Titung/seke-nepali-dataset
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/Titung/seke-nepali-dataset
下载链接
链接失效反馈官方服务:
资源简介:
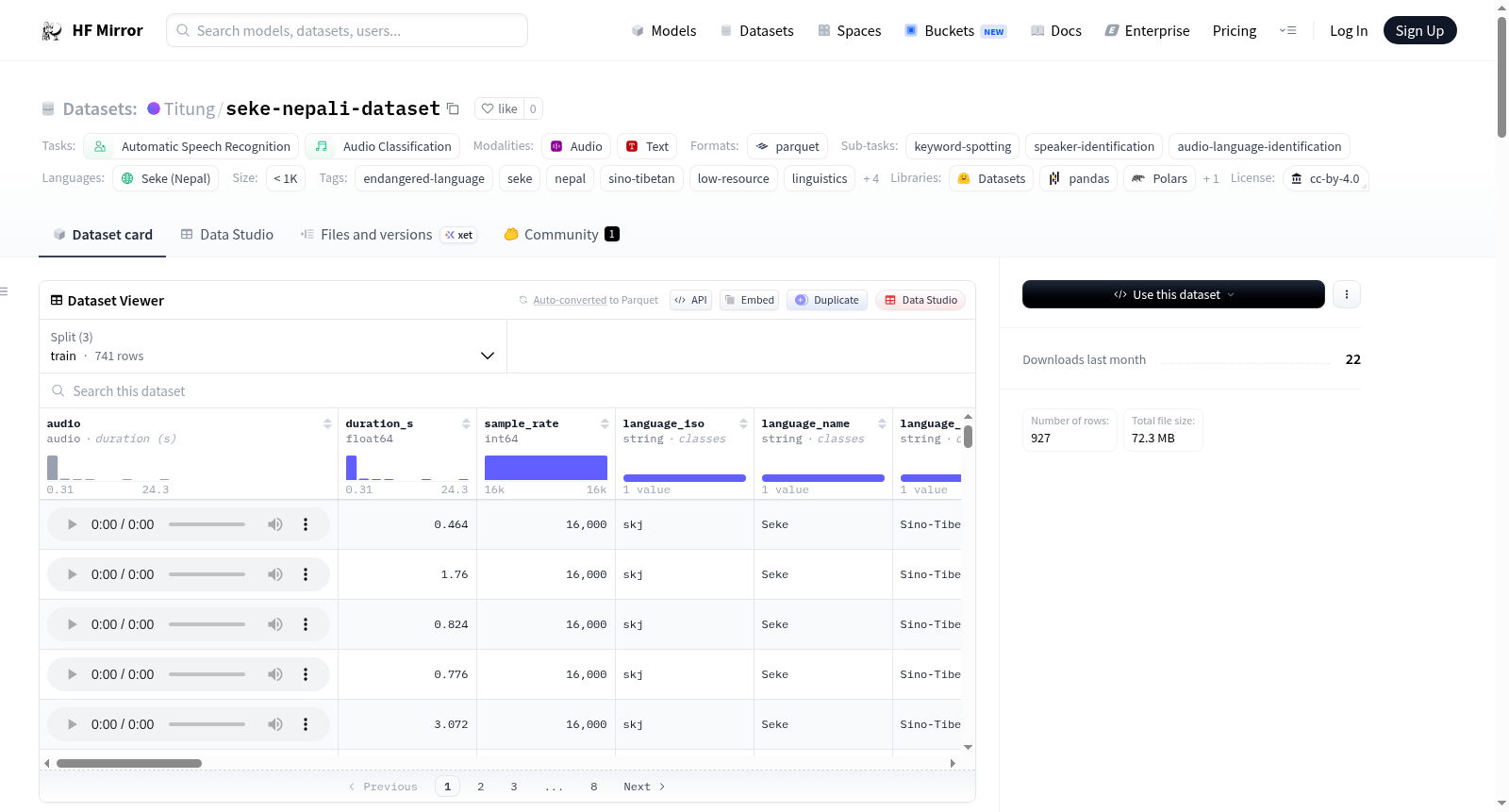
Seke(SKJ)语言数据集是一个关于濒危语言的音频语料库,主要收集了尼泊尔上木斯塘地区及纽约市散居社区中约700人使用的Sino-Tibetan语系濒危语言Seke的录音。数据集包含529个音频片段,总时长为17.8分钟,涉及2名说话者。音频格式为16kHz单声道WAV文件,并附有英语翻译、音标、语法类别等标注信息。数据集分为A、B、C三个质量等级,分别代表不同的录音质量和环境。该数据集旨在支持Seke语言的保护和学术研究,强调伦理使用和语言保护的重要性。
The Seke (SKJ) Language Dataset is an audio corpus of a critically endangered Sino-Tibetan language spoken by approximately 700 people in Upper Mustang, Nepal, and NYC diaspora communities. It includes 529 audio clips totaling 17.8 minutes, featuring 2 speakers. The audio is in 16kHz mono WAV format, accompanied by annotations such as English translations, IPA phonemes, and grammatical categories. The dataset is categorized into three quality tiers (A, B, C) based on recording conditions. It is intended for language preservation and academic research, with a strong emphasis on ethical use and community support.
提供机构:
Titung
搜集汇总
数据集介绍
构建方式
该数据集源自濒危语言联盟(Endangered Language Alliance)在互联网档案馆(Internet Archive)上公开的田野录音档案,由Anil Tamang整理汇编而成。音频材料于2018至2021年间在哥伦比亚大学及尼泊尔上木斯塘地区实地采集,涵盖两位母语者的语音样本。原始录音经过裁剪、归一化及降噪处理,统一转换为16kHz采样率、16位PCM编码的单声道WAV格式。数据集依据信噪比和录音环境质量划分为A(黄金级,控制条件下短指令)、B(白银级,优质田野录音)和C(青铜级,含背景噪声或长时段录音)三个质量层级,每个音频片段均附有对应的英语释义、罗马化转写、IPA音素标注及语法类别标签,构建了结构清晰、层次分明的语音语料库。
特点
作为迄今为止最为完整的Seke语公共音频语料库之一,该数据集专为极低资源、濒危语言的语音技术研究而设计。数据集共包含529个音频片段,总时长17.8分钟,所有音频均以16kHz采样率提供。其独特之处在于,每条记录均包含Whisper模型自动生成的罗马化近似转写、Allosaurus提取的IPA音素序列、斯瓦迪士核心词列表标记以及信号噪声比与响度等声学指标。此外,数据集中标注了语言描述型(515条)和原始文本型(14条)两种语言学类型,为句法分析、语音识别及说话人识别等任务提供了丰富的标注信息。
使用方法
用户可通过Hugging Face Datasets库便捷加载该数据集,使用`load_dataset("Titung/seke-nepali-dataset")`即可获取全部529条音频。针对高精度需求场景,可通过`filter`函数基于`quality_tier`字段筛选出A级黄金数据用于模型微调。数据集天然适配Whisper与Wav2Vec2等预训练模型,使用者可参照示例代码,利用`audio`字段中的波形数组与`gloss_en`字段的英语译文构建`input_features`和`labels`,完成语音识别系统的训练。同时,支持说话人识别与音频语言鉴别任务的直接应用,只需选择`speaker_name`或`linguistic_type`等字段作为监督信号即可。
背景与挑战
背景概述
Seke语(ISO 639-3: skj)是一种极度濒危的藏缅语族语言,全球仅约700人使用,主要分布于尼泊尔上木斯塘地区的五个村庄及纽约的离散社群。该数据集的创建源于濒危语言联盟(Endangered Language Alliance)与互联网档案馆的长期合作,由研究人员Anil Tamang于2026年整理发布,核心研究问题聚焦于为这种无标准文字的语言构建首个公开的语音语料库,以支持自动语音识别和音频分类任务。数据集包含了529条总时长17.8分钟的音频片段,记录了2018至2021年间由两位主要发音人提供的口语资料,并经过Whisper模型初步转写和语音学标注。其影响力在于为资源稀缺型濒危语言的自然语言处理研究提供了可复用的基础资源,推动了语音技术在人迹罕至的方言保护中的应用,同时为计算语言学和田野调查方法的融合树立了范例。
当前挑战
该数据集面临的挑战涵盖多个层面:首先,在领域问题层面,Seke语作为无标准化正字法的濒危语言,其语音识别任务缺乏准确的参照标注,导致Whisper等模型输出的转写仅为近似值,验证成本高昂,同时极低的资源规模(仅529个片段)使得传统监督学习方法难以有效泛化,音频分类任务亦受制于说话人数量极少和方言变体稀疏等问题。其次,在构建过程中,数据集源自不同环境和年代(2018–2021)的实地录音,其中大部分为B级和C级质量,存在明显的背景噪声、较长的语句片段和信噪比波动,对音频预处理如去噪、归一化及时长一致性提出了严苛要求;此外,缺乏统一的文字系统迫使研究者依赖临时性的罗马化转写方案,引发了转录一致性和语言学忠实度之间的张力,而伦理层面则需谨慎平衡数据公开共享与防止商业滥用、保护社群隐私之间的关系。
常用场景
经典使用场景
在极度低资源的语言处理领域,Seke语数据集为自动语音识别(ASR)和音频分类任务提供了宝贵的基准资源。该数据集包含529条源自田野录音和工作室采集的短语音片段,涵盖Swadesh词表、词汇与句子层面的语言描述。研究者常将其用于微调如Whisper和Wav2Vec2等预训练模型,以探索极小规模数据条件下语音识别系统的泛化能力。数据集按质量等级(A/B/C)划分,其中A级金标样本适用于受控条件下的基准测试,而B/C级样本则有助于开发对噪声环境鲁棒的自适应模型。这种结构化的质量分层策略,为低资源濒危语言的语音建模提供了可复现的实验范式。
解决学术问题
该数据集直面濒危语言语料匮乏的核心困境,为Sino-Tibetan语系下Bodish支语言的跨学科研究提供了罕见的可公开访问的语音样本。它解决了两个关键学术问题:其一,为缺乏标准正字法的语言建立可计算的音系-文字映射关系,通过IPA音素标注与Whisper转写近似,探索无监督或半监督的语音表征学习方法;其二,促进语音分类任务的领域迁移研究,如说话人识别、语种辨识和关键词检测,在仅有两个说话人的极紧凑数据集上评测模型对细粒度声学特征的捕获能力。该数据集的发布挑战了深度学习对大数据量的依赖假设,推动了低资源情境下语音技术方法论的重构。
衍生相关工作
该数据集衍生出一系列推动低资源语音研究的前沿工作。研究者基于此数据集探索了跨语言预训练模型在极度低资源场景下的适配机制,例如通过对比微调Whisper与Wav2Vec2在Seke语上的词错误率与音素错误率,分析模型对未见语言声学-音系结构的泛化瓶颈。此外,该数据集的Swadesh词表子集催生了小样本关键词检测和跨语言词汇相似度计算的研究,为Sino-Tibetan语系历史比较语言学提供了计算证据。数据集中包含的语音质量分层策略被后续多个濒危语言数据集采纳,成为田野录音数据标准化评估的参考框架,并启发了针对噪声鲁棒性和说话人混淆问题的系列基准测试方法。
以上内容由遇见数据集搜集并总结生成


