suju
收藏Hugging Face2026-02-04 更新2026-02-05 收录
下载链接:
https://huggingface.co/datasets/zcxi/suju
下载链接
链接失效反馈官方服务:
资源简介:
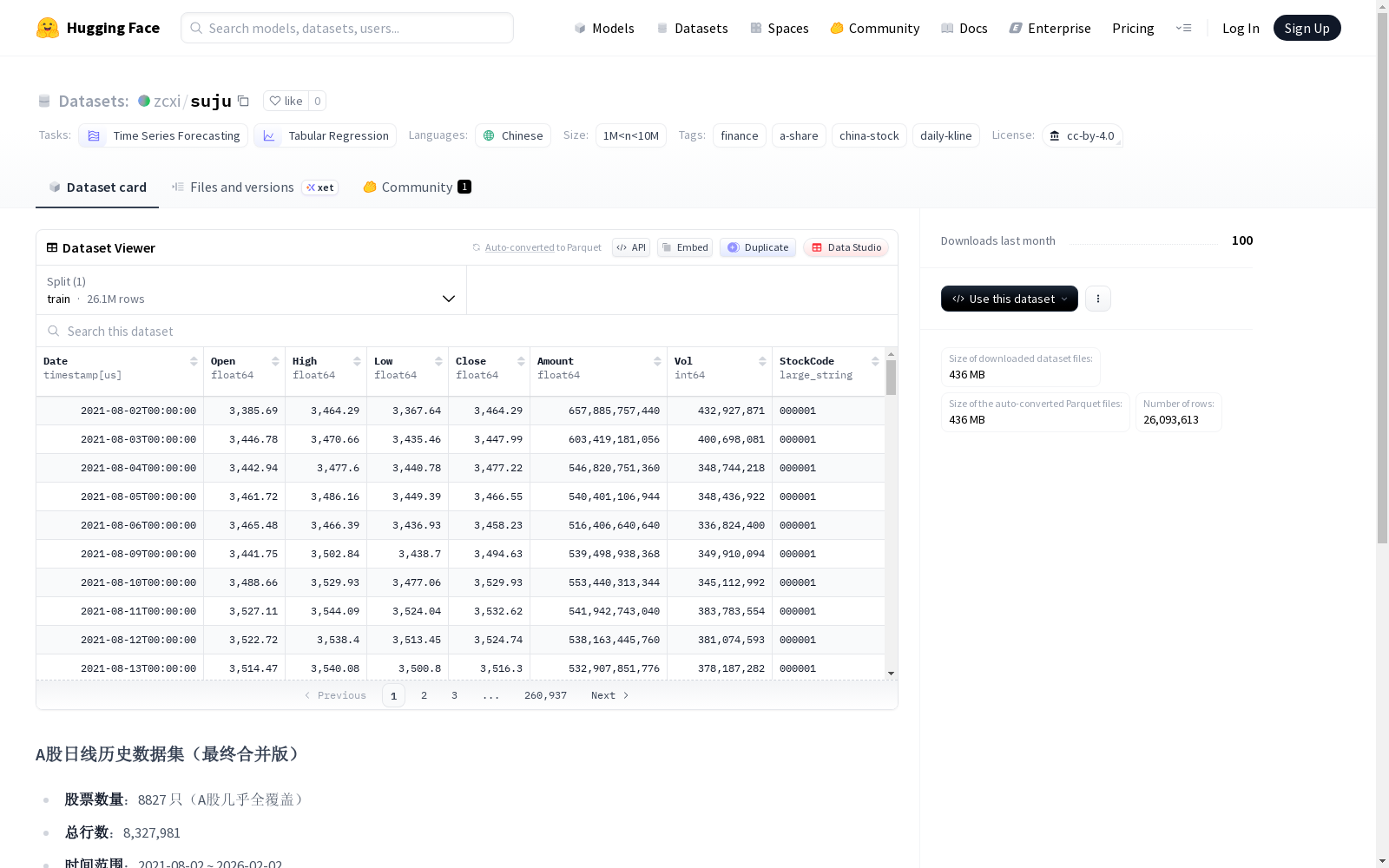
A股日线历史数据集(最终合并版)是一个涵盖中国A股市场8827只股票的高覆盖率金融时间序列数据集。数据集包含8,327,981行数据,时间范围从2021年8月2日至2026年2月2日。每行数据包含以下字段:日期(datetime)、开盘价、最高价、最低价、收盘价、成交额、成交量以及6位股票代码。数据来源于原始CSV文件提取的股票代码并经过清洗合并处理,最终以179 MB的parquet文件(merged_stock.parquet)形式提供。该数据集适用于时间序列预测和表格回归等任务,特别适合用于中国A股市场的金融分析和研究。
Daily Historical A-share Dataset (Final Consolidated Version) is a high-coverage financial time series dataset covering 8,827 stocks listed on the Chinese A-share market. The dataset contains 8,327,981 rows of data, with a time span from August 2, 2021 to February 2, 2026. Each row includes the following fields: date (datetime format), opening price, highest price, lowest price, closing price, transaction amount, trading volume, and 6-digit stock code. The data is extracted from raw CSV files, cleaned and consolidated, and finally provided as a 179 MB Parquet file named merged_stock.parquet. This dataset is suitable for tasks such as time series forecasting and tabular regression, and is particularly well-suited for financial analysis and research on the Chinese A-share market.
创建时间:
2026-02-03
原始信息汇总
A股日线历史数据集(最终合并版)概述
数据集基本信息
- 语言:中文
- 许可协议:CC BY 4.0
- 数据规模:1M < n < 10M
- 任务类别:时间序列预测、表格回归
- 标签:金融、A股、中国股票、日K线
数据集内容详情
- 股票数量:8827只(A股几乎全覆盖)
- 总行数:8,327,981
- 时间范围:2021年8月2日至2026年2月2日
- 数据列:Date (datetime), Open, High, Low, Close, Amount, Vol, StockCode (6位代码)
- 数据来源:原始CSV文件名提取StockCode,经清洗后合并
- 文件信息:merged_stock.parquet (179 MB)
数据加载与使用
加载示例代码如下: python from datasets import load_dataset ds = load_dataset("zcxi/suju") df = ds[train].to_pandas()
示例:查看 000001 股票
df_000001 = df[df[StockCode] == 000001] print(df_000001.head())
搜集汇总
数据集介绍
构建方式
在金融时序分析领域,高质量的历史数据是模型训练与市场研究的基石。本数据集通过系统整合A股市场的日线交易记录构建而成,原始数据来源于多个CSV文件,从中提取出股票代码并进行深度清洗,最终将八千余只股票的信息合并为一个统一的Parquet格式文件,确保了数据的完整性与一致性。
特点
该数据集以其广泛的覆盖面和精细的结构而著称,囊括了超过八千八百只A股股票,时间跨度从2021年延伸至2026年,总计包含八百多万行日线记录。每条记录均包含日期、开盘价、最高价、最低价、收盘价、成交额及成交量等关键字段,为量化金融研究提供了全面而详实的基础。
使用方法
利用Hugging Face的datasets库,研究者可以便捷地加载此数据集进行探索与分析。通过简单的Python代码调用load_dataset函数,即可将数据转换为Pandas DataFrame格式,进而依据股票代码筛选特定标的,开展时间序列预测、回归建模等深入的金融数据分析工作。
背景与挑战
背景概述
在金融时间序列分析领域,高质量、大规模的历史股价数据是驱动量化投资策略研发与市场行为建模的基石。A股日线历史数据集(suju)由社区贡献者于近期构建并发布,其核心目标在于整合覆盖中国A股市场近全貌的标准化日频交易数据,为学术界与工业界提供一套统一、易访问的基准资源。该数据集囊括了2021年至2026年间超过8800只股票的日线行情,包括开盘价、最高价、收盘价等关键字段,旨在支持时间序列预测、回归分析及更广泛的金融计量研究,对提升中国证券市场数据透明度与研究方法可复现性具有积极意义。
当前挑战
该数据集致力于应对金融时间序列预测中的核心挑战,即在高噪声、非平稳的市场环境中捕捉股价变动的复杂模式,并解决因市场机制、宏观经济事件及投资者情绪交织所导致预测难度大的问题。在构建过程中,挑战主要源于多源异构原始数据的清洗与标准化,需统一不同数据源的格式与编码,并确保股票代码与时间序列的完整性与一致性;同时,大规模数据(近千万行)的高效合并与存储,以及未来数据在时间维度上的持续更新与维护,均构成了实际工程实施中的关键难点。
常用场景
经典使用场景
在金融时间序列分析领域,该数据集作为A股市场日线历史数据的全面集合,为量化投资策略的研发与验证提供了核心基础。研究者常利用其高覆盖率的股票代码与完整的开盘价、收盘价等关键指标,构建并回测各类预测模型,以探索市场波动规律与资产价格走势。
解决学术问题
该数据集有效应对了金融实证研究中数据获取不完整与清洗成本高昂的挑战,为资产定价、风险管理和市场效率检验等经典学术议题提供了标准化、大规模的真实数据支撑。其跨时间维度的连续性记录,有助于深化对A股市场动态特征与结构性变化的量化理解。
衍生相关工作
围绕该数据集,已衍生出诸多聚焦于时序预测与回归分析的经典研究,例如结合深度学习架构的股价趋势预测模型、基于因子挖掘的多空策略构建,以及融合自然语言处理技术的市场舆情与行情关联性探索。这些工作持续推动着计算金融学方法的前沿进展。
以上内容由遇见数据集搜集并总结生成


