DReAMy-lib/DreamBank-dreams-en
收藏Hugging Face2023-02-13 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/DReAMy-lib/DreamBank-dreams-en
下载链接
链接失效反馈官方服务:
资源简介:
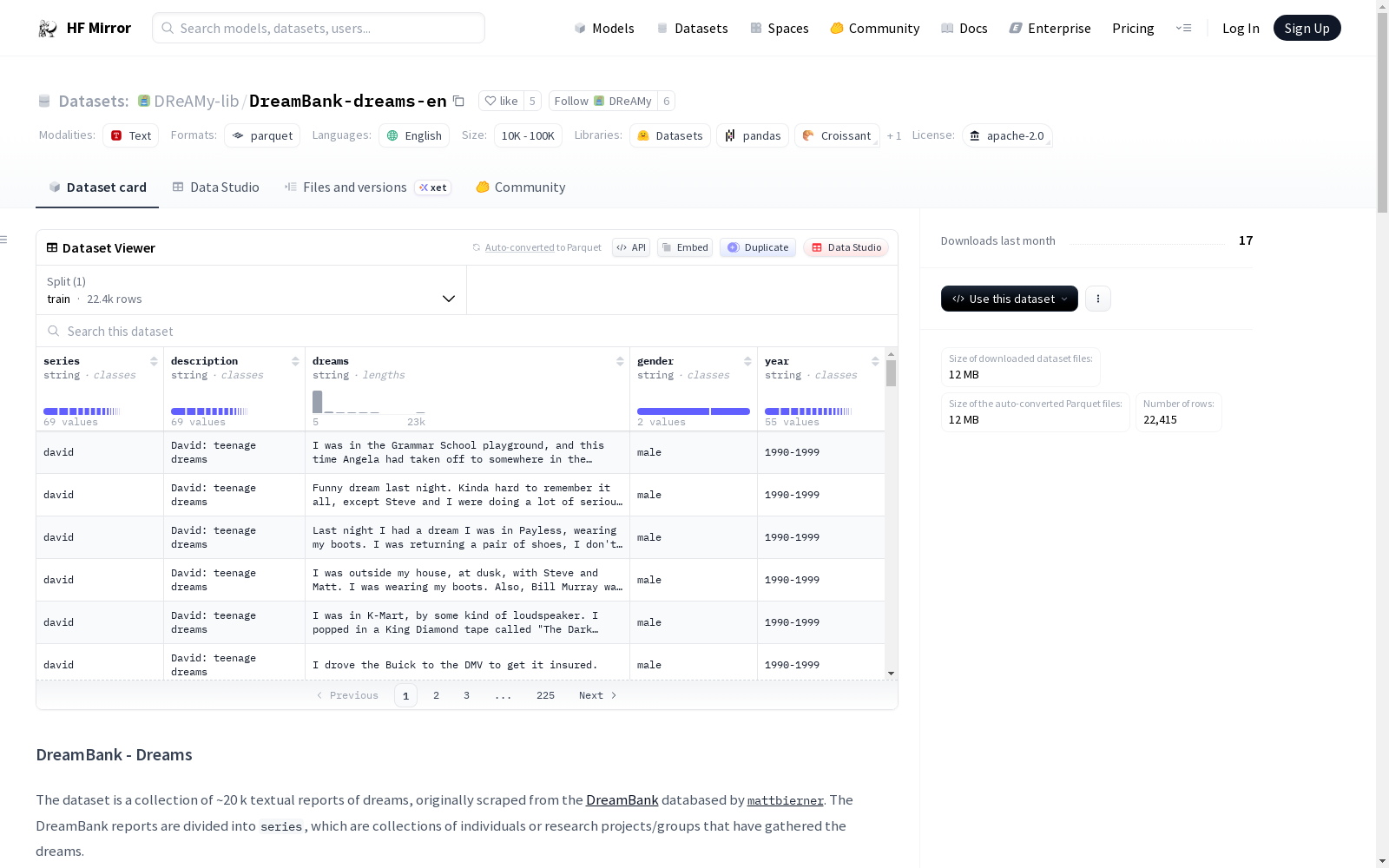
该数据集包含约20,000个梦境报告,这些报告最初是从DreamBank数据库中抓取的,并分为不同的series,每个series代表个人或研究项目/组收集的梦境。数据集的主要特征包括梦境内容、所属series、series的描述、性别和记录时间窗口。
This dataset contains approximately 20,000 dream reports, which were initially scraped from the DreamBank database. The reports are categorized into distinct series, where each series represents the dreams collected by an individual or a research project or group. The primary features of the dataset include dream content, the affiliated series, the series description, gender information, and the recording time window.
提供机构:
DReAMy-lib
原始信息汇总
数据集概述
基本信息
- 名称: DreamBank - Dreams
- 大小: 10K<n<100K
- 语言: 英语
- 许可证: Apache-2.0
数据集结构
- 特征:
series: 字符串,报告所属的系列description: 字符串,系列的简短描述dreams: 字符串,每个梦境报告的内容gender: 字符串,系列中个体(s)的性别year: 字符串,记录的时间窗口
数据集划分
- 训练集:
- 大小: 21,526,822 字节
- 样本数: 22,415
下载信息
- 下载大小: 11,984,242 字节
系列分布
- 数据集包含多个系列,每个系列有不同数量的梦境报告,例如:
alta: 422angie: 48arlie: 212- ... (其他系列及其报告数量)
搜集汇总
数据集介绍
构建方式
在梦境研究领域,DreamBank数据集通过系统化采集与整理,构建了约两万条梦境报告。该数据集源自DreamBank数据库,由mattbierner进行网络爬取,将梦境报告按系列划分,每个系列代表个体或研究项目的梦境集合。数据涵盖系列名称、描述、梦境内容、性别及记录年份等特征,确保了数据的结构化和可追溯性。
特点
DreamBank数据集以其丰富的梦境文本和多元的系列分布而著称,涵盖多个个体与研究项目,如alta、b、elizabeth等系列,每个系列包含数十至数千条报告。数据特征包括梦境内容、系列描述、性别信息和记录时间窗口,提供了跨性别、年龄和背景的梦境多样性,为心理学和认知科学研究提供了宝贵资源。
使用方法
在梦境分析与自然语言处理应用中,DreamBank数据集可用于训练模型以探索梦境内容的模式与情感。用户可通过HuggingFace平台加载数据集,访问训练分割中的梦境报告,结合系列和性别特征进行统计分析或机器学习任务。数据支持英语处理,适用于文本生成、分类或跨系列比较研究,促进梦境科学的实证探索。
背景与挑战
背景概述
DreamBank数据集作为梦境研究领域的重要资源,由DReAMy-lib团队于近年整理并发布,其原始数据源自DreamBank数据库,经由mattbierner等研究者通过DreamScrape工具系统采集。该数据集汇聚了约两万份英文梦境文本报告,涵盖多个独立系列,如alta、b、norman等,每个系列均附有描述、性别及年份信息。其核心研究问题聚焦于探索梦境内容的语言学特征、心理象征意义以及跨文化差异,为心理学、认知科学及自然语言处理领域提供了宝贵的实证材料,推动了梦境分析的定量化与计算化进程。
当前挑战
该数据集旨在解决梦境文本自动分析与理解这一跨学科难题,其挑战在于梦境报告具有高度主观性、隐喻性及非结构化特征,使得传统文本分类与语义建模方法难以直接应用。在构建过程中,研究者面临数据采集的伦理与隐私考量,需确保匿名化处理;同时,原始梦境文本的噪声较大,如拼写错误、口语化表达及文化特异性内容,增加了数据清洗与标注的复杂度。此外,系列间的不平衡分布,如某些系列样本量稀少,可能影响模型训练的泛化能力,要求后续研究采用更精细的数据增强或迁移学习策略。
常用场景
经典使用场景
在梦境研究领域,DreamBank数据集为探索人类梦境的语言特征与心理状态关联提供了关键资源。该数据集通过收集约两万份梦境文本报告,涵盖了不同性别、年龄和背景的个体,使得研究者能够系统分析梦境内容的词汇分布、情感倾向和叙事结构。经典使用场景包括利用自然语言处理技术,如主题建模和情感分析,来识别梦境中的常见主题,例如焦虑、愿望或日常经历的再现,从而揭示潜意识活动的模式。
衍生相关工作
基于DreamBank数据集,衍生出多项经典研究工作,包括梦境情感分类模型和跨文化梦境比较分析。研究者利用该数据集训练了深度学习模型,如BERT变体,以自动识别梦境中的情绪标签,相关成果发表在计算语言学会议上。此外,结合其他梦境数据库,学者开展了大规模跨文化研究,探讨梦境内容与社会环境的交互影响,这些工作深化了我们对梦境普遍性与多样性的理解,并促进了跨学科合作。
数据集最近研究
最新研究方向
在心理学与计算语言学的交叉领域,DreamBank梦境数据集正推动着前沿研究的发展。该数据集收录了约两万份梦境文本报告,为探索梦境内容与个体心理状态、社会文化背景之间的关联提供了丰富资源。当前研究热点聚焦于利用自然语言处理技术分析梦境文本的情感倾向、主题演化及叙事结构,进而揭示潜意识活动与心理健康、创伤后应激障碍等临床问题的潜在联系。梦境数据的时序性与人口统计学信息相结合,使得研究者能够追踪不同性别、年龄群体在长期或特定事件下的梦境模式变化,为认知神经科学提供实证依据。这些探索不仅深化了人类对梦境功能的理解,也在人工智能生成内容、情感计算等应用场景中展现出跨学科价值。
以上内容由遇见数据集搜集并总结生成


