SynWBM
收藏arXiv2025-12-09 更新2025-12-11 收录
下载链接:
https://huggingface.co/datasets/ABC-iRobotics/SynWBM
下载链接
链接失效反馈官方服务:
资源简介:
SynWBM是由匈牙利奥布达大学智能机器人中心开发的合成数据集,专注于白蘑菇(Agaricus Bisporus)的实例分割任务。该数据集包含12,000张高分辨率(1024×1024)合成图像,涵盖25万多个蘑菇实例,通过Blender 3D渲染与扩散模型结合生成,实现了光照、纹理及几何形态的高度真实性。数据生成采用程序化建模技术,通过几何节点控制蘑菇年龄、形态随机性等参数,并结合泊松圆盘采样实现自然分布。该数据集旨在解决农业计算机视觉领域真实标注数据匮乏的问题,支持零样本迁移至真实场景的蘑菇检测与分割模型训练。
SynWBM is a synthetic dataset developed by the Intelligent Robotics Center of Óbuda University in Hungary, dedicated to the instance segmentation task of Agaricus Bisporus (white button mushrooms). This dataset comprises 12,000 high-resolution (1024×1024) synthetic images encompassing over 250,000 mushroom instances. Generated via a combination of Blender 3D rendering and diffusion models, it achieves exceptional realism in lighting, texture, and geometric morphology. The data generation process employs procedural modeling techniques, with parameters such as mushroom age and morphological randomness controlled through Geometry Nodes, and incorporates Poisson disk sampling to enable natural spatial distribution of mushroom instances. This dataset is designed to mitigate the shortage of real-world annotated data in agricultural computer vision, and supports zero-shot transfer for training mushroom detection and segmentation models in real-world scenarios.
提供机构:
安塔尔·贝兹智能机器人中心,奥布达大学研究与创新中心
创建时间:
2025-12-09
原始信息汇总
SynWBM (Synthetic White Button Mushrooms) 数据集概述
数据集基本信息
- 数据集名称: SynWBM Dataset
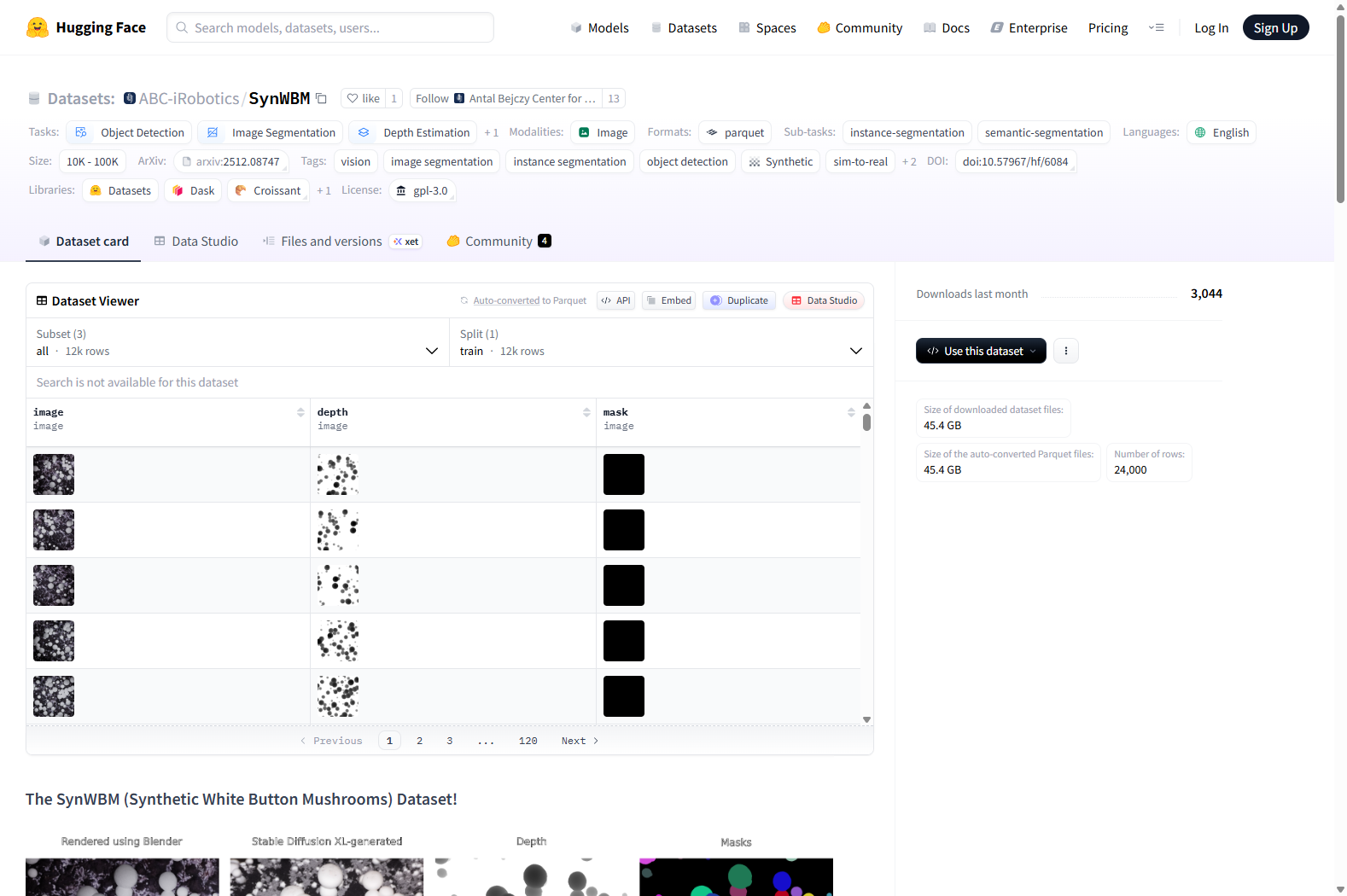
- 数据集描述: 白纽扣蘑菇(Agaricus bisporus)的合成数据集,包含实例分割掩码和深度图。
- 许可证: GNU General Public License v3.0
- 语言: 英语
- 标签: 视觉、图像分割、实例分割、目标检测、合成数据、仿真到现实、深度估计、图像到图像
- 标注创建方式: 机器生成
- 规模类别: 10K<n<100K
数据集结构与内容
数据样本
- 图像格式: 1024x1024x3 PNG 图像
- 标注格式:
- 实例分割掩码: 1024x1024x1 PNG 图像,使用 uint16 数据格式存储,每个像素值对应一个实例 ID。
- 深度图: 1024x1024x1 PNG 图像。
数据字段
image: 1024x1024x3 PNG 图像depth: 1024x1024x1 PNG 图像mask: 1024x1024x1 uint16 PNG 图像
数据配置与划分
数据集仅包含训练集,但提供三种配置以加载不同生成方法的图像:
| 配置名称 | 描述 | 训练集样本数 | 下载大小(字节) | 数据集大小(字节) |
|---|---|---|---|---|
all |
所有合成图像 | 12,000 | 22,677,841,215 | 22,712,394,633 |
blender |
仅 Blender 渲染图像 | 6,000 | 11,050,639,109 | 11,049,913,446 |
sdxl |
仅 Stable Diffusion XL 生成图像 | 6,000 | 11,626,921,894 | 11,662,481,187 |
default |
默认配置 | 12,000 | 21,573,770,746 | 21,702,540,415 |
支持的任务
- 目标检测
- 图像分割
- 实例分割
- 语义分割
- 深度估计
- 图像到图像转换
- 仿真到现实迁移学习的模型预训练
数据集创建与来源
创建缘由
为在真实世界图像中进行蘑菇实例分割,训练基于合成数据的实例分割模型。
数据来源
数据通过两种方法生成:
- Blender 渲染图像: 使用完全程序化的 Blender 场景生成,标注由 Blender Annotation Tool (BAT) 生成。
- Stable Diffusion XL 生成图像: 使用 ComfyUI 及数据集中提供的自定义工作流程生成。
使用信息
加载方式
可使用 🤗 Datasets 库加载数据集。支持流式模式以避免完整下载。
预期用途
数据集旨在用于以下研究:
- 蘑菇的实例分割
- 仿真到现实迁移学习
- 合成到真实领域的域适应
- 数据生成流程的基准测试
局限性
- 数据集仅包含合成图像,未提供真实世界样本。
- Stable Diffusion XL 生成图像可能包含伪影或不真实的结构。
- 深度标注来源于渲染/生成流程,可能无法反映真实世界传感器的噪声。
引用信息
如果使用本数据集,请引用相关预印本论文:
@misc{károly2025scalablepipelinecombiningprocedural, title={A Scalable Pipeline Combining Procedural 3D Graphics and Guided Diffusion for Photorealistic Synthetic Training Data Generation in White Button Mushroom Segmentation}, author={Artúr I. Károly and Péter Galambos}, year={2025}, eprint={2512.08747}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2512.08747}, }
搜集汇总
数据集介绍
构建方式
在工业蘑菇种植日益依赖计算机视觉的背景下,SynWBM数据集通过创新的混合流程构建而成。该流程首先在Blender中创建程序化的三维蘑菇场景,利用几何节点生成具有随机年龄、形态和分布的蘑菇实例,并通过泊松圆盘采样实现自然簇集布局。随后,采用Stable Diffusion XL扩散模型进行图像生成,通过深度ControlNet确保几何一致性,并集成IP-Adapter进行风格迁移,同时使用针对白蘑菇和堆肥专门训练的LoRA模块增强视觉真实性。整个流程自动生成高分辨率图像及对应的实例分割掩码,无需手动配置材质、光照等复杂渲染参数。
特点
SynWBM数据集展现出多维度独特优势。其核心在于实现了高度可控的几何布局与逼真视觉表现的融合,通过程序化生成机制确保了蘑菇尺寸、姿态和空间分布的广泛多样性,特别是模拟了真实种植中常见的遮挡与簇集现象。数据集包含两个版本:基于Blender直接渲染的图像和通过扩散模型生成的图像,均提供精确的实例级分割标注。生成图像在纹理细节、光照效果和背景真实性方面显著超越传统渲染,同时保持了与原始三维场景的几何对齐,为模型训练提供了兼具丰富语义信息和结构一致性的数据资源。
使用方法
该数据集专为基于深度学习的实例分割任务设计,尤其适用于蘑菇检测与分割模型的训练与评估。研究人员可直接使用提供的分割掩码作为监督信号,训练如Mask R-CNN等分割网络。数据集支持零样本迁移学习验证,用户可在M18K等真实世界基准上测试模型泛化能力。使用流程包括加载图像-掩码对进行模型训练,或利用其深度图进行域适应研究。数据集的程序化生成特性允许用户通过调整Blender场景参数或修改扩散模型提示词,灵活扩展数据规模和多样性,以适应不同的研究需求与应用场景。
背景与挑战
背景概述
随着工业蘑菇种植日益依赖计算机视觉进行监测与自动化采收,开发精确的检测与分割模型亟需大规模、精准标注的数据集,而真实数据采集成本高昂。为此,匈牙利欧布达大学Antal Bejczy智能机器人中心的Artúr I. Károly与Péter Galambos于2025年提出了SynWBM数据集,旨在通过合成数据生成技术解决双孢蘑菇(Agaricus Bisporus)实例分割任务中训练数据稀缺的核心问题。该数据集融合了Blender程序化三维图形与引导扩散模型,构建了包含12,000张高真实感合成图像及逾25万个蘑菇实例标注的规模化资源,为零样本场景下的模型训练提供了高效替代方案,显著推动了农业视觉领域合成数据应用的发展。
当前挑战
SynWBM数据集致力于应对农业视觉中蘑菇实例分割任务的数据稀缺与标注成本挑战,其核心在于弥合合成数据与真实场景之间的域差距,确保模型在真实环境中的泛化能力。在构建过程中,研究团队面临多重技术挑战:首先,程序化三维场景需精确模拟蘑菇的自然分布、遮挡与生长阶段,以生成具有几何多样性的合成图像;其次,扩散模型在生成高真实感图像时,需通过深度控制网络(ControlNet)、图像提示适配器(IP-Adapter)与低秩自适应(LoRA)等多组件协同,以保持对象形状一致并抑制无关生成;此外,合成数据与真实图像在纹理、光照及背景细节上的对齐亦需精细调优,以避免模型因域差异而性能下降。
常用场景
经典使用场景
在工业蘑菇种植的智能化进程中,SynWBM数据集为蘑菇实例分割任务提供了高质量的合成训练数据。该数据集通过融合三维程序化图形与引导扩散模型,生成具有真实感的合成图像,有效解决了传统计算机视觉方法依赖大规模标注数据的瓶颈。其经典应用场景在于训练基于深度学习的实例分割模型,如Mask R-CNN,用于蘑菇生长监测与自动化采收系统的开发。数据集包含大量蘑菇实例的精确掩码标注,能够支持模型在复杂遮挡和密集分布场景下的鲁棒性学习。
实际应用
在实际应用层面,SynWBM数据集直接服务于工业蘑菇种植的自动化系统。基于该数据集训练的模型可部署于智能采收机器人,实现蘑菇的实时检测与定位。数据集生成的工作流程具备高度可扩展性,能够适应不同蘑菇品种乃至其他农作物(如果实与叶片)的检测需求。这种合成数据生成方法为农业自动化提供了经济高效的数据解决方案,有助于提升生产效率和资源利用率。
衍生相关工作
SynWBM数据集衍生了一系列关于合成数据生成与域适应的经典研究工作。其核心方法启发了将程序化三维建模与扩散模型结合的技术路线,为后续研究如SMS3D等合成数据集提供了参考框架。数据集所采用的ControlNet引导生成、IP-Adapter风格迁移以及LoRA微调等技术,已成为合成数据生成领域的重要工具。这些工作共同推动了从合成到真实域适应方法的发展,为农业视觉任务的模型训练开辟了新的数据来源。
以上内容由遇见数据集搜集并总结生成


