ds1000_pnyx
收藏Hugging Face2026-03-10 更新2026-03-11 收录
下载链接:
https://huggingface.co/datasets/PNYX/ds1000_pnyx
下载链接
链接失效反馈官方服务:
资源简介:
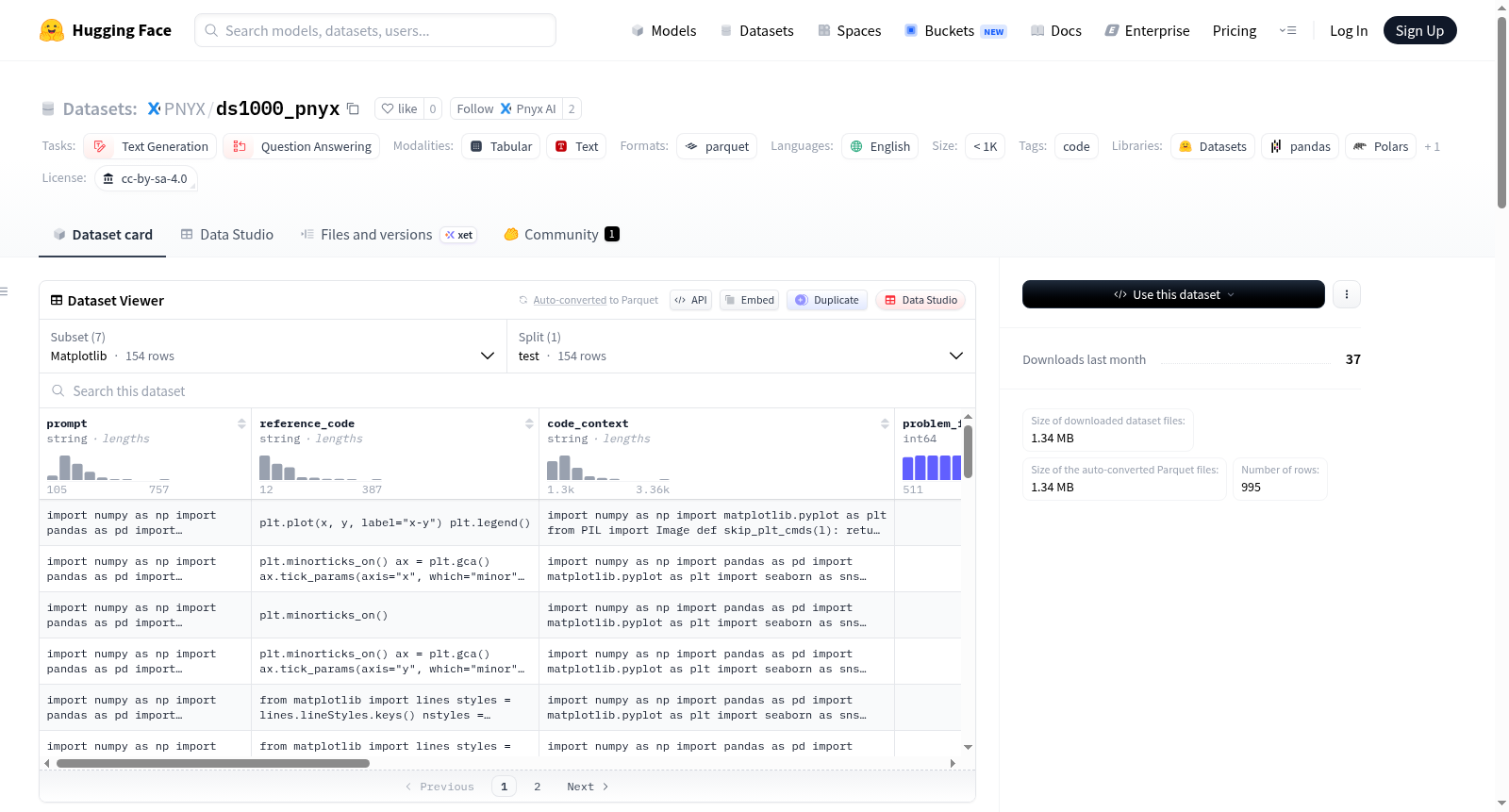
PNYX-ds1000 是基于 DS-1000 数据集的分割和测试版本,旨在与 `hf_evaluate` 的 `code_eval` 包兼容。该数据集包含原始字段及新增字段:`user_chat_prompt`(聊天式问题提示)、`test_code`(重写为 `hf_evaluate` 兼容格式的代码上下文)和 `solution_function`(解决方案函数)。数据集涵盖多个配置(Pandas、Numpy、Matplotlib、Tensorflow、Scipy、Sklearn、Pytorch),每个配置包含测试分割的 parquet 文件。执行依赖包括多个 Python 包(如 pandas、numpy、matplotlib 等)。部分原始 DS-1000 样本未包含在本数据集中,原因包括测试失败、非标准测试方法或需要外部数据。此外,四个原属 Numpy 的样本被重新分配到 Pytorch 或 Tensorflow。数据集适用于代码生成和问答任务,需遵守额外的使用条款以防止数据泄露。
创建时间:
2026-03-03
原始信息汇总
PNYX - DS-1000 数据集概述
数据集基本信息
- 数据集名称:PNYX-ds1000
- 托管地址:https://huggingface.co/datasets/PNYX/ds1000_pnyx
- 许可证:cc-by-sa-4.0
- 主要任务类别:文本生成、问答
- 语言:英语
- 标签:代码
- 数据规模:100<n<1K
数据来源与性质
- 本数据集是 DS-1000 数据集的拆分和测试版本,基于重新格式化的版本 claudios/ds1000。
- 设计目标是与
hf_evaluate的code_eval包兼容。 - 代码已修改,以适应所用 Python 包(如 numpy、scipy 等)的较新版本。
数据结构与配置
数据集包含以下配置,每个配置对应一个测试分割的 parquet 文件:
- Pandas
- Numpy
- Matplotlib
- Tensorflow
- Scipy
- Sklearn
- Pytorch
数据字段说明
数据集包含所有原始字段,并新增以下字段:
- user_chat_prompt:聊天式问题提示,从
prompt改编而来,包含将解决方案代码包装成函数的指令。 - test_code:以
code_context重写,格式支持使用hf_evaluate代码评估器。 - solution_function:解决方案的兼容格式,适用于
hf_evaluate代码评估器,源自reference_code。
执行依赖环境
运行测试所需的依赖包版本如下:
- pandas==2.3.3
- numpy==2.2.6
- matplotlib==3.10.8
- scipy==1.15.3
- pooch==1.9.0
- seaborn==0.13.2
- PyYAML==6.0.3
- scikit-learn==1.7.2
- torch==2.10.0
- tensorflow==2.20.0
- xgboost==1.6.2
- statsmodels==0.14.6
- gensim==4.4.0
- nltk==3.9.3
缺失样本与变更说明
原始 DS-1000 中的部分样本未包含在本数据集中:
- 测试失败(可能是错误的解决方案或与当前测试方法不兼容):
- 520
- 925
- 非标准测试方法(与当前方法不兼容):
- 701
- 需要外部数据(需要下载或硬编码的 csv 文件):
- 819
- 908
- 909
- 910
此外,四个原属于 Numpy 库的样本被移至其他库:
- 从
Numpy移至Pytorch:- 377
- 378
- 从
Numpy移至Tensorflow:- 379
- 380
使用条款
访问者需同意不在线以纯文本或图像形式泄露此数据集的示例,以降低泄露到基础模型训练语料库的风险。
搜集汇总
数据集介绍
构建方式
在代码生成与问答任务的交叉领域,ds1000_pnyx数据集基于原始DS-1000数据集进行了重构与优化。该版本从claudios/ds1000中提取元数据作为列,并针对hf_evaluate的code_eval包进行了格式适配。构建过程中,对代码上下文进行了重写,生成了兼容的测试代码与解决方案函数,同时更新了依赖库版本以确保与现代Python环境的兼容性。部分样本因测试失败、方法非标准或依赖外部数据而被排除,另有少量样本根据其导入与提示内容被重新归类至更合适的库类别。
特点
该数据集涵盖了Pandas、Numpy、Matplotlib、Tensorflow、Scipy、Sklearn和Pytorch七大主流Python库的代码生成问题,每个配置均包含测试分割。其核心特点在于提供了聊天式用户提示,将问题描述转化为包含函数封装指令的对话格式,并专门设计了可直接用于hf_evaluate评估框架的测试代码与解决方案函数。数据集经过精心筛选与修正,移除了不兼容或存在缺陷的样本,确保了评估的准确性与一致性,为代码生成模型的性能评测提供了标准化、可复现的基准环境。
使用方法
使用该数据集时,需通过Hugging Face的load_dataset函数加载特定库的配置,并配合hf_evaluate的code_eval度量工具进行评估。用户需预先设置环境变量以允许代码执行,并安装列出的精确依赖版本,包括pandas、numpy、matplotlib等库。评估过程通过比较模型生成的预测代码与数据集提供的测试代码,计算pass@k等指标来量化模型性能。数据集的聊天式提示可直接用于指导模型生成封装为函数的代码,而其标准化的测试格式则简化了评估流程,支持对代码生成能力进行高效、可靠的自动化测试。
背景与挑战
背景概述
在人工智能与软件工程交叉领域,代码生成与评估已成为推动智能编程辅助工具发展的核心议题。DS-1000数据集作为该领域的重要基准,由XLang AI实验室于2022年创建,旨在系统评估大型语言模型在多种流行Python库环境下的代码生成能力。该数据集聚焦于解决现实编程任务,覆盖Pandas、NumPy、Matplotlib等七个关键库,通过精心设计的编程问题考察模型对复杂API调用与逻辑推理的掌握程度。其构建不仅促进了代码生成模型的标准化评测,也为后续研究提供了高质量的评估框架,显著提升了领域内模型性能的可比性与可靠性。
当前挑战
DS-1000数据集所针对的代码生成任务面临多重挑战:其一,模型需准确理解自然语言描述与复杂库函数语义之间的映射关系,并生成语法正确、功能完备的代码;其二,评估过程需确保代码执行环境的一致性,避免因依赖版本或外部数据差异导致结果偏差。在数据集构建层面,挑战体现在样本筛选与格式标准化:部分原始样本因测试失败、方法非标准或依赖外部数据而被排除,需重新调整样本归属以确保库分类的准确性。此外,为兼容现代化评估工具如`hf_evaluate`,需重构代码提示与测试格式,这对数据集的可用性与评估效率提出了更高要求。
常用场景
实际应用
在实际应用中,ds1000_pnyx被广泛用于开发和优化代码生成系统,如智能代码补全、编程教育辅助工具以及自动化软件测试平台。通过该数据集的评估,工程师能够精准调整模型,提升其在处理数据科学、机器学习等具体任务时的代码生成质量与效率。
衍生相关工作
围绕该数据集,学术界衍生了一系列经典研究工作,包括基于pass@k指标的模型性能比较、跨库代码生成的迁移学习策略,以及针对特定编程库的微调方法。这些工作不仅深化了对代码生成模型能力的理解,还为构建更鲁棒、通用的编程辅助系统奠定了理论基础。
以上内容由遇见数据集搜集并总结生成


