Mediomatix语料库
收藏arXiv2025-08-22 更新2025-08-26 收录
下载链接:
https://huggingface.co/datasets/ZurichNLP/mediomatix
下载链接
链接失效反馈官方服务:
资源简介:
Mediomatix语料库是首个罗曼什语方言平行语料库,基于291本内容可比的学校教科书,共提取了207,892个多平行语段,超过2百万个词。语料库的创建采用了自动对齐方法,并通过小规模人工评估验证了对齐质量。该数据集适用于罗曼什语方言之间的机器翻译等NLP应用。
The Mediomatix Corpus is the first parallel corpus targeting Romansh dialects. It is constructed from 291 school textbooks with comparable content, containing a total of 207,892 multi-parallel segments and over 2 million words. The corpus was developed using automatic alignment methods, and its alignment quality was validated through small-scale human evaluation. This dataset is suitable for NLP applications such as machine translation between Romansh dialects.
提供机构:
苏黎世大学、格劳宾登州师范学院
创建时间:
2025-08-22
原始信息汇总
Mediomatix 数据集概述
基本信息
- 许可证:CC BY-NC-SA 4.0
- 语言:罗曼什语(Romansh,语言代码:rm)
- 用途:仅限研究目的
数据集结构
- 配置名称:default
- 数据文件:
- 训练集:train.jsonl
- 验证集:valid.jsonl
- 测试集:test.jsonl
- 无Surmiran方言子集:no_surm.jsonl
内容描述
- 数据形式:多语言平行对齐语料
- 来源:格劳宾登州教材(Meds dinstrucziun dal Grischun)
- 方言覆盖:
- 苏尔塞尔瓦方言(Sursilvan):rm-sursilv
- 苏塞尔瓦方言(Sutsilvan):rm-sutsilv
- 苏尔米兰方言(Surmiran):rm-surmiran
- 上恩加丁方言(Puter):rm-puter
- 下恩加丁方言(Vallader):rm-vallader
书籍编码规则
- 第一位数:表示学年
- 后续数字:表示该学年的书籍卷数
- 两位字母代码:
- "wb":学生练习册
- "tc":教师评注
- 示例:"5.1_tc"表示五年级第一卷教材的教师评注
相关资源
- 完整未对齐原始数据:https://huggingface.co/datasets/ZurichNLP/mediomatix-raw
引用信息
bibtex @misc{hopton-et-al-2025-mediomatix, title={The Mediomatix Corpus: Parallel Data for Romansh Idioms via Comparable Schoolbooks}, author={Zachary Hopton and Jannis Vamvas and Andrin Büchler and Anna Rutkiewicz and Rico Cathomas and Rico Sennrich}, year={2025}, eprint={2508.16371}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2508.16371}, }
版权声明
© 2025 Meds dinstrucziun dal Grischun
搜集汇总
数据集介绍
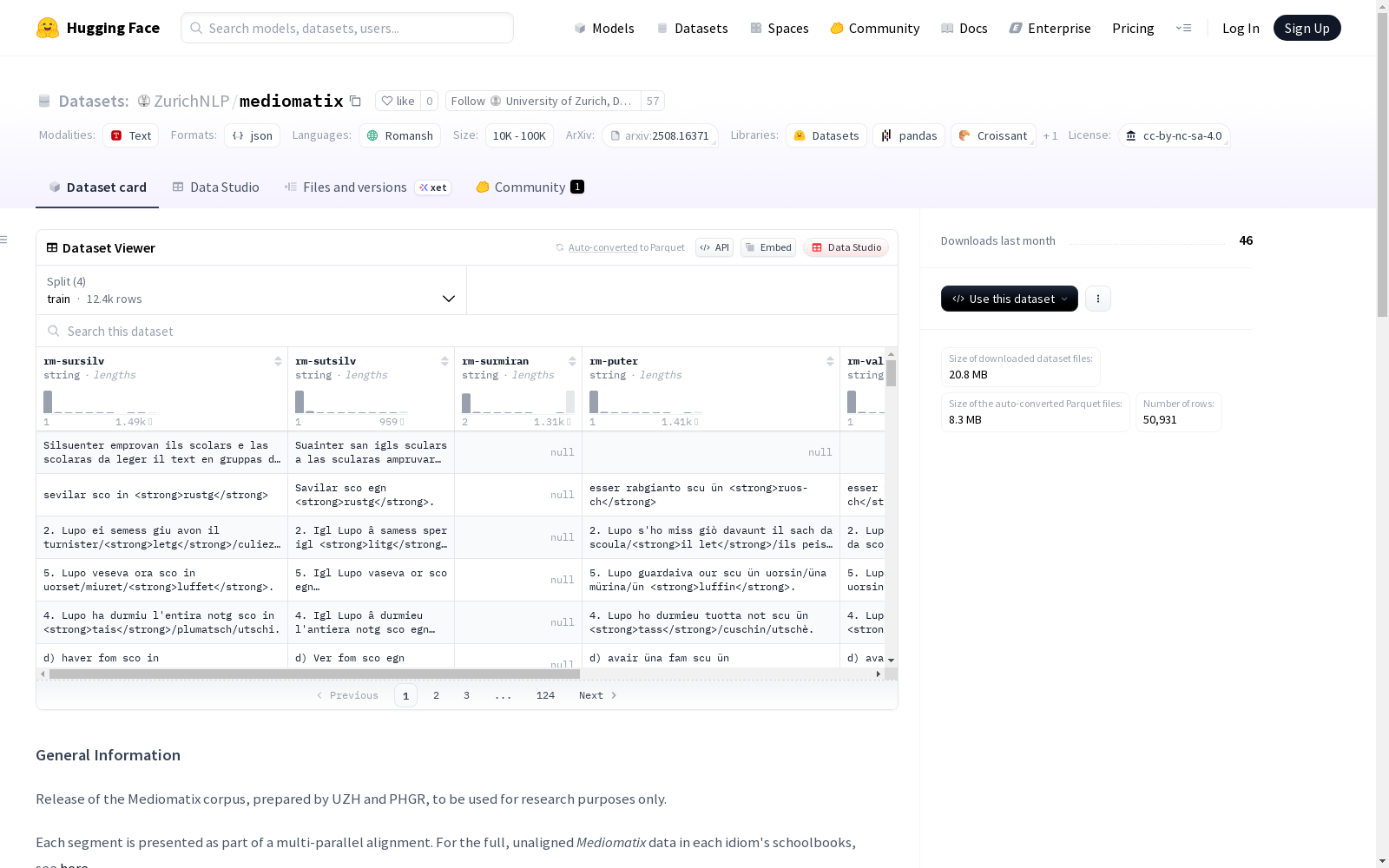
构建方式
在罗曼什语多方言平行语料库构建领域,Mediomatix语料库通过系统性方法实现了突破。该数据集基于291册教学内容高度可比的教学用书,采用VecAlign嵌入对齐算法进行自动段落匹配,并创新性地运用枢轴共识对齐策略确保五种方言间的多向平行性。通过严格限制1-1对齐模式并辅以长度启发式过滤,最终从原始文本中精准提取出20.7万个多平行段落,涵盖超过200万词汇量。
特点
该语料库最显著的特征在于其高质量的多方言平行结构,涵盖苏尔塞瓦语、苏齐尔瓦语、苏尔米兰语、普特语和瓦拉德尔语五种标准化罗曼什方言。数据源自教育系统的正式语言材料,具有严格的语法规范和词汇一致性。经人工评估验证,472个抽样段落中仅存在1处对齐错误,精确度达99.8%,且89%的多平行行完全无噪声。语料规模分布呈现方言均衡性,其中苏尔塞瓦语和苏齐尔瓦语对齐段落均超过4.9万条,为低资源语言处理提供了罕见的高质量资源。
使用方法
该数据集主要应用于罗曼什方言间的机器翻译任务,研究者可采用多语言微调策略在20个翻译方向上训练模型。实践表明,基于5000样本对GPT-4o-mini进行微调后,其BLEU评分平均提升7.5分。数据集按年级层级划分训练/验证/测试集,有效避免内容重叠问题。使用时应遵循CC-BY-NC-SA许可协议,重点关注方言间的词汇差异和语法结构变化,如苏尔塞瓦语的分析性将来时与其他方言综合性将来时的对比分析。
背景与挑战
背景概述
罗曼什语作为瑞士四种国家语言之一,其五大方言变体(Sursilvan、Sutsilvan、Surmiran、Puter、Vallader)在格拉鲁斯州各自社区的教育体系中具有标准化地位。2025年,苏黎世大学与格拉鲁斯师范学院联合发布了Mediomatix语料库,这是首个针对五大方言的多平行语料库,基于291册内容可比的教学书籍构建而成。该语料库包含20.7万条对齐段落,总词元数超过216万,填补了罗曼什方言间机器翻译资源空白,为低资源语言处理研究提供了重要基础。
当前挑战
该语料库需解决罗曼什方言间机器翻译的核心难题:方言在正字法、词汇和形态句法层面的显著差异导致跨方言语义对齐困难。构建过程中面临双重挑战:一是从非严格平行的教材中提取高质量对齐段落,需通过嵌入模型与枢轴共识算法提升对齐精度;二是Surmiran方言教材发布时间较晚,存在翻译文本特有的“翻译腔”现象,可能影响机器翻译模型对自然语言的泛化能力。
常用场景
经典使用场景
在罗曼什语多方言机器翻译研究中,Mediomatix语料库作为首个跨方言平行语料资源,通过嵌入对齐技术从可比教材中提取20.7万条平行段落,为低资源语言处理提供了范式。其经典应用体现在支撑神经网络模型进行五种方言间的互译训练,例如通过微调GPT-4o-mini模型在20个翻译方向上平均提升7.5个BLEU值,显著改善了方言间词汇、句法和正字法差异的跨语言转换能力。
解决学术问题
该语料库解决了罗曼什语方言标准化文本匮乏的核心学术问题,填补了多方言平行数据的空白。通过 pivot consensus alignment 策略实现97.2%的对齐精度,为计算语言学提供了研究方言变异性的定量基础,支持了语言资源稀缺情境下的嵌入迁移研究,对濒危语言保护与数字化存档具有里程碑意义,推动了少数民族语言在NLP领域的可计算化进程。
衍生相关工作
基于该语料库衍生的经典工作包括VecAlign嵌入对齐算法的优化实践、低资源机器翻译的少样本提示工程研究,以及多方言语言模型微调范式的探索。后续研究进一步扩展至方言语法现象的计算分析、跨方言语义检索系统构建,并为FLORES等翻译语料库的构建方法论提供了可比文本对齐的新范式参考。
以上内容由遇见数据集搜集并总结生成


