Vad-Reasoning
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
https://github.com/wbfwonderful/Vad-R1
下载链接
链接失效反馈官方服务:
资源简介:
Vad-Reasoning数据集是一个专门为视频异常推理任务设计的数据集,包括两个互补的子集。一个子集包含带有P2C-CoT标注的视频,由私有模型逐步生成;另一个子集包含大量视频,由于标注成本高,只有视频级别的弱标签。数据集旨在通过模拟人类对视频异常的理解过程,引导多模态大型语言模型(MLLMs)逐步推理异常事件,从而实现更深入的分析和理解。
Vad-Reasoning Dataset is a specialized dataset designed for the video anomaly reasoning task, comprising two complementary subsets. One subset contains videos annotated with P2C-CoT, which are generated step-by-step by a proprietary model. The other subset includes a large number of videos that only have video-level weak labels due to the high annotation cost. This dataset aims to guide multimodal large language models (MLLMs) to conduct step-by-step reasoning on anomalous events by simulating the human process of understanding video anomalies, thereby enabling more in-depth analysis and comprehension.
提供机构:
深圳校区中山大学, 哈尔滨工业大学深圳, 香港理工大学
创建时间:
2025-05-26
原始信息汇总
Vad-R1 数据集概述
基本信息
- 数据集名称:Vad-R1
- 官方仓库:https://github.com/wbfwonderful/Vad-R1
- 相关论文:https://arxiv.org/abs/2505.19877
研究背景
- 提出Vad-R1,一种新颖的端到端基于MLLM的框架,专为视频异常推理(VAR)设计,旨在进一步分析和理解视频中的异常。
数据集特点
- 设计方法:构建了结构化感知-认知链式思维(Perception-to-Cognition Chain-of-Thought)。
- 数据集组成:包含两个子集的Vad-Reasoning数据集,专门为视频异常推理设计。
- 算法改进:提出改进的强化学习算法AVA-GRPO,通过自我验证方式激励MLLMs的推理能力。
实验成果
- 实验结果表明,Vad-R1在多种评估场景中均表现出优越性能,在视频异常检测和推理任务中超越开源和专有模型。
搜集汇总
数据集介绍
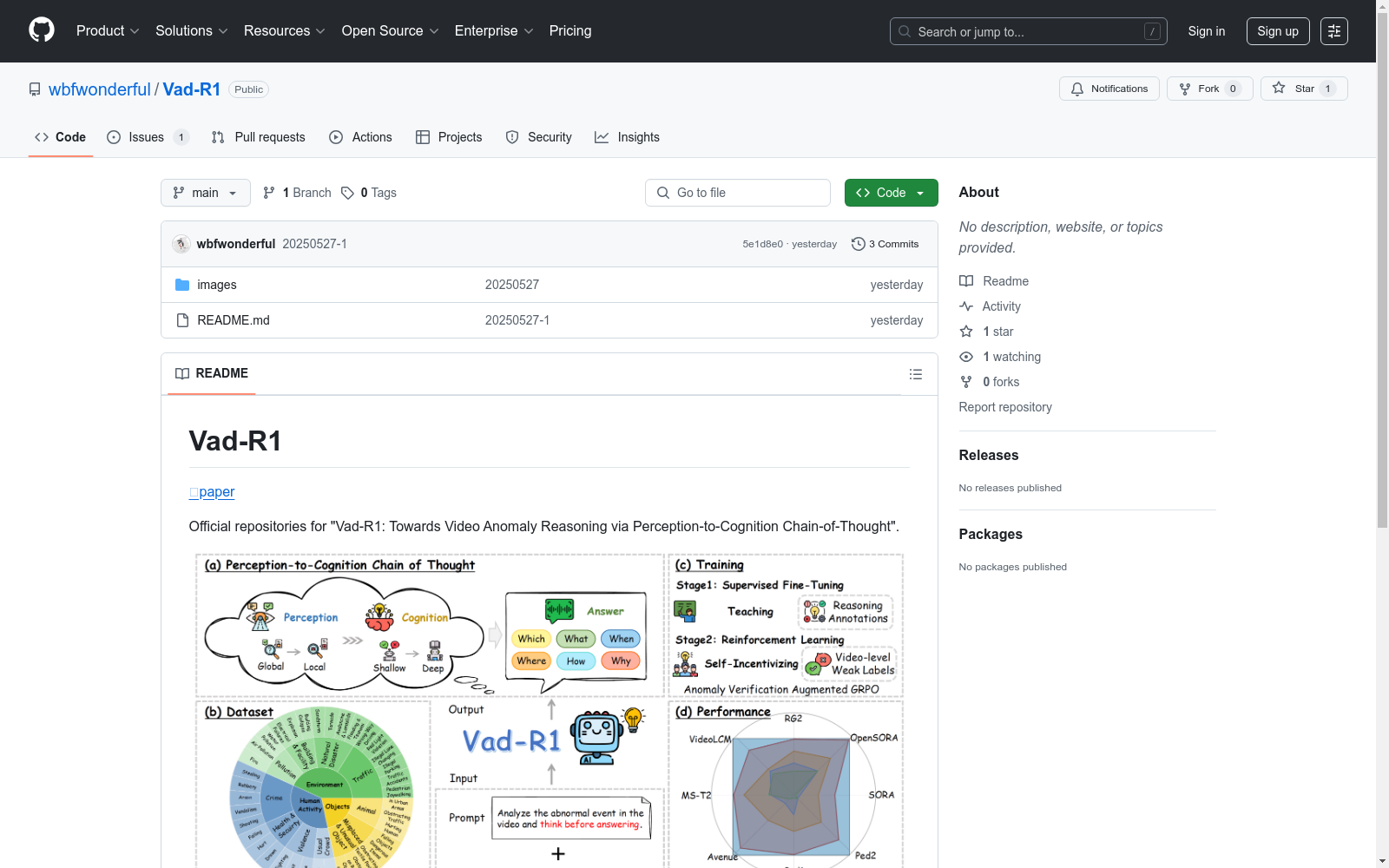
构建方式
Vad-Reasoning数据集的构建采用了多阶段标注流程,结合了感知到认知的思维链(P2C-CoT)方法。首先,通过Qwen-VL-Max生成视频帧的密集描述,随后利用Qwen-Max逐步生成思维链注释。数据集包含两个互补子集:一个子集包含带有P2C-CoT注释的视频,另一个子集包含仅带有视频级弱标签的大量视频。这种结构化的标注方法确保了数据的高质量和逻辑连贯性。
特点
Vad-Reasoning数据集的特点在于其精细的异常类别标注和结构化推理注释。数据集覆盖了广泛的现实场景,包括监控犯罪、暴力事件、交通异常等,并定义了人类活动异常、环境异常和物体异常三大类。每个类别进一步细分为多个子类别,确保了数据的多样性和全面性。此外,数据集的注释平均长度为260词,详细模拟了人类对异常事件的推理过程。
使用方法
Vad-Reasoning数据集的使用方法包括两个主要阶段:监督微调(SFT)和强化学习(RL)。在SFT阶段,模型使用带有高质量推理注释的视频进行训练,以掌握基本的异常推理能力。在RL阶段,通过提出的AVA-GRPO算法,利用视频级弱标签进一步激励模型的推理能力。用户可以根据需要选择使用完整的P2C-CoT注释或仅使用最终答案部分进行训练和评估。
背景与挑战
背景概述
Vad-Reasoning数据集由中山大学深圳校区、哈尔滨工业大学(深圳)和香港理工大学的研究团队于2025年提出,旨在推动视频异常推理(Video Anomaly Reasoning, VAR)任务的发展。该数据集基于感知-认知思维链(P2C-CoT)框架构建,模拟人类分析视频异常的认知过程,要求多模态大语言模型(MLLMs)通过结构化推理步骤对异常事件进行深层理解。作为首个专注于异常推理的基准数据集,Vad-Reasoning填补了传统视频异常检测方法仅停留在浅层描述的局限性,对智能监控、自动驾驶等领域的决策支持系统具有重要价值。
当前挑战
该数据集面临两大核心挑战:在领域问题层面,需解决现有视频异常检测方法缺乏深度推理能力的问题,要求模型不仅识别异常,还需完成时空定位、社会规范违反分析等复杂认知任务;在构建过程中,面临标注成本高昂的难题——需为1755条视频逐帧生成包含环境感知、局部异常定位、浅层认知和深层因果推理的四级结构化标注,同时处理6448条视频的弱标签数据。此外,数据覆盖13类细粒度异常场景(如暴力事件、交通违规等),需平衡场景多样性与标注一致性的矛盾。
常用场景
经典使用场景
Vad-Reasoning数据集在视频异常检测与理解领域具有经典应用场景,其核心价值在于通过感知-认知链式思维(P2C-CoT)框架,推动多模态大语言模型(MLLMs)从浅层异常描述转向深度推理。该数据集常用于训练模型逐步分析视频中的异常事件,包括环境感知、局部异常定位、浅层因果推断及深层社会规范违反分析等标准化流程。例如,在监控安防场景中,模型可基于P2C-CoT结构,先识别整体场景中的正常模式,再聚焦于特定时空范围内的异常行为(如暴力事件或交通违规),最终输出包含事件类别、时空定位、因果解释的完整推理链。
实际应用
该数据集在智慧城市、自动驾驶等实际场景中展现出显著价值。在智能监控领域,部署基于Vad-Reasoning训练的模型可实时分析监控视频中的异常事件(如盗窃或交通事故),并生成包含时空定位与合规性分析的报告,提升安防系统决策效率。在自动驾驶测试中,模型能识别道路上的非常规物体(如障碍物或违规行人),并通过因果推理预测潜在风险。实验表明,相关模型在UCF-Crime等真实场景数据集上F1分数达0.862,较传统方法提升13.3%,验证了其工程落地潜力。
衍生相关工作
Vad-Reasoning催生了多个视频异常分析领域的衍生研究:其一,HAWK等工作借鉴其多模态提示框架,开发了开放世界视频异常检测系统;其二,HolmesVAU等模型受P2C-CoT启发,构建了细粒度异常理解架构;其三,Video-R1等研究基于AVA-GRPO算法扩展至时空推理任务。数据集本身亦整合了UCF-Crime、XD-Violence等6个主流数据源的视频,推动建立跨场景评估基准VANE。这些工作共同推进了视频理解从模式识别向认知推理的范式转变。
以上内容由遇见数据集搜集并总结生成


