liuhaotian/LLaVA-CC3M-Pretrain-595K
收藏Hugging Face2023-07-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K
下载链接
链接失效反馈官方服务:
资源简介:
LLaVA Visual Instruct CC3M Pretrain 595K是CC-3M数据集的一个子集,经过过滤以提供更平衡的概念覆盖分布。该数据集用于视觉指令调优的预训练阶段,旨在构建具有GPT-4视觉/语言能力的大型多模态模型。数据集包含合成的多模态对话、元数据以及原始图像。
LLaVA Visual Instruct CC3M Pretrain 595K is a subset of the CC-3M dataset, filtered to deliver a more balanced distribution of concept coverage. This dataset is used for the pre-training phase of visual instruction tuning, with the purpose of building large multimodal models that possess the visual and language capabilities of GPT-4. The dataset includes synthesized multimodal dialogues, metadata, and raw images.
提供机构:
liuhaotian
原始信息汇总
LLaVA Visual Instruct CC3M 595K Pretrain Dataset Summary
基本信息
- 数据集名称: LLaVA Visual Instruct CC3M Pretrain 595K
- 语言: 英语
- 许可证: 必须遵守CC-3M和BLIP的许可证
- 创建时间: 2023年4月
数据集详情
- 类型: 是CC-3M数据集的一个子集,经过筛选以实现更平衡的概念覆盖分布。数据集中的标题与BLIP合成标题关联。
- 结构:
chat.json: 包含从图像-标题对合成的多模态对话,添加了随机选择的指令,用于LLaVA的预训练。默认答案使用原始CC-3M标题。metadata.json: 包含图像索引、文件名、URL、原始标题和合成标题的元数据。约10%的样本尚未关联BLIP标题。images.zip: 包含从CC-3M筛选出的所有原始图像。注意,这些图像仅供研究社区重现工作使用,不得用于其他目的。
使用目的
- 主要用途: 用于研究大型多模态模型和聊天机器人。
- 主要用户: 计算机视觉、自然语言处理、机器学习和人工智能领域的研究人员和爱好者。
搜集汇总
数据集介绍
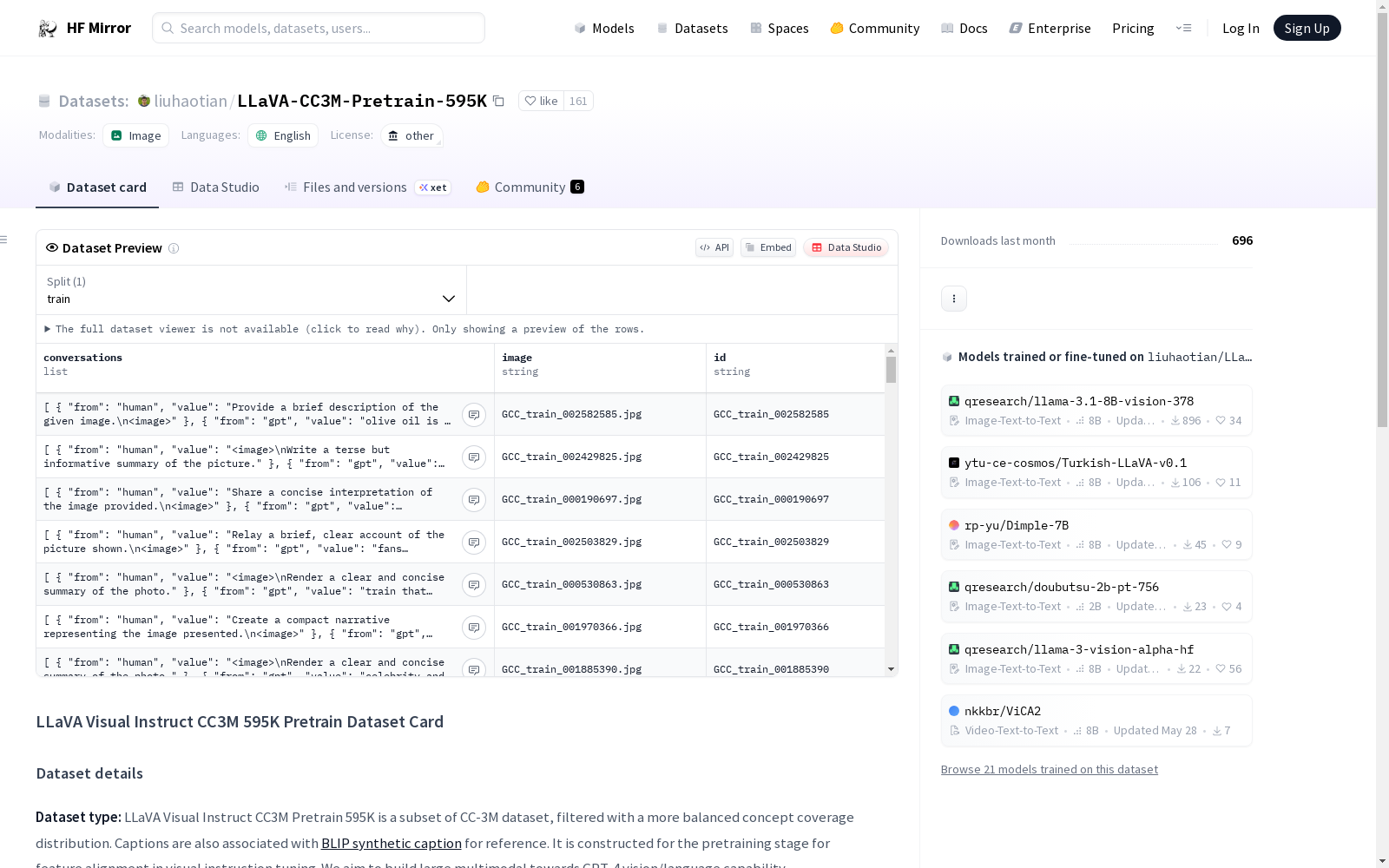
构建方式
LLaVA Visual Instruct CC3M Pretrain 595K数据集,作为CC-3M数据集的一个子集,通过筛选实现了更为均衡的概念覆盖率分布。该数据集旨在为视觉指令调整的特征对齐阶段提供预训练数据,包含图像-字幕对以及与之关联的BLIP合成字幕,以构建向GPT-4视觉/语言能力靠拢的大型多模态数据集。
特点
该数据集的特点在于,它不仅包含了原始的CC-3M字幕,还引入了BLIP合成字幕作为参考,有助于提升多模态模型在视觉指令理解方面的性能。此外,数据集通过提供图像索引的元数据,以及图像文件名、URL和不同来源的字幕,为研究人员提供了丰富的信息资源。特别值得一提的是,该数据集对大约15%无法访问的原始CC-3M图像进行了补充,以便更好地在研究社区中重现工作成果。
使用方法
使用LLaVA Visual Instruct CC3M Pretrain 595K数据集,用户可以通过`chat.json`文件进行多模态合成对话的预训练,其中包含了随机选择的指令,例如“描述这张图片”。同时,`metadata.json`文件提供了图像的元数据,包括图像索引、文件名、URL以及不同来源的字幕。`images.zip`文件包含了经过筛选的CC-3M子集的所有原始图像。在使用这些图像时,必须遵守CC-3M和BLIP的许可协议。
背景与挑战
背景概述
LLaVA Visual Instruct CC3M Pretrain 595K数据集,作为CC-3M数据集的一个子集,旨在通过平衡概念覆盖分布,为视觉指令调整的特征对齐预训练阶段构建大规模的多模态模型。该数据集的创建可追溯至2023年4月,由LLaVA项目团队精心打造,以逼近GPT-4的视觉/语言能力。LLaVA CC3M Pretrain 595K数据集不仅包含了多模态合成的对话,而且结合了BLIP合成字幕,以促进大规模多模态模型的预训练研究,对计算机视觉与自然语言处理领域产生了显著影响。
当前挑战
该数据集在构建过程中面临了多个挑战,首先是如何在保留CC-3M数据集原有特性的基础上,实现概念覆盖的均衡化。其次,由于大约15%的原始CC-3M数据集中的图像已无法访问,数据集构建者不得不上传图像压缩文件以满足研究社区的复现需求,同时确保图像的使用符合CC-3M的许可规定。此外,数据集还必须应对如何在多模态学习框架下有效整合视觉与语言信息,以及如何提升模型在真实世界任务中的泛化能力的挑战。
常用场景
经典使用场景
在深度学习领域,尤其是多模态模型的研究与开发中,LLaVA Visual Instruct CC3M 595K Pretrain Dataset 扮演着至关重要的角色。该数据集通过精心筛选,确保了概念覆盖的平衡性,并提供了丰富的视觉指令调优前的预训练资源。其经典的使用场景在于,通过对图像-文本对的深入分析,为大型多模态模型如GPT-4的视觉/语言能力的构建提供了坚实基础。
解决学术问题
该数据集解决了多模态模型训练中的关键问题,即如何通过视觉指令调优实现特征对齐。其独特的图像-文本对和合成对话设计,使得研究者在构建具有高度交互性和理解力的视觉语言模型时,能够更有效地进行预训练。这不仅提高了模型的泛化能力,也为学术研究提供了可靠的数据支持。
衍生相关工作
基于LLaVA Visual Instruct CC3M 595K Pretrain Dataset,已经衍生出一系列相关的研究工作。这些研究不仅涉及多模态模型的改进和优化,还包括了在视觉指令调优、图像描述生成、以及跨模态信息融合等领域的深入探索,进一步推动了视觉语言处理技术的发展和应用。
以上内容由遇见数据集搜集并总结生成


