full-modality-data
收藏魔搭社区2025-12-03 更新2025-08-09 收录
下载链接:
https://modelscope.cn/datasets/lmms-lab/full-modality-data
下载链接
链接失效反馈官方服务:
资源简介:
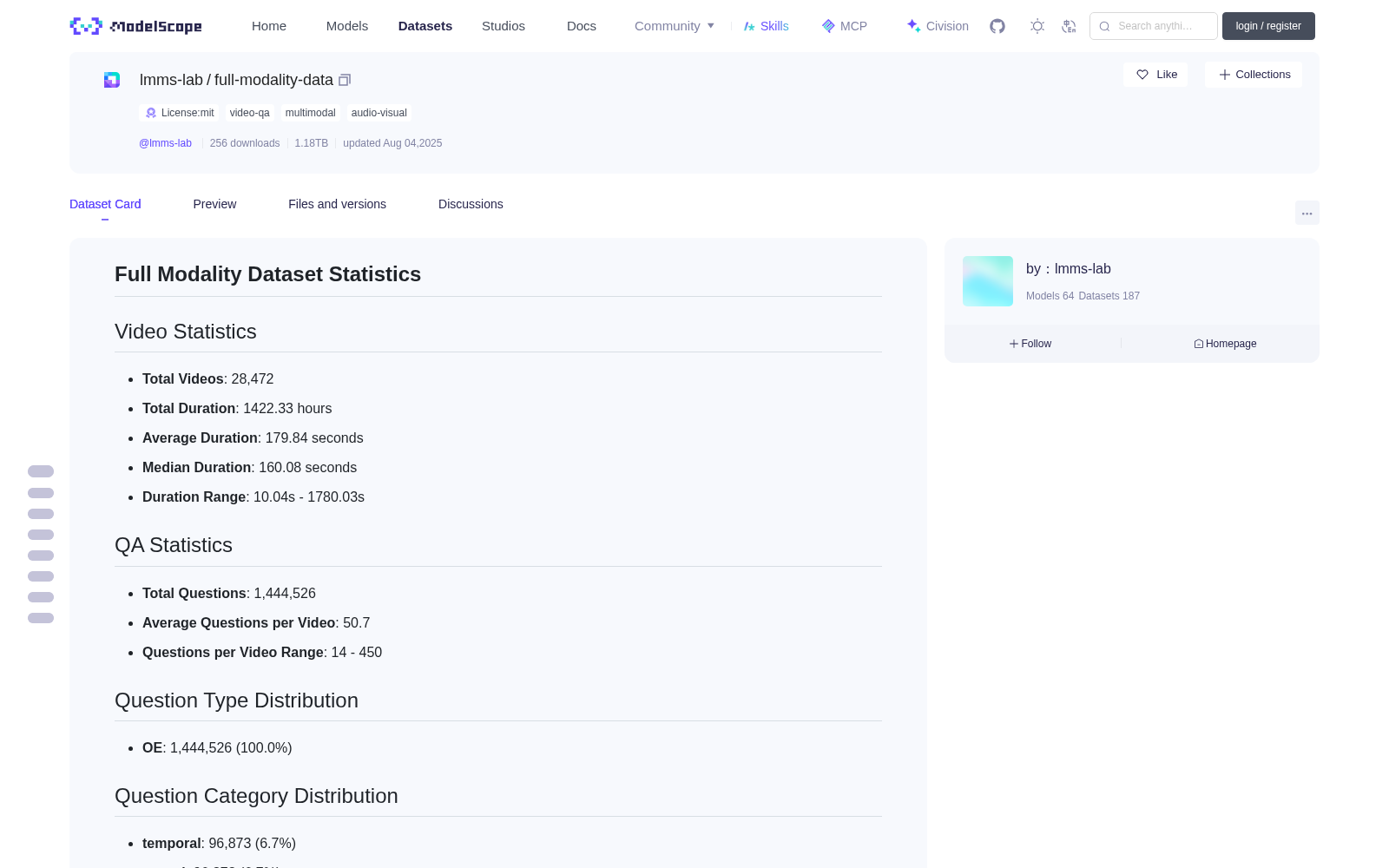
# Full Modality Dataset Statistics
## Video Statistics
- **Total Videos**: 28,472
- **Total Duration**: 1422.33 hours
- **Average Duration**: 179.84 seconds
- **Median Duration**: 160.08 seconds
- **Duration Range**: 10.04s - 1780.03s
## QA Statistics
- **Total Questions**: 1,444,526
- **Average Questions per Video**: 50.7
- **Questions per Video Range**: 14 - 450
## Question Type Distribution
- **OE**: 1,444,526 (100.0%)
## Question Category Distribution
- **temporal**: 96,873 (6.7%)
- **causal**: 96,873 (6.7%)
- **description_scene**: 96,873 (6.7%)
- **description_human**: 96,873 (6.7%)
- **description_object**: 96,873 (6.7%)
- **binary**: 96,873 (6.7%)
- **fine_grained_action_understanding**: 96,873 (6.7%)
- **plot_understanding**: 96,873 (6.7%)
- **non_existent_actions**: 96,873 (6.7%)
- **time_order_understanding**: 96,873 (6.7%)
- **attribute_change**: 96,873 (6.7%)
- **audio_visual_dialogue_consistency**: 96,873 (6.7%)
- **audio_visual_subtext**: 96,873 (6.7%)
- **audio_visual_mood**: 96,873 (6.7%)
- **spatial_reasoning**: 88,304 (6.1%)
## Dataset Description
This dataset contains multimodal video question-answering pairs that require both visual and audio information to answer correctly. The questions span multiple categories including temporal reasoning, causal analysis, scene description, and more. All questions are open-ended format.
## Dataset Structure
The dataset contains the following columns:
- `video_id`: Unique identifier for the video
- `video_filename`: Original filename of the video
- `video_duration`: Duration of the video in seconds
- `video_size_mb`: Size of the video file in MB
- `segment`: Time segment within the video (format: start_time-end_time)
- `category`: Question category (e.g., temporal, causal, description_scene, etc.)
- `question`: The question text (open-ended format)
- `answer`: The correct answer
## Usage
```python
from datasets import load_dataset
dataset = load_dataset("ngqtrung/full-modality-data")
# Filter by category
temporal_questions = dataset.filter(lambda x: x['category'] == 'temporal')
causal_questions = dataset.filter(lambda x: x['category'] == 'causal')
# Get unique categories
categories = set(dataset['category'])
print(f"Available categories: {categories}")
```
# 全模态数据集统计(Full Modality Dataset Statistics)
## 视频统计
- **总视频数**:28,472
- **总时长**:1422.33 小时
- **平均时长**:179.84 秒
- **时长中位数**:160.08 秒
- **时长区间**:10.04 秒 至 1780.03 秒
## 问答(Question Answering, QA)统计
- **总问题数**:1,444,526
- **单视频平均问题数**:50.7
- **单视频问题数区间**:14 至 450
## 问题类型分布
- **开放式问题(Open-ended, OE)**:1,444,526(占比100.0%)
## 问题类别分布
- **时间推理类(temporal)**:96,873(占比6.7%)
- **因果推理类(causal)**:96,873(占比6.7%)
- **场景描述类(description_scene)**:96,873(占比6.7%)
- **人体描述类(description_human)**:96,873(占比6.7%)
- **物体描述类(description_object)**:96,873(占比6.7%)
- **二分类问题类(binary)**:96,873(占比6.7%)
- **细粒度动作理解类(fine_grained_action_understanding)**:96,873(占比6.7%)
- **情节理解类(plot_understanding)**:96,873(占比6.7%)
- **非存在动作类(non_existent_actions)**:96,873(占比6.7%)
- **时间顺序理解类(time_order_understanding)**:96,873(占比6.7%)
- **属性变化类(attribute_change)**:96,873(占比6.7%)
- **音画对话一致性类(audio_visual_dialogue_consistency)**:96,873(占比6.7%)
- **音画潜台词类(audio_visual_subtext)**:96,873(占比6.7%)
- **音画情绪类(audio_visual_mood)**:96,873(占比6.7%)
- **空间推理类(spatial_reasoning)**:88,304(占比6.1%)
## 数据集描述
本数据集包含多模态视频问答对,需同时结合视觉与音频信息方可正确作答。问题涵盖时间推理、因果分析、场景描述等多个类别,所有问题均采用开放式格式。
## 数据集结构
数据集包含以下字段:
- `video_id`:视频的唯一标识符
- `video_filename`:视频的原始文件名
- `video_duration`:视频时长,单位为秒
- `video_size_mb`:视频文件大小,单位为MB
- `segment`:视频内的时间片段(格式:开始时间-结束时间)
- `category`:问题类别(例如:temporal、causal、description_scene等)
- `question`:问题文本(开放式格式)
- `answer`:正确答案
## 使用方法
python
from datasets import load_dataset
dataset = load_dataset("ngqtrung/full-modality-data")
# 按类别筛选
temporal_questions = dataset.filter(lambda x: x['category'] == 'temporal')
causal_questions = dataset.filter(lambda x: x['category'] == 'causal')
# 获取所有唯一类别
categories = set(dataset['category'])
print(f"可用类别:{categories}")
提供机构:
maas创建时间:
2025-08-04
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个多模态视频问答数据集,包含28,472个视频(总时长1422.33小时)和1,444,526个开放性问题。问题涵盖时间推理、因果分析、场景描述等15个类别,所有问题均需结合视觉和音频信息来回答。
以上内容由遇见数据集搜集并总结生成


