Tox21-V-Train
收藏Hugging Face2025-10-22 更新2025-10-22 收录
下载链接:
https://huggingface.co/datasets/molvision/Tox21-V-Train
下载链接
链接失效反馈官方服务:
资源简介:
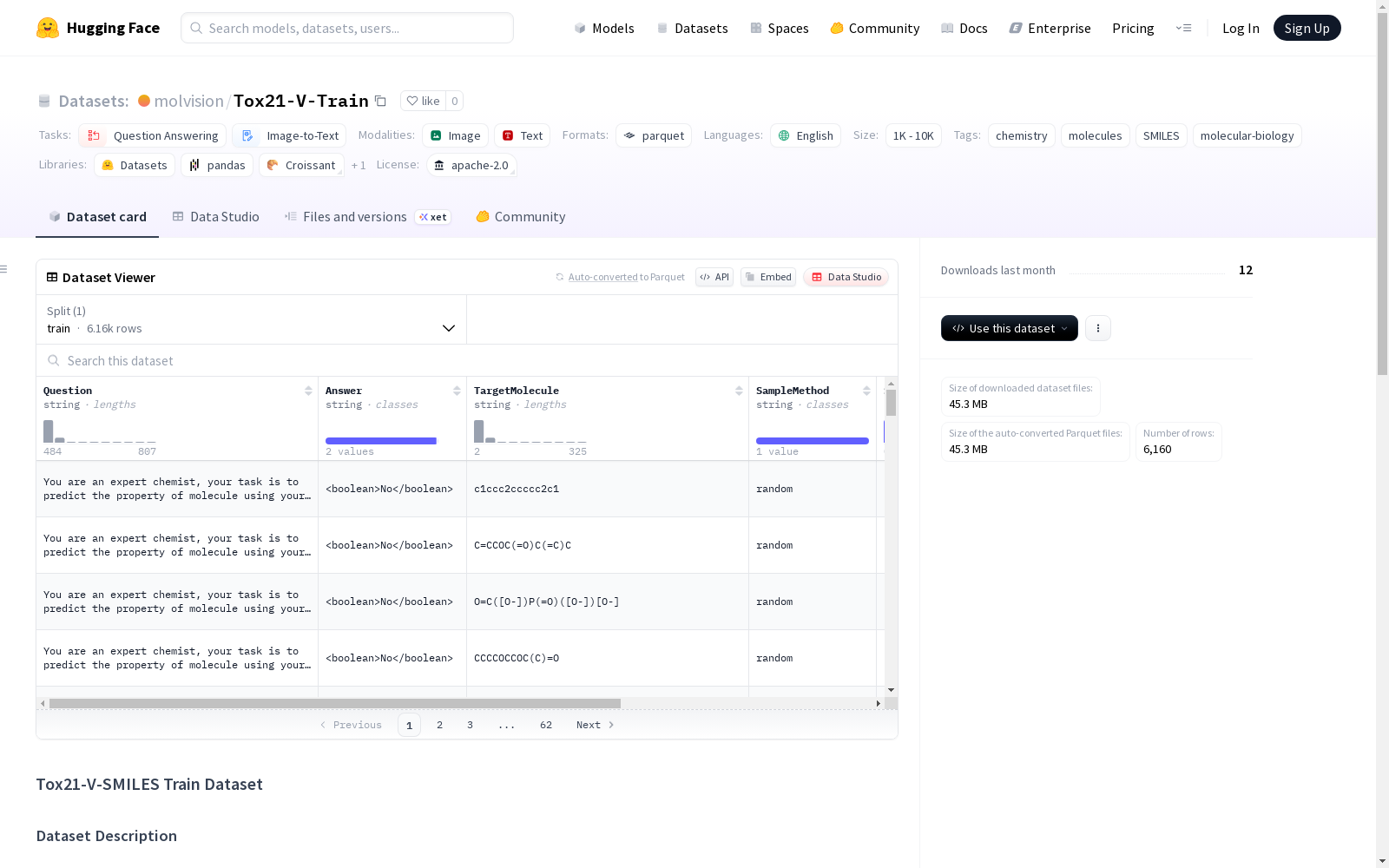
Tox21-V-SMILES训练数据集包含与Tox21相关化合物的分子数据和视觉表示。数据集中的字段包括相关问题、对应答案、目标分子的SMILES表示、采样方法、样本数量、样本重复以及生成的分子结构图像。
The Tox21-V-SMILES training dataset contains molecular data and visual representations of Tox21-related compounds. The fields included in this dataset are: relevant questions, corresponding answers, SMILES representations of target molecules, sampling method, number of samples, sample replicates, and generated molecular structure images.
创建时间:
2025-10-21
原始信息汇总
Tox21-V-SMILES Train Dataset 概述
数据集基本信息
- 许可证: Apache-2.0
- 任务类别: 问答、图像到文本
- 语言: 英语
- 领域标签: 化学、分子、SMILES、分子生物学
- 数据规模: 1K<n<10K
数据集描述
包含Tox21相关化合物的分子数据和视觉表示。
核心特征
- 问题: 与分子相关的问题
- 答案: 对应的回答
- 目标分子: 目标分子的SMILES表示
- 采样方法: 使用的采样方法
- 样本编号: 样本编号
- 样本重复: 样本重复
- 图像: 从SMILES生成的分子结构图像
数据集统计
- 总样本数: 6160
- 图像格式: PIL图像(RGB)
- 图像尺寸: 300x300像素
数据字段说明
Question(字符串): 问题文本Answer(字符串): 答案文本TargetMolecule(字符串): SMILES表示SampleMethod(字符串): 采样方法SampleNum(整数): 样本编号SampleRep(字符串): 样本重复image(PIL.Image): 分子结构可视化
使用方法
python from datasets import load_dataset dataset = load_dataset("molvision/Tox21-V-Train")
引用要求
如在研究中使用本数据集,请引用。
搜集汇总
数据集介绍
构建方式
在计算化学与分子生物学交叉领域,Tox21-V-Train数据集通过系统化整合Tox21计划中化合物的多模态信息构建而成。其核心方法涵盖从标准化SMILES序列生成分子结构图像,并采用分层采样策略确保数据代表性。每个样本均关联特定问答对,通过自动化流程将化学表征与语义描述精准对应,形成结构化的视觉-文本映射体系。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,调用load_dataset函数即可获取包含图像、文本及元数据的完整结构。典型应用流程包括解析SMILES序列与对应分子图像的关系建模,或基于问答对开发分子属性预测模型。数据字段的标准化设计支持端到端的多任务学习,为药物毒性筛查与分子理解研究提供即用型基准。
背景与挑战
背景概述
在计算毒理学与药物发现领域,分子性质预测始终是核心研究议题。Tox21-V-Train数据集由分子视觉研究团队于21世纪毒性筛查计划框架下构建,聚焦于化合物毒性机制的多模态表征。该数据集整合了6160个样本的SMILES序列与视觉化分子结构,通过问答形式深化对分子毒性机理的理解,为高通量毒性预测模型提供了关键训练基础,显著推动了环境毒理与药物安全评估领域的数据驱动研究范式转型。
当前挑战
该数据集致力于解决分子毒性分类任务中多模态数据融合的复杂性挑战,具体体现为SMILES序列的语法歧义性与二维分子图像的空间结构表征对齐难题。在构建过程中,研究人员需克服三维分子构象到二维平面投影的信息损失,同时确保视觉特征与符号表征在毒性机制解释中的语义一致性。此外,样本采样方法的标准化与不同毒性端点间数据平衡性亦构成重要技术瓶颈。
常用场景
经典使用场景
在计算毒理学领域,Tox21-V-Train数据集凭借其结合分子结构与问答对的独特设计,成为评估化合物毒性预测模型的基准工具。研究者常利用该数据集训练多模态深度学习模型,通过SMILES序列与分子图像的双重输入,探索分子特征与毒性终点之间的复杂关联,尤其在药物安全性筛选中展现出卓越的适应性。
解决学术问题
该数据集有效解决了传统毒理学研究中高成本实验与低通量筛选的瓶颈,通过标准化分子表征与毒性标签的关联,推动了计算机辅助毒性预测方法的发展。其多模态架构为解释黑箱模型提供了新视角,显著提升了分子性质预测的可解释性研究水平,加速了绿色化学与替代毒理学范式的演进。
实际应用
在制药工业与环境保护领域,该数据集支撑的预测模型已应用于药物早期毒性筛查与化学品风险评估。通过快速预判数千种化合物的毒性特征,大幅降低了动物实验依赖与研发成本,同时为监管机构制定化学品安全标准提供了数据驱动的决策支持。
数据集最近研究
最新研究方向
在计算毒理学领域,Tox21-V-Train数据集正推动多模态分子表征的前沿探索。该数据集整合了SMILES序列与分子结构图像,为深度学习模型提供了跨模态学习基础,促进了药物安全性预测的精准化发展。当前研究聚焦于图神经网络与视觉Transformer的融合架构,旨在解析分子空间构象与毒性间的复杂关联。随着绿色化学理念的普及,此类数据资源正加速低毒性化合物筛选进程,并在环境风险评估中展现重要价值。
以上内容由遇见数据集搜集并总结生成


