korean-court-judgments
收藏Hugging Face2025-07-16 更新2025-07-17 收录
下载链接:
https://huggingface.co/datasets/ducut91/korean-court-judgments
下载链接
链接失效反馈官方服务:
资源简介:
韩国法院判决数据集是一个包含163,546个韩国法院判决的全面数据集,旨在为法律自然语言处理、文档摘要和生成式人工智能的研究与开发提供支持。数据集中的每个记录都包含案件名称、法院名称、判决类型、相关法律和判决全文等详细信息。针对缺少' 판시사항'和' 판결요지'的记录,数据集通过GPT-4o-mini自动生成了法律摘要。
创建时间:
2025-07-10
原始信息汇总
Korean Court Judgments 数据集概述
📌 数据集基本信息
- 许可证: mit
- 任务类别: text2text-generation
- 语言: 韩语 (ko)
- 标签: legal
- 规模: 100K<n<1M
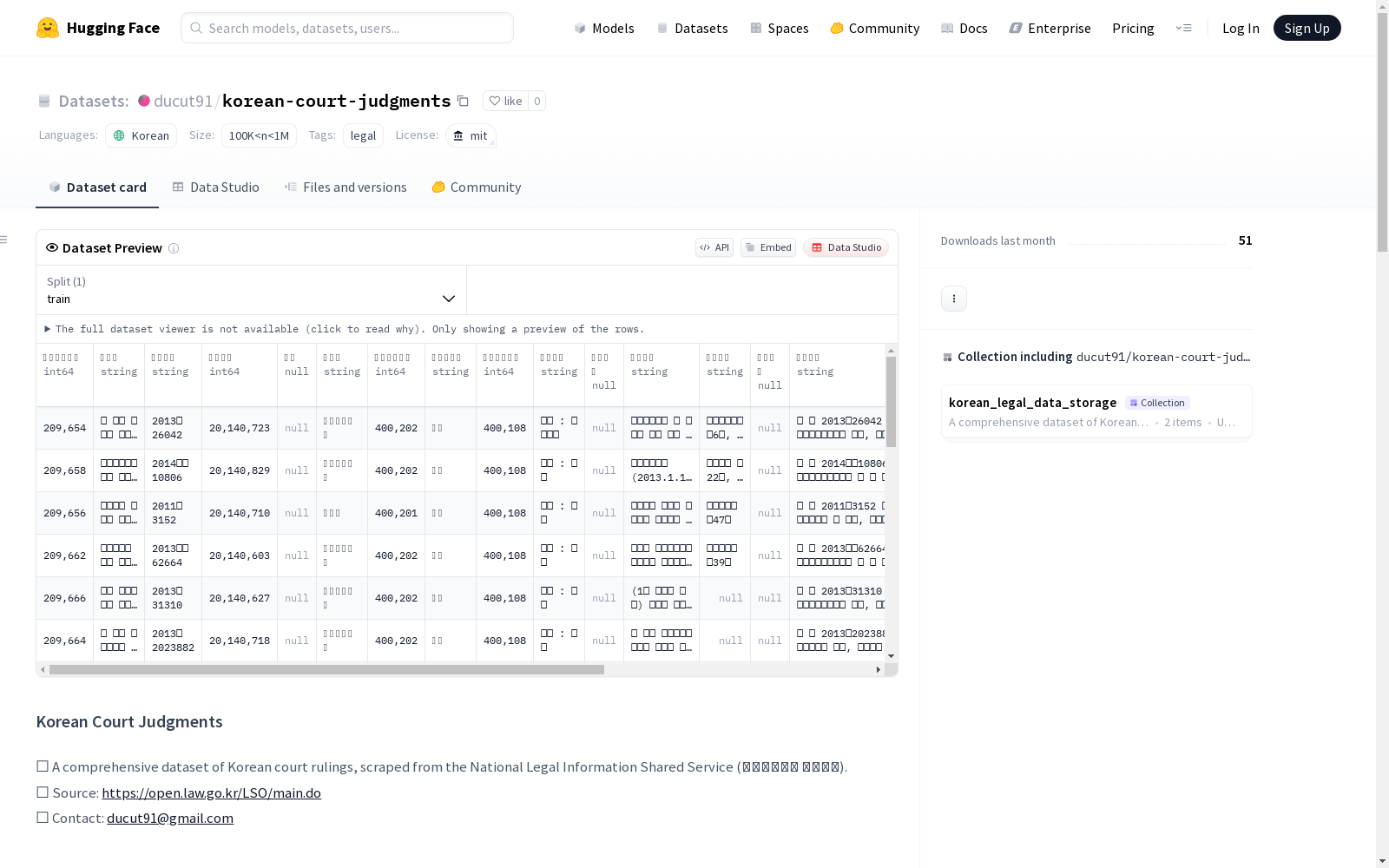
📚 数据集内容
- 来源: 韩国国家法律信息共享服务 (국가법령정보 공동활용)
- 记录数: 163,546 条韩国法院判决
- 内容类型: 真实法院裁决的元数据和内容
- 数据字段:
- 案件名称、法院名称、判决类型、相关法律、裁决全文等
- AI增强: 当
판시사항(Issues) 和판결요지(Summary) 缺失时,使用 GPT-4o-mini 基于裁决全文 (판례내용) 自动生成法律摘要
🧾 数据字段详情
| 字段名 | 描述 |
|---|---|
| 판례일련번호 | 判决的唯一标识符 |
| 사건명 | 案件名称/标题 |
| 사건번호 | 法院分配的官方案件编号 |
| 선고일자 | 判决日期 (YYYYMMDD 格式) |
| 선고 | 判决类型 (如 dismissed, accepted) |
| 법원명 | 发布判决的法院名称 |
| 법원종류코드 | 法院类型的数字代码 (最高法院: 400201, 下级法院: 400202) |
| 사건종류명 | 案件类型/类别 (如 Tax(세무), Civil(민사), Criminal(형사) 等) |
| 사건종류코드 | 与案件类型对应的数字代码 |
| 판결유형 | 判决类型 |
| 판시사항 | 法院考虑的法律问题或原则 |
| 판결요지 | 判决摘要 (人工编写或AI生成) |
| 참조조문 | 引用的法律/法规 |
| 참조판례 | 引用的判例 |
| 판례내용 | 判决的全文 |
| 출처 | HTML 或 XML |
| 판례상세링크 | 原始完整判决的链接 |
🛠️ 预处理细节
- 数据来源: 韩国国家法律信息共享服务
- AI增强处理: 当
판시사항和판결요지均为空时,使用 GPT-4o-mini 基于판례내용生成摘要并填充到판결요지字段
✅ 使用建议
- 文本摘要: 训练模型以总结法律文件
- 文本生成: 创建法律助手或问答系统
- 法律NLP研究: 分析趋势、法律概念和判例引用网络
- 结构化数据提取: 构建信息检索或法律特定LLMs的数据集
搜集汇总
数据集介绍
构建方式
该数据集源自韩国国家法律信息共享服务平台,通过系统化爬取技术整合了163,546份真实法院判决文书。在数据构建过程中,针对缺失关键字段(판시사항与판결요지)的案例,采用GPT-4o-mini模型基于判决全文自动生成法律摘要,实现了原始数据的智能化增强。所有记录均包含案件编号、法院类型、判决日期等结构化元数据,以及完整的判决文书内容,形成兼具原始性与增强性的法律文本资源库。
使用方法
该数据集主要服务于法律自然语言处理研究领域,研究者可通过HuggingFace平台直接加载预处理后的标准格式数据。针对文本摘要任务,建议以판례내용作为输入文本、판결요지作为目标文本来构建训练对;在法律问答系统开发中,可结合판시사항与참조조文字段构建知识图谱。对于生成式AI应用,推荐采用text2text-generation框架,利用完整的判决文书内容训练专业化法律语言模型。数据集中提供的判例详情链接便于溯源验证,建议关键应用场景中进行人工复核。
背景与挑战
背景概述
Korean Court Judgments数据集是由韩国国家法务信息共享服务平台(국가법령정보 공동활용)提供的法律判决文书集合,旨在为法律自然语言处理(NLP)、文档摘要生成以及生成式人工智能研究提供结构化数据支持。该数据集收录了163,546份韩国法院判决,涵盖民事、刑事、行政、税务、家庭及专利等多种案件类型,每份判决均包含案件名称、法院信息、判决日期、法律条文引用及全文内容等关键元数据。数据集通过自动化技术对缺失的判决摘要进行补全,采用GPT-4o-mini模型生成法律摘要,显著提升了数据的完整性与可用性。该资源的发布为法律文本挖掘、司法趋势分析及智能法律辅助系统开发奠定了重要基础。
当前挑战
该数据集面临的核心挑战体现在领域问题与构建过程两个维度。在领域问题层面,法律文本固有的专业性与复杂性对自然语言处理技术提出极高要求,包括专业术语理解、法律逻辑推理及跨条文关联分析等;同时,判决文书的非结构化特征与领域特有的表述方式(如判例引用格式)增加了信息抽取的难度。在构建过程中,原始数据的异构性(如部分判决缺失关键字段‘판시사항’和‘판결요지’)迫使研究者依赖生成式模型进行补全,可能引入语义偏差;此外,韩国司法体系特有的法院分类编码(如宪法法院未纳入)及案件类型细分标准,需设计定制化处理流程以确保数据一致性。
常用场景
经典使用场景
在司法智能化和法律自然语言处理研究中,Korean Court Judgments数据集为学者提供了丰富的韩国法院判例文本。该数据集最经典的使用场景在于训练法律文本摘要生成模型,通过分析判例内容、判示事项和判决要旨等结构化字段,模型能够学习从冗长的法律文书中提取关键法律原则和判决逻辑。这种应用显著提升了法律从业者检索和分析判例的效率。
解决学术问题
该数据集有效解决了法律人工智能领域的关键问题:法律文本的语义理解和结构化信息抽取。通过提供标注完整的判例内容和自动生成的判决摘要,研究者能够开发更精准的法律概念识别算法,分析不同案件类型中的法律论证模式。这对于构建法律知识图谱、研究司法裁判规律具有重要价值,为计算法学提供了可靠的数据基础。
实际应用
在法律科技实践中,该数据集支撑了智能法律咨询系统的开发。基于判例内容和判决要旨的对应关系,系统能够自动回答用户法律疑问,预测案件判决结果。律师事务所利用该数据集训练的分类模型,可快速筛选相关判例;法院系统则借助其构建的检索平台,实现裁判文书的智能推荐,提升司法工作效率。
数据集最近研究
最新研究方向
在自然语言处理与法律智能交叉领域,Korean Court Judgments数据集正推动多项前沿研究。该数据集以其16万条结构化韩国法院判决为支撑,成为法律文本摘要生成任务的重要基准,研究者利用其丰富的判例内容和自动生成的摘要标签,探索基于Transformer架构的领域自适应预训练方法。近期研究热点聚焦于构建韩语法律专用的大型语言模型,通过判例内容与参考法条的关联分析,提升模型对东亚法系条文解释的推理能力。同时,该数据集支撑的司法趋势预测研究引发学界关注,基于案件类型与判决结果的时序分析,可揭示韩国司法实践中的潜在模式。在法律科技应用层面,该资源为开发韩语法律问答系统和判决书生成工具提供了关键数据支持,尤其在处理税务、专利等专业领域时展现出独特价值。
以上内容由遇见数据集搜集并总结生成


