MMAD
收藏Hugging Face2024-10-30 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/jiang-cc/MMAD
下载链接
链接失效反馈官方服务:
资源简介:
MMAD数据集是一个全面的多模态大语言模型在工业异常检测领域的基准测试数据集,包含问题、图像和描述文本。所有问题都以多选题形式呈现,并经过人工验证。图像来自多个来源,保留了地面真值的掩码格式,以方便未来对多模态大语言模型的分割性能进行评估。描述文本大部分质量良好,但未经过人工验证,使用时需谨慎。MMAD旨在评估当前多模态大语言模型在工业质量检测中的表现,并识别在工业异常检测中的关键挑战。
The MMAD dataset is a comprehensive benchmark dataset for multimodal large language models in the field of industrial anomaly detection. It contains questions, images and descriptive texts. All questions are presented in multiple-choice format and have been manually verified. The images are sourced from multiple origins, with their ground-truth mask formats retained to facilitate future evaluation of the segmentation performance of multimodal large language models. Most of the descriptive texts are of good quality, but they have not been manually verified, so caution should be exercised when using them. The MMAD dataset aims to evaluate the performance of current multimodal large language models in industrial quality inspection and identify key challenges in industrial anomaly detection.
创建时间:
2024-10-17
原始信息汇总
MMAD: The First-Ever Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection
数据集概述
- 任务类别: 问答
- 标签:
- 异常检测
- 多模态大语言模型 (MLLM)
- 规模: 10K<n<100K
- 许可证: MIT
数据集内容
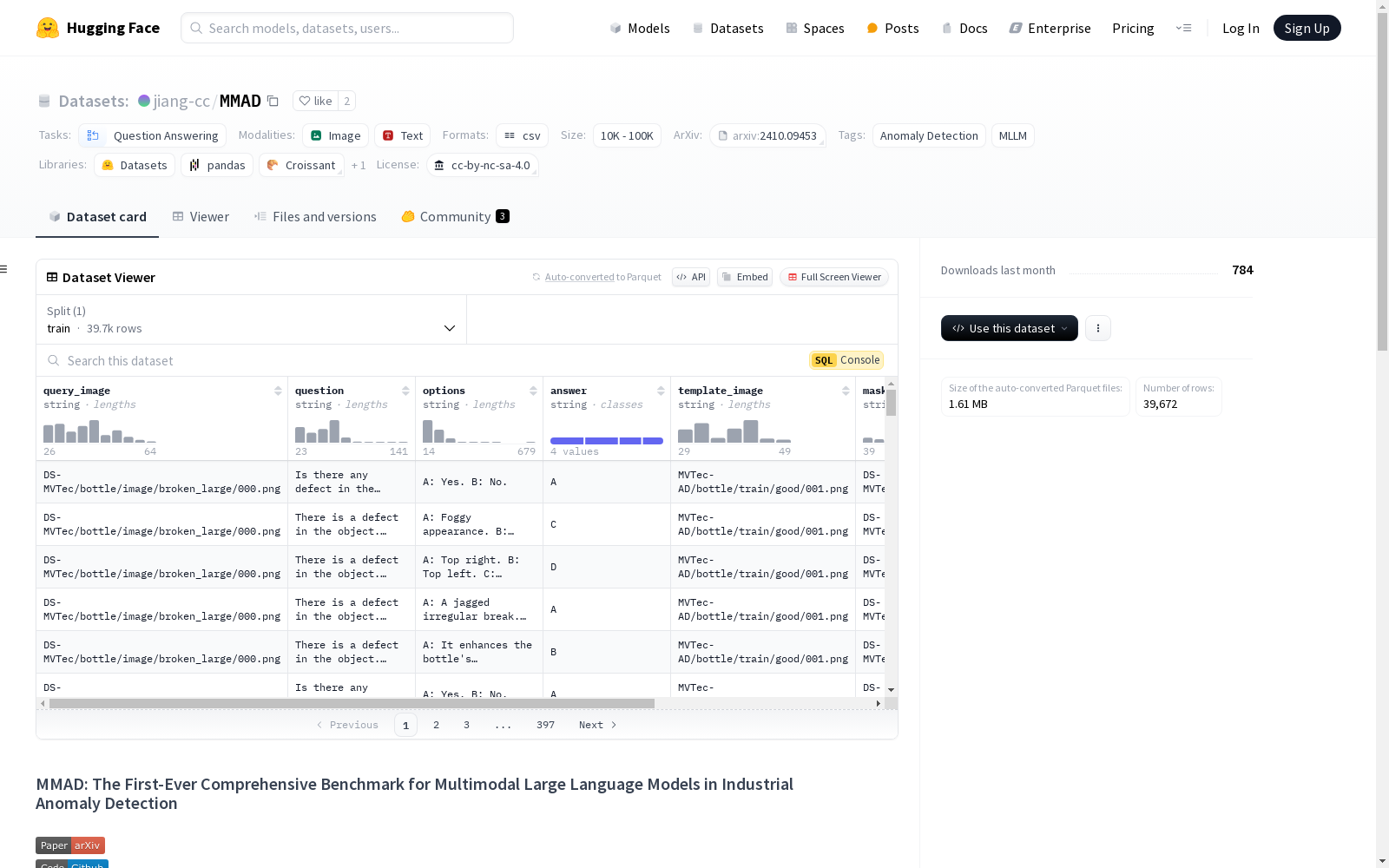
- 内容: 包含问题、图像和描述文本。
- 问题: 所有问题均为多选题格式,并经过人工验证,包括选项和答案。
- 图像: 图像来源包括以下数据集:
- DS-MVTec
- MVTec-AD
- MVTec-LOCO
- VisA
- GoodsAD 图像保留了地面真值的掩码格式,以方便未来对多模态大语言模型分割性能的评估。
- 描述文本: 大多数图像都有对应的文本文件,位于同一文件夹中,包含相关描述。由于这不是该基准的主要关注点,因此未进行人工验证。尽管大多数描述质量良好,但请谨慎使用。
数据集目标
- 评估当前多模态大语言模型在工业质量检测中的表现。
- 确定在工业异常检测中表现最佳的多模态大语言模型。
- 识别多模态大语言模型在工业异常检测中的关键挑战。
评估方法
- 请参考GitHub仓库中的evaluation/examples文件夹。
引用
bibtex @inproceedings{Jiang2024MMADTF, title={MMAD: The First-Ever Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection}, author={Xi Jiang and Jian Li and Hanqiu Deng and Yong Liu and Bin-Bin Gao and Yifeng Zhou and Jialin Li and Chengjie Wang and Feng Zheng}, year={2024}, journal={arXiv preprint arXiv:2410.09453}, }
搜集汇总
数据集介绍
构建方式
MMAD数据集的构建基于工业检测领域的需求,旨在评估多模态大语言模型(MLLMs)在工业异常检测中的表现。数据集包含39,672个问题,覆盖8,366张工业图像,这些问题以多选题形式呈现,并经过人工验证。图像数据来源于多个公开数据集,如DS-MVTec、MVTec-AD、MVTec-LOCO、VisA和GoodsAD,保留了地面实况的掩码格式,以便未来评估MLLMs的分割性能。此外,大多数图像附有对应的文本描述,尽管这些描述未经过人工验证,但质量普遍较高。
特点
MMAD数据集的特点在于其全面性和多样性。作为首个针对工业异常检测的多模态大语言模型基准,它定义了七个关键子任务,涵盖了工业检测中的多个方面。数据集中的问题以多选题形式呈现,确保了评估的客观性和准确性。图像数据来源广泛,涵盖了不同类型的工业场景,增强了数据集的代表性和实用性。此外,数据集保留了地面实况的掩码格式,为未来研究提供了丰富的评估资源。
使用方法
MMAD数据集的使用方法主要围绕评估多模态大语言模型在工业异常检测中的表现展开。用户可以通过GitHub仓库中的评估示例文件夹获取详细的评估指南。数据集中的问题和图像可以用于训练和测试MLLMs,以评估其在工业检测任务中的性能。此外,数据集提供的掩码格式可用于进一步研究MLLMs在图像分割任务中的表现。用户还可以利用附带的文本描述进行多模态学习,探索文本与图像之间的关联。
背景与挑战
背景概述
MMAD数据集由Xi Jiang等研究人员于2024年提出,旨在为多模态大语言模型(MLLMs)在工业异常检测领域提供一个全面的基准测试。该数据集包含39,672个问题,覆盖8,366张工业图像,涵盖了从DS-MVTec、MVTec-AD、MVTec-LOCO、VisA到GoodsAD等多个来源的图像数据。MMAD的创建标志着工业检测领域中MLLMs能力的首次系统性评估,填补了该领域的研究空白。通过定义七个关键子任务,MMAD不仅评估了现有MLLMs在工业异常检测中的表现,还揭示了其在实际应用中的潜力与局限。该数据集的研究成果为工业质量检测的智能化转型提供了重要的理论支持与实践指导。
当前挑战
MMAD数据集在构建与应用过程中面临多重挑战。首先,工业异常检测本身具有高度复杂性,异常类型多样且表现形式各异,这对MLLMs的泛化能力提出了极高要求。其次,数据集的构建需要整合多源异构数据,确保图像与标注信息的高质量对齐,同时还需设计科学的问题生成与验证流程,以保证评估的客观性与准确性。此外,MLLMs在工业场景中的应用尚处于探索阶段,其性能与人类专家的差距仍需进一步量化与分析。这些挑战不仅反映了工业异常检测领域的技术瓶颈,也为未来研究提供了明确的方向与改进空间。
常用场景
经典使用场景
MMAD数据集在工业异常检测领域具有广泛的应用,特别是在多模态大语言模型(MLLMs)的评估和优化中。该数据集通过包含多种工业图像和对应的多选问题,为研究者提供了一个全面的基准测试平台。经典的使用场景包括对MLLMs在工业图像中的异常检测能力进行系统性评估,以及通过对比不同模型的性能,识别出最适用于工业质量检测的模型。
实际应用
在实际应用中,MMAD数据集被广泛用于工业质量检测系统的开发和优化。通过利用该数据集中的工业图像和多选问题,企业可以训练和评估多模态大语言模型,以提高自动化检测的准确性和效率。此外,该数据集还为工业异常检测算法的改进提供了丰富的数据支持,推动了工业智能化的发展。
衍生相关工作
MMAD数据集的发布催生了一系列相关研究工作,特别是在多模态大语言模型的工业应用领域。基于该数据集,研究者们开发了多种新的异常检测算法,并对现有模型进行了优化。此外,该数据集还激发了关于MLLMs在工业检测中性能瓶颈的深入探讨,推动了该领域的技术进步和学术交流。
以上内容由遇见数据集搜集并总结生成


