有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
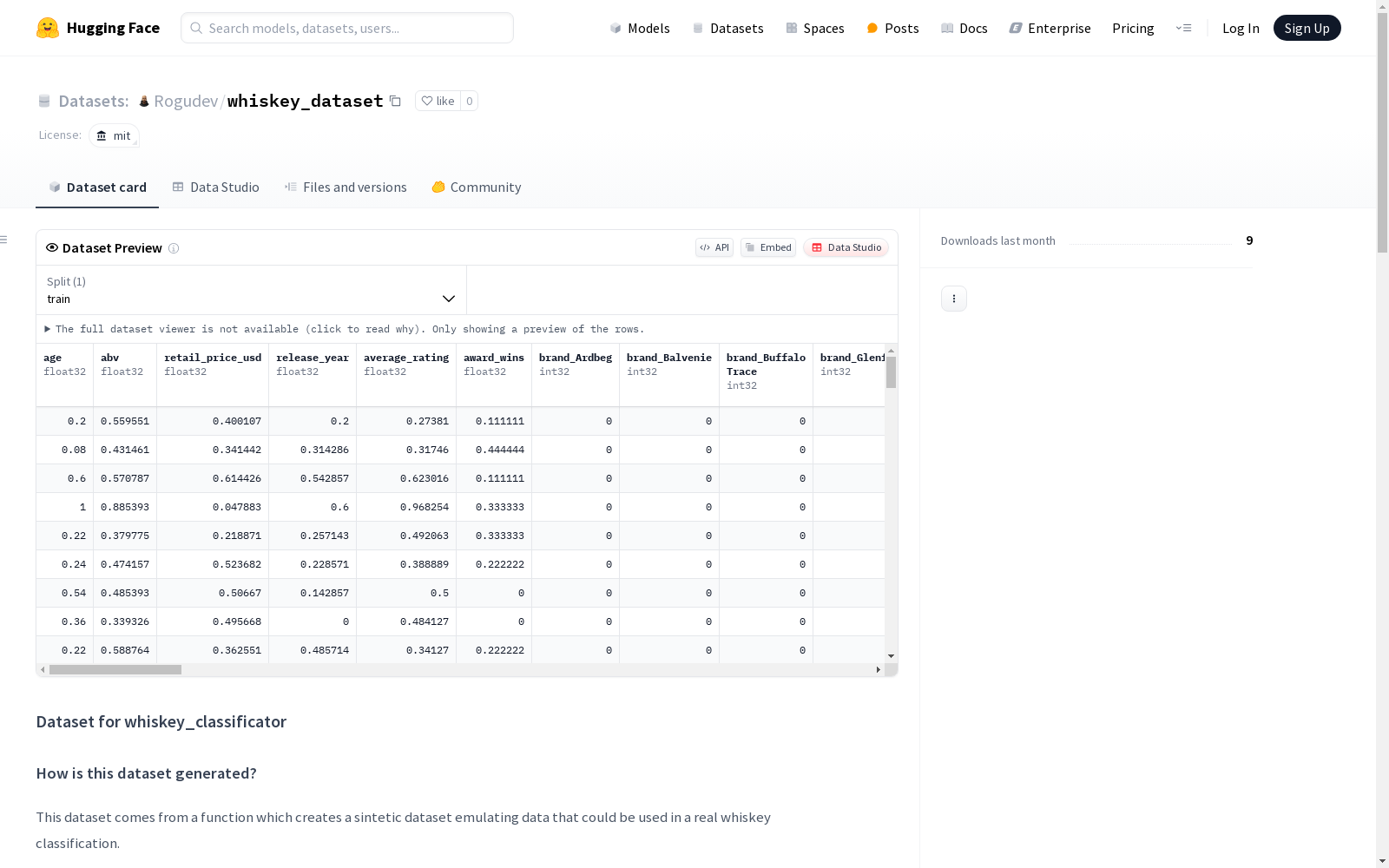
generate_whiskey()生成| 字段名 | 描述 |
|---|---|
| whiskey_name | 威士忌名称(品牌+年龄+木桶类型) |
| brand | 品牌名称 |
| type | 威士忌类型 |
| age | 年份(0表示无年份声明) |
| abv | 酒精度数(40-60%) |
| region | 产区 |
| cask_type | 木桶类型 |
| bottling_type | 装瓶类型 |
| retail_price_usd | 零售价格(美元) |
| is_limited_edition | 是否限量版 |
| release_year | 发布年份 |
| average_rating | 平均评分 |
| award_wins | 获奖数量 |
| rating_category | 评分等级 |
| category | 价格类别 |
中国农村金融统计数据
该数据集包含了中国农村金融的统计信息,涵盖了农村金融机构的数量、贷款余额、存款余额、金融服务覆盖率等关键指标。数据按年度和地区分类,提供了详细的农村金融发展状况。
www.pbc.gov.cn 收录
GME Data
关于2021年GameStop股票活动的数据,包括每日合并的GME短期成交量数据、每日失败交付数据、可借股数、期权链数据以及不同时间框架的开盘/最高/最低/收盘/成交量条形图。
github 收录
LinkedIn Salary Insights Dataset
LinkedIn Salary Insights Dataset 提供了全球范围内的薪资数据,包括不同职位、行业、地理位置和经验水平的薪资信息。该数据集旨在帮助用户了解薪资趋势和市场行情,支持职业规划和薪资谈判。
www.linkedin.com 收录
China Groundgroundwater Monitoring Network
该数据集包含中国地下水监测网络的数据,涵盖了全国范围内的地下水位、水质和相关环境参数的监测信息。数据包括但不限于监测站点位置、监测时间、水位深度、水质指标(如pH值、溶解氧、总硬度等)以及环境因素(如气温、降水量等)。
www.ngac.org.cn 收录
UAVDT
UAVDT数据集由中国科学院大学等机构创建,包含约80,000帧从10小时无人机拍摄视频中精选的图像,覆盖多种复杂城市环境。数据集主要关注车辆目标,每帧均标注了边界框及多达14种属性,如天气条件、飞行高度、相机视角等。该数据集旨在推动无人机视觉技术在不受限制场景下的研究,解决高密度、小目标、相机运动等挑战,适用于物体检测、单目标跟踪和多目标跟踪等基础视觉任务。
arXiv 收录