harshal3099/apex-food-rd-chatml-v3-flavour
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/harshal3099/apex-food-rd-chatml-v3-flavour
下载链接
链接失效反馈官方服务:
资源简介:
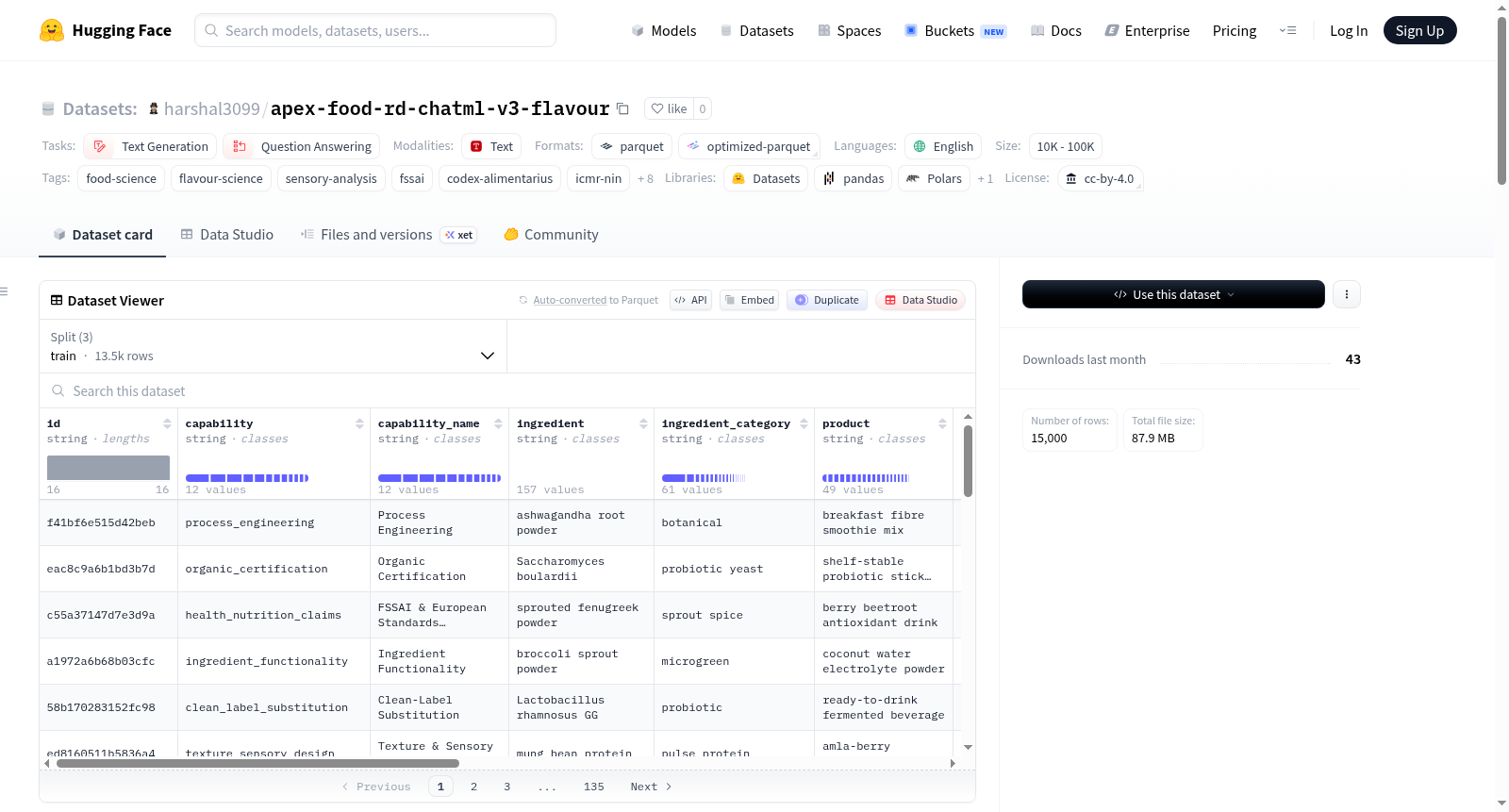
Apex Food R&D ChatML v3数据集是v2数据集的扩展版本,新增了第12项能力:风味与味觉系统设计。该数据集涵盖了印度风味调色板设计、甜度调节、苦味掩蔽系统、酸甜平衡、香料与风味搭配、乳制品与水风味差异、天然风味系统、风味前/中/基调、粉末中的风味释放、甜叶菊/罗汉果的后味控制、可可/咖啡/麦芽/水果/香料风味架构、儿童/成人/侨民口味偏好、感官小组评分系统、享乐测试、JAR量表测试、描述性分析、保质期内的风味稳定性、风味氧化与包装相互作用、以及益生菌/蘑菇/藻类/辣木/南非醉茄/豌豆蛋白/小米等功能性成分的掩蔽。数据集包含15,000个示例,其中3,000个专门用于风味/味觉设计,格式为ChatML messages。推荐使用Qwen/Qwen3-4B作为基础模型。数据集适用于SFT响应风格、食品配方推理、风味/感官设计推理和法规引用行为,但不替代产品上市前的直接法律/法规验证。
The Apex Food R&D ChatML v3 dataset extends the v2 dataset by adding a dedicated 12th capability: Flavour & Taste System Design. This new capability covers Indian flavour palette design, sweetness modulation, bitterness masking systems, acid-sweet balance, spice-flavour pairing, dairy vs water flavour differences, natural flavour systems, flavour top/middle/base notes, flavour release in powders, aftertaste control for stevia/monk fruit, cocoa/coffee/malt/fruit/spice flavour architectures, children vs adults vs diaspora taste preference, sensory panel scoring systems, hedonic testing, JAR scale testing, descriptive analysis, flavour stability during shelf life, flavour oxidation and packaging interaction, and masking of probiotics, mushrooms, algae, moringa, ashwagandha, pea protein, millets and other functional ingredients. The dataset contains 15,000 examples, with 3,000 dedicated to flavour/taste design, formatted as ChatML messages. The recommended base model is Qwen/Qwen3-4B. The dataset is suitable for SFT response style, food formulation reasoning, flavour/sensory design reasoning and regulatory citation behaviour, but it is not a substitute for direct legal/regulatory verification before product launch.
提供机构:
harshal3099
搜集汇总
数据集介绍
构建方式
该数据集在Apex Food R&D v2版本基础上进行扩展,新增了第12项核心能力——风味与味觉系统设计。以Qwen3-4B为推荐基座模型,采用ChatML消息格式,共计包含15,000条样本,其中训练集13,500条、验证集750条、测试集750条,新增专属风味样本3,000条。数据集基于经过精心筛选的137种印度本土功能性、天然及有机原料知识库构建,涵盖小米、豆类、种子、香料、草药、印度水果、绿叶蔬菜、微藻、蘑菇及益生菌菌株等多样成分。每条样本均严格引用FSS法案、Codex Alimentarius、ICMR-NIN膳食指南、NPOP有机标准及ISO感官分析指导等权威法规与科学文献,通过系统化推理生成合成数据,以确保其在食品配方与感官设计领域的专业性和可靠性。
特点
该数据集的一大特色在于深度融合了印度本土风味调色板设计,涵盖甜度调节、苦味掩蔽、酸甜平衡、香料风味配对、乳品与水质风味差异等细腻维度,并细致划分了风味的前调、中调与基底层次。其在感官评估方面引入了描述性分析、享乐测试及JAR标度量表等系统化方法。同时,数据集特别关注功能性配料如益生菌、蘑菇、藻类、辣木、印度人参、豌豆蛋白及小米等所引发的异味掩蔽与风味稳定性问题,并延伸至货架期内的风味氧化及包装交互效应。基于权威法规的合规性推理与跨年龄段、跨文化味觉偏好差异的考量,使其在食品研发与法规审查领域具有高度的实用价值。
使用方法
使用该数据集时,建议以Qwen3-4B作为基座模型进行监督微调(SFT)或LoRA微调,训练完成后可导出为GGUF格式模型以便于部署应用。数据集以ChatML消息格式存储,可直接用于自然语言生成与问答任务,主要面向食品配方推理、风味与感官系统设计、法规引用行为优化等场景。用户需注意,该数据集为基于知识库生成的高质量合成数据,并非官方法规的直接替代,在真实产品上市前仍需对照最新的FSSAI通知及官方PDF文件进行合规性验证。适用于食品科学家、产品研发人员及法规事务专家在开发功能性、清洁标签及有机食品时的辅助决策与模型训练。
背景与挑战
背景概述
在食品科学与风味工程交叉领域,精准的配方设计与感官体验优化是产品研发的核心挑战。该数据集由Apex Food R&D团队于2024年创建,以印度食品工业为场景,聚焦于拓展食品配方、法规合规及风味系统设计的合成数据资源。其核心研究问题在于如何通过机器学习模型,将复杂的食品科学知识(包括印度风味架构、苦味掩蔽、甜味调控等)与严格的监管框架(如FSSAI、Codex Alimentarius)结合,生成可辅助研发决策的结构化对话数据。数据集包含15,000条基于ChatML格式的问答对,覆盖12项研发能力,其中新引入的风味与味觉系统设计能力贡献了3,000条样本。该数据集专为优化Qwen3-4B等因果语言模型在食品配方推理与法规引用行为上的监督微调而设计,对推动食品人工智能在区域化、多约束条件下的应用具有重要参考价值。
当前挑战
该数据集所解决的领域挑战在于,食品研发面临全球化与本土化的双重需求:一方面需要满足国际标准如Codex GSFA的合规性,另一方面需适应印度特有的食材(如小米、藻类、豆类蛋白)和风味偏好(如儿童与侨民的口味差异)。传统食品科学知识体系分散在法规文本、感官分析报告与配方经验中,难以被机器学习模型系统化利用。在构建过程中,团队面临的主要挑战包括:合成数据的知识准确性保障,需从FSS Act 2006至EU Regulation 1334/2008等数十项法规中提取并推理;风味系统设计涉及跨学科的复杂交互,如掩盖功能性成分(益生菌、辣木、豌豆蛋白)的不良味道,需同时考虑氧化稳定性、包装交互与保质期变化;此外,还需平衡15,000条样本中13项能力的分布,确保模型在法规引用、感官评分与配方逻辑上获得均衡的微调效果,避免过拟合于单一子任务。
常用场景
经典使用场景
该数据集最经典的使用场景在于食品科学与风味系统设计领域,尤其是在面向印度本土及国际市场的功能性食品与清洁标签产品研发中。通过整合137种具有印度特色的功能性、天然及有机原料,数据集为模型提供了丰富的配方设计知识,涵盖从成分功能、法规合规到保质期预测的完整研发链条。其独特之处在于新增的风味与味觉系统设计能力,支持甜度调节、苦味掩蔽、酸甜平衡、香料风味配对以及天然风味系统构建等细腻任务,使模型能够模拟食品科学家的决策逻辑,生成符合感官评价标准且兼具法规依据的食品配方文本。
衍生相关工作
基于该数据集,研究者已开发出一系列衍生工作,主要集中在食品配方的自动生成与法规合规性验证两个方向。例如,有工作利用该数据集训练Qwen3-4B模型后,通过低秩适应微调使其能够针对特定功能声称(如“高蛋白”“无添加糖”)生成符合FSSAI与欧盟法规的完整产品标签文本。另一项衍生研究则聚焦于感官描述词的标准化生成,结合ISO 13299感官剖面分析指引,使模型能够输出结构化的风味轮分析报告。此外,该数据集还催生了面向印度市场的发酵食品配方优化工具,通过结合其发酵科学与风味设计模块,帮助传统食品实现工业化升级。
数据集最近研究
最新研究方向
在食品科学与感官分析的前沿领域,该数据集聚焦于风味与味觉系统设计的深度建模,特别是在印度本土风味谱系、甜味调控、苦味掩蔽体系及天然风味架构等方向。结合清洁标签、功能性食品及益生菌等热点趋势,数据集创新性地整合了感官评分、享乐测试与描述性分析等量化评估方法,并紧密关联FSSAI、Codex Alimentarius等监管框架,为食品配方研发与法规合规提供了高精度的合成数据支持。其引入的3300余条风味专用样本,显著推动了多模态感官推理与稳定化包埋技术的进展,对印度及全球食品工业的功能性产品开发与个性味觉定制具有里程碑意义。
以上内容由遇见数据集搜集并总结生成


