有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
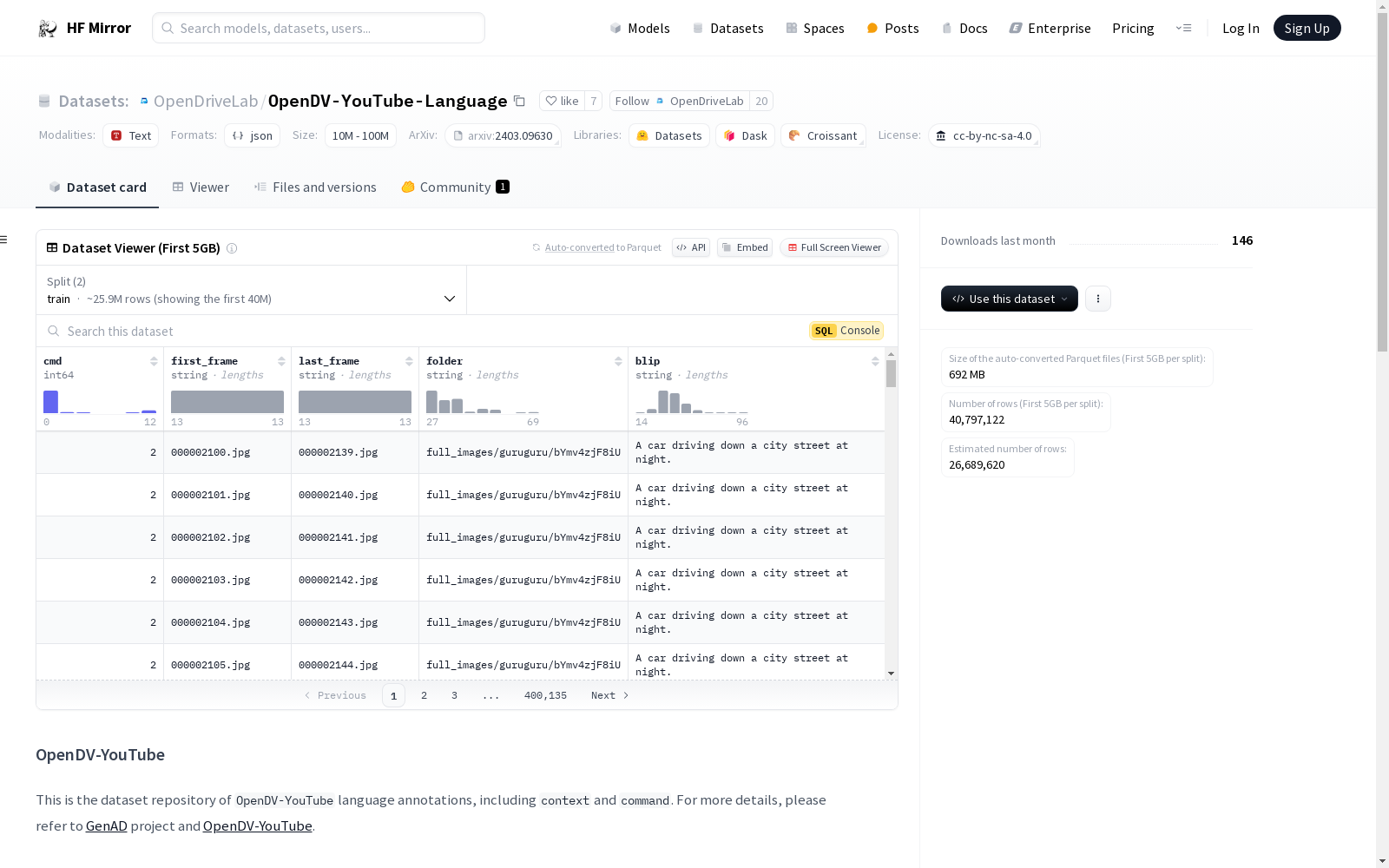
context和command两部分。数据准备:需按照OpenDV-YouTube的指导下载并准备数据。
环境建议:推荐在Linux环境下处理数据,因Windows可能存在文件路径问题。
代码示例: python import json
full_annos = [] for split_id in range(10): split = json.load(open("10hz_YouTube_train_split{}.json".format(str(split_id)), "r")) full_annos.extend(split)
val_annos = json.load(open("10hz_YouTube_val.json", "r"))
每个视频剪辑的标注: python { "cmd": <int> -- 命令,即视频剪辑中自我车辆的命令。 "blip": <str> -- 上下文,即视频剪辑中心帧的BLIP描述。 "folder": <str> -- 从处理后的OpenDV-YouTube数据集根目录到视频剪辑图像文件夹的相对路径。 "first_frame": <str> -- 剪辑中第一帧的文件名。 "last_frame": <str> -- 剪辑中最后一帧的文件名。 }
命令转换:使用map_category_to_caption函数将cmd字段转换为自然语言,详见cmd2caption.py。
上下文描述:blip字段描述视频剪辑中心帧,由BLIP2生成。
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
rule34lol-images-part1
该数据集包含来自rule34.lol图像板的196,000个图像文件的元数据。元数据包括URL、标签、文件信息和点赞数。实际图像文件存储在zip存档中,每个存档包含1000个图像。该数据集是更大集合的一部分,分为Part 1和Part 2。数据集采用CC0许可,允许免费使用、修改和分发,无需署名。
huggingface 收录
LibriSpeech
LibriSpeech 是一个大约 1000 小时的 16kHz 英语朗读语音语料库,由 Vassil Panayotov 在 Daniel Povey 的协助下编写。数据来自 LibriVox 项目的已读有声读物,并经过仔细分割和对齐。
OpenDataLab 收录