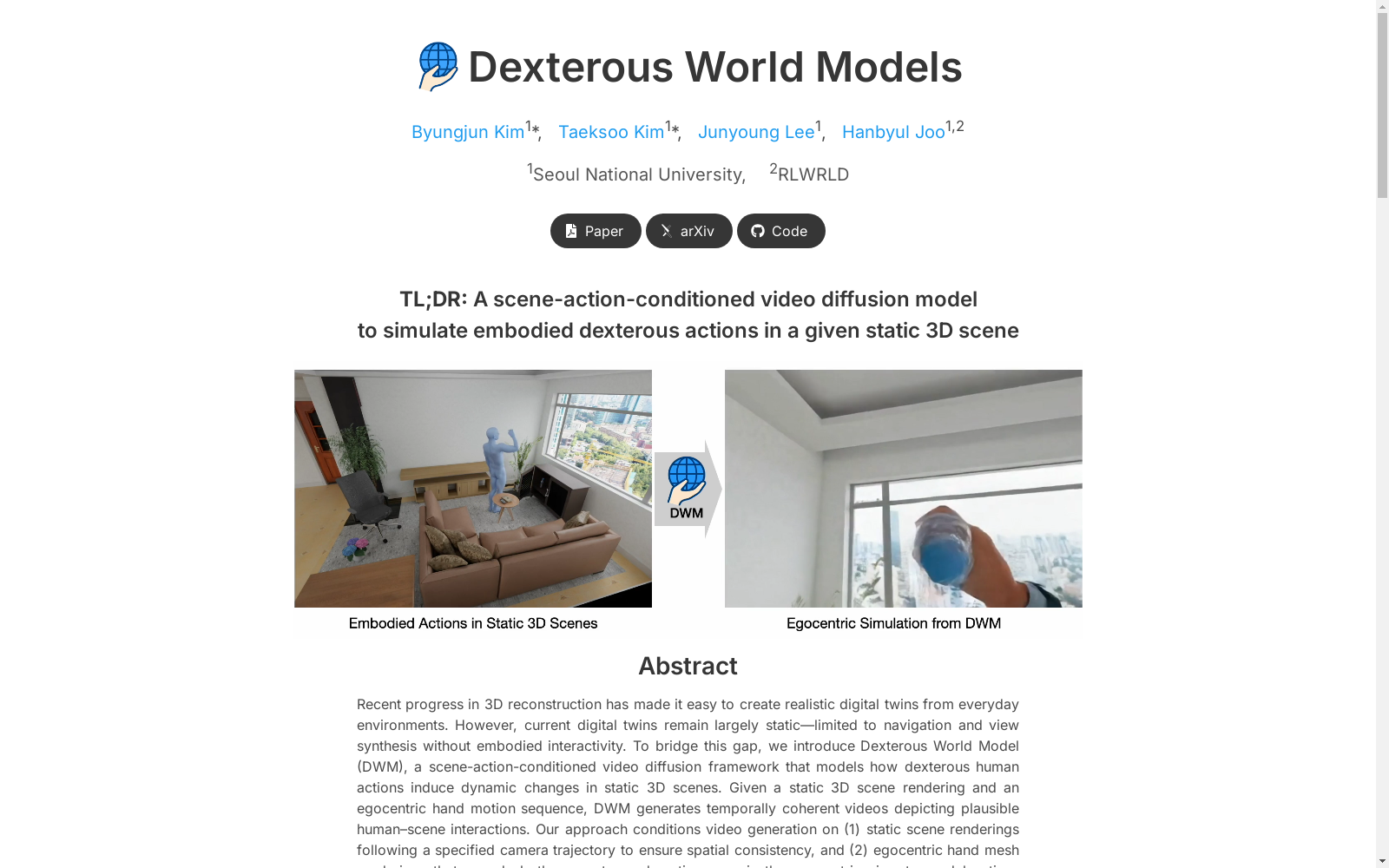
Dexterous World Models (DWM)数据集由首尔国立大学的研究团队构建,旨在支持静态3D场景中灵巧手部动作驱动的视觉动态建模。该数据集包含合成的自我中心视角交互视频、静态场景视频和手部视频,以及固定摄像头的真实世界交互视频,以提供精确对齐和多样化的交互动态。数据集的构建过程涉及从静态3D场景渲染和手部运动序列生成对齐的交互视频,以训练视频扩散模型。该数据集主要应用于交互式数字孪生和视觉世界建模领域,旨在解决静态3D场景中灵巧手部动作驱动的动态变化预测问题。
The Dexterous World Models (DWM) dataset was constructed by a research team from Seoul National University, aiming to support visually dynamic modeling driven by dexterous hand movements in static 3D scenes. This dataset includes synthetic egocentric interactive videos, static scene videos, hand videos, as well as real-world interactive videos captured by fixed cameras, to provide precisely aligned and diverse interaction dynamics. The construction process of the dataset involves rendering static 3D scenes and generating aligned interactive videos via hand motion sequences, for training video diffusion models. This dataset is mainly applied in the fields of interactive digital twins and visual world modeling, aiming to address the problem of predicting dynamic changes driven by dexterous hand movements in static 3D scenes.
提供机构:
首尔国立大学
创建时间:
2025-12-20
搜集汇总
数据集介绍
构建方式
在构建灵巧世界模型数据集的过程中,研究者面临静态三维场景渲染与动态交互视频在相同相机轨迹下对齐的挑战。为此,他们采用了一种混合数据构建策略,结合合成数据与真实世界视频的优势。具体而言,利用TRUMANS合成数据集,通过控制人体动作、场景状态和相机轨迹,生成了精确对齐的交互视频、静态场景视频和手部网格视频三元组。同时,引入固定相机的真实世界交互视频,如TASTE-Rob,通过重复首帧构建静态场景视频,并结合HaMeR预测的手部网格渲染,丰富了数据集的物理真实性和交互动态多样性。此外,为评估模型在动态视角下的泛化能力,还通过Aria眼镜采集了包含动态视角的真实世界配对数据,形成了全面的基准测试集。
使用方法
该数据集主要用于训练和评估灵巧世界模型这一视频扩散框架。在训练阶段,模型以静态场景视频和以自我为中心的手部网格渲染视频作为条件输入,学习预测由手部动作引发的残差视觉动态,同时保持静态区域不变。数据集中的对齐三元组为模型提供了直接的监督信号,使其能够建模导航与操作的解耦。在评估阶段,数据集被用于定量衡量生成视频的感知相似性与像素级质量,通过LPIPS、DreamSim、PSNR和SSIM等指标进行综合评测。此外,数据集还支持基于模拟的动作评估任务,模型可生成候选动作的视觉后果,并通过与语言指令或目标图像的比对进行排序,从而实现目标驱动的动作选择。
背景与挑战
背景概述
在计算机视觉与具身智能领域,构建能够预测人类动作如何引发环境动态变化的世界模型,是实现智能系统与物理世界交互的关键。Dexterous World Models (DWM) 数据集由首尔国立大学与RLWRLD的研究团队于2025年提出,旨在填补静态三维场景与具身交互之间的鸿沟。该数据集的核心研究问题聚焦于如何基于静态三维场景渲染与以自我为中心的手部运动序列,生成时序连贯且物理合理的交互视频,从而模拟灵巧手部操控引发的场景动态变化。这一工作为基于视频扩散的交互式数字孪生奠定了基础,推动了具身模拟与视觉世界建模的发展。
当前挑战
DWM数据集致力于解决具身交互中视觉动态预测的挑战,其核心问题在于如何准确建模灵巧手部动作对静态场景的因果性影响,并生成高保真、时空一致的交互视频。在构建过程中,研究团队面临多重挑战:其一,缺乏在相同相机轨迹下对齐的静态场景渲染与交互视频配对数据,这迫使研究者采用混合数据构建策略,结合合成数据提供精确对齐与真实世界数据提供多样物理动态;其二,合成数据虽可控但动态多样性有限,而真实世界数据又难以在动态自我中心视角下获取完美对齐的配对,需通过固定相机视频近似构建,这对模型的泛化与对齐监督提出了严峻考验。
常用场景
经典使用场景
在具身智能与计算机视觉领域,Dexterous World Models (DWM) 数据集最经典的使用场景是作为训练和评估场景-动作条件化视频扩散模型的基准。该数据集通过提供精确对齐的静态3D场景渲染、以自我为中心的手部运动序列以及相应的人-物交互视频,为模型学习灵巧手部操作如何诱导静态环境产生动态视觉变化提供了关键监督信号。其核心价值在于构建了一个因果推理框架,使得模型能够基于已知的静态场景和具体的动作输入,预测出符合物理规律的交互动态,从而为构建可交互的数字孪生世界迈出了重要一步。
解决学术问题
DWM 数据集主要解决了视觉世界建模中长期存在的关键学术问题。传统世界模型或视频生成模型往往难以精确建模由细粒度人类动作(如抓取、打开)驱动的场景动态变化,且常将背景合成与动作动力学纠缠在一起。该数据集通过提供场景渲染与手部运动的显式条件输入,促使模型专注于学习动作诱导的残差动力学,同时保持静态场景的一致性。这有效推进了从单纯的新视角合成向具身交互仿真的范式转变,为研究动作与视觉后果之间的因果关系提供了数据基础。
实际应用
该数据集的实际应用场景广泛指向下一代交互式数字孪生与机器人仿真。在虚拟现实与游戏领域,它可用于生成高度逼真、由用户手部动作驱动的环境交互内容,提升沉浸感。在机器人学中,基于DWM训练的模型能够作为视觉仿真器,为机器人操作策略提供无需真实物理引擎的训练数据,或通过模拟不同候选动作的视觉结果来进行基于仿真的动作评估与规划。此外,它也为自动驾驶、智能家居等需要预测人类行为对环境影响的领域提供了潜在的测试平台。
数据集最近研究
最新研究方向
在具身智能与三维场景交互领域,Dexterous World Models (DWM) 数据集正推动着以灵巧手部动作为驱动的动态视觉预测研究。该数据集通过结合静态三维场景渲染与以自我为中心的手部运动序列,为视频扩散模型提供了精准的监督信号,使其能够模拟人类与环境的精细交互,如抓取、开关物体等。前沿工作聚焦于利用混合训练策略——融合合成数据与真实世界固定摄像头视频——以提升模型在未见场景中的泛化能力,同时探索在机器人操作仿真、数字孪生交互等热点应用中的潜力。这一进展不仅弥补了传统静态数字孪生缺乏交互动态的局限,也为构建基于视觉的具身世界模型奠定了关键基础,预示着在自动驾驶、虚拟现实等领域将产生深远影响。
相关研究论文
- 1Dexterous World Models首尔国立大学 · 2025年
以上内容由遇见数据集搜集并总结生成


