MNLP_MCQA_dataset
收藏Hugging Face2025-05-25 更新2025-05-26 收录
下载链接:
https://huggingface.co/datasets/andresnowak/MNLP_MCQA_dataset
下载链接
链接失效反馈官方服务:
资源简介:
这是一个多项选择题问答数据集,包含训练集、验证集和测试集。它整合了多个子数据集,如mmlu、ai2_arc、ScienceQA等,涵盖了科学、数学、医学等多个领域。数据集中的问题都有四个选项和一个正确答案。
创建时间:
2025-05-25
原始信息汇总
数据集概述
基本信息
- 数据集名称: MNLP_MCQA_dataset
- 语言: 英语 (en)
- 任务类别: 问答 (question-answering), 文本生成 (text-generation)
- 规模: 100K<n<1M
数据集组成
数据集包含多个子数据集,具体如下:
ScienceQA
- 特征:
- dataset, id, question, choices (sequence), answer, context (null)
- 数据分割:
- 训练集: 3018 个样本
- 验证集: 1070 个样本
- 测试集: 1070 个样本
- 下载大小: 565306 字节
- 数据集大小: 1081996 字节
ai2_arc_challenge
- 特征:
- dataset, id, question, choices (sequence), answer, context (null)
- 数据分割:
- 训练集: 1119 个样本
- 验证集: 299 个样本
- 测试集: 1172 个样本
- 下载大小: 1097425 字节
- 数据集大小: 855616 字节
ai2_arc_easy
- 特征:
- dataset, id, question, choices (sequence), answer, context (null)
- 数据分割:
- 训练集: 2251 个样本
- 验证集: 570 个样本
- 测试集: 2376 个样本
- 下载大小: 1517868 字节
- 数据集大小: 1475504 字节
all
- 特征:
- dataset, id, question, choices (sequence), answer, context
- 数据分割:
- 训练集: 186794 个样本
- 验证集: 11065 个样本
- 测试集: 9182 个样本
- 下载大小: 149134819 字节
- 数据集大小: 128184527 字节
math_qa
- 特征:
- dataset, id, question, choices (sequence), answer, context
- 数据分割:
- 训练集: 29837 个样本
- 验证集: 4475 个样本
- 下载大小: 17009546 字节
- 数据集大小: 16219815 字节
medmcqa
- 特征:
- dataset, id, question, choices (sequence), answer, context
- 数据分割:
- 训练集: 120765 个样本
- 验证集: 2816 个样本
- 测试集: 4134 个样本
- 下载大小: 99993546 字节
- 数据集大小: 82803636 字节
mmlu
- 特征:
- dataset, id, question, choices (sequence), answer, context (null)
- 数据分割:
- 验证集: 335 个样本
- 下载大小: 60611 字节
- 数据集大小: 103367 字节
mmlu-auxiliary-train-auto-labelled
- 特征:
- dataset, id, question, choices (sequence), answer, context (null)
- 数据分割:
- 训练集: 13168 个样本
- 下载大小: 5234820 字节
- 数据集大小: 16111661 字节
openbookqa
- 特征:
- dataset, id, question, choices (sequence), answer, context
- 数据分割:
- 训练集: 4957 个样本
- 验证集: 500 个样本
- 测试集: 500 个样本
- 下载大小: 1594283 字节
- 数据集大小: 1466578 字节
sciq
- 特征:
- dataset, id, question, choices (sequence), answer, context
- 数据分割:
- 训练集: 11679 个样本
- 验证集: 1000 个样本
- 测试集: 1000 个样本
- 下载大小: 9594991 字节
- 数据集大小: 8182381 字节
数据来源
数据集由以下多个公开数据集混合而成:
- mmlu auxiliary train
- mmlu
- ai2_arc
- ScienceQA
- math_qa
- openbook_qa
- sciq
- medmcqa
搜集汇总
数据集介绍
构建方式
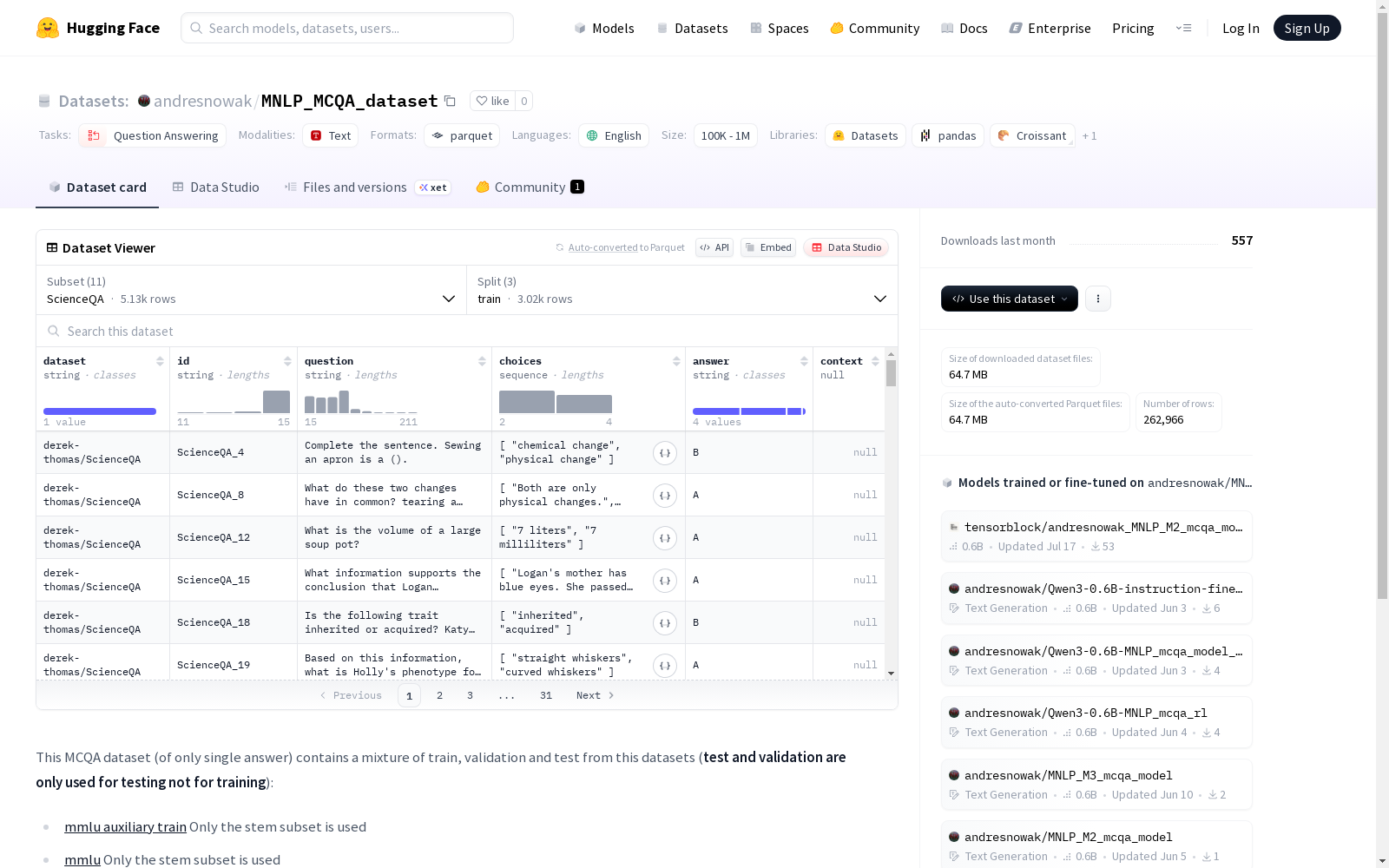
在构建多选问答数据集的过程中,MNLP_MCQA_dataset通过整合多个权威科学问答数据集而形成。该数据集汇集了来自mmlu辅助训练集、ai2_arc、ScienceQA、math_qa、openbook_qa、sciq以及medmcqa等九个不同来源的数据,并经过精心筛选以确保仅包含单一正确答案的样本。构建过程中采用了随机子集抽取策略,例如medmcqa部分使用随机种子42选取了32,000个样本,同时针对mmlu数据集仅保留其STEM相关子集,从而保证了数据内容的专业性和多样性。
特点
MNLP_MCQA_dataset作为多领域科学问答的集合,其显著特点在于覆盖了从基础科学到专业医学的广泛知识范畴。数据集包含超过十万条样本,每条数据均具备标准化的结构特征,包括问题描述、多项选择列表和明确答案标识。特别值得注意的是,该数据集严格遵循单一答案标注原则,且测试集与验证集仅用于评估目的,有效避免了训练过程中的数据泄露风险。不同子集间保持了原始数据的领域特异性,如STEM学科的重点突出和医学问题的专业深度,为模型提供了跨学科的知识理解挑战。
使用方法
对于研究者而言,该数据集支持通过HuggingFace平台直接加载各子集配置进行使用。典型应用流程包括使用train分割进行模型训练,利用validation分割进行超参数调优,并通过test分割评估最终性能。数据加载时可选择特定领域子集(如ScienceQA或medmcqa)进行定向研究,也可使用all配置进行全量跨领域测试。每条数据均以结构化字段呈现,用户可直接提取question、choices和answer字段构建多选问答任务,而context字段的存在则为需要背景知识的模型提供了扩展接口。
背景与挑战
背景概述
MNLP_MCQA_dataset作为多领域多项选择问答数据集的集成平台,汇集了来自科学、数学、医学及常识推理等广泛学科的知识资源。该数据集由多个知名研究机构如Allen Institute for AI和开源社区共同构建,旨在通过整合MMLU、AI2 ARC、ScienceQA等权威子集,为自然语言处理模型提供跨学科的评估基准。其核心研究问题聚焦于提升模型在复杂语境下的推理能力与知识泛化水平,对推动人工智能在教育和专业领域的应用具有深远影响。
当前挑战
该数据集面临的领域挑战在于解决多学科知识融合下的模型泛化难题,尤其在处理科学和数学等需要符号推理的复杂问题时,模型易受领域术语和逻辑结构差异的干扰。构建过程中的挑战涉及异构数据源的标准化整合,例如不同子集的答案格式统一与质量校验,以及医学数据集MedMCQA的规模裁剪带来的代表性平衡问题。此外,确保自动标注的辅助训练数据与人工标注集之间的语义一致性,也是保障评估可靠性的关键。
常用场景
经典使用场景
在自然语言处理领域,多项选择题问答(MCQA)是评估模型推理能力的重要范式。MNLP_MCQA_dataset通过整合科学问答、数学推理和医学知识等多样化子集,为模型提供了跨学科的标准化测试平台。该数据集常被用于训练和验证语言模型在复杂场景下的选择判断能力,特别是在需要逻辑推理和领域知识融合的任务中,成为衡量模型综合性能的基准工具。
解决学术问题
该数据集有效解决了人工智能领域中对模型泛化能力和知识迁移性的评估难题。通过汇集STEM学科、医学和常识推理等专业领域的问答对,它为研究社区提供了检验模型跨领域推理能力的统一框架。这种多源数据整合方式显著降低了单一数据集偏差带来的评估局限,为探究模型在真实世界复杂问题中的表现奠定了实证基础。
衍生相关工作
该数据集的集成特性催生了多项跨领域知识推理的研究突破。基于其构建的评估框架已被广泛应用于大规模语言模型的能力评测,如GPT系列和BERT变体在STEM任务上的系统性验证。相关研究进一步衍生出知识增强的预训练方法,以及针对专业领域问答的迁移学习技术,推动了面向特定领域的模型微调范式的演进。
以上内容由遇见数据集搜集并总结生成


