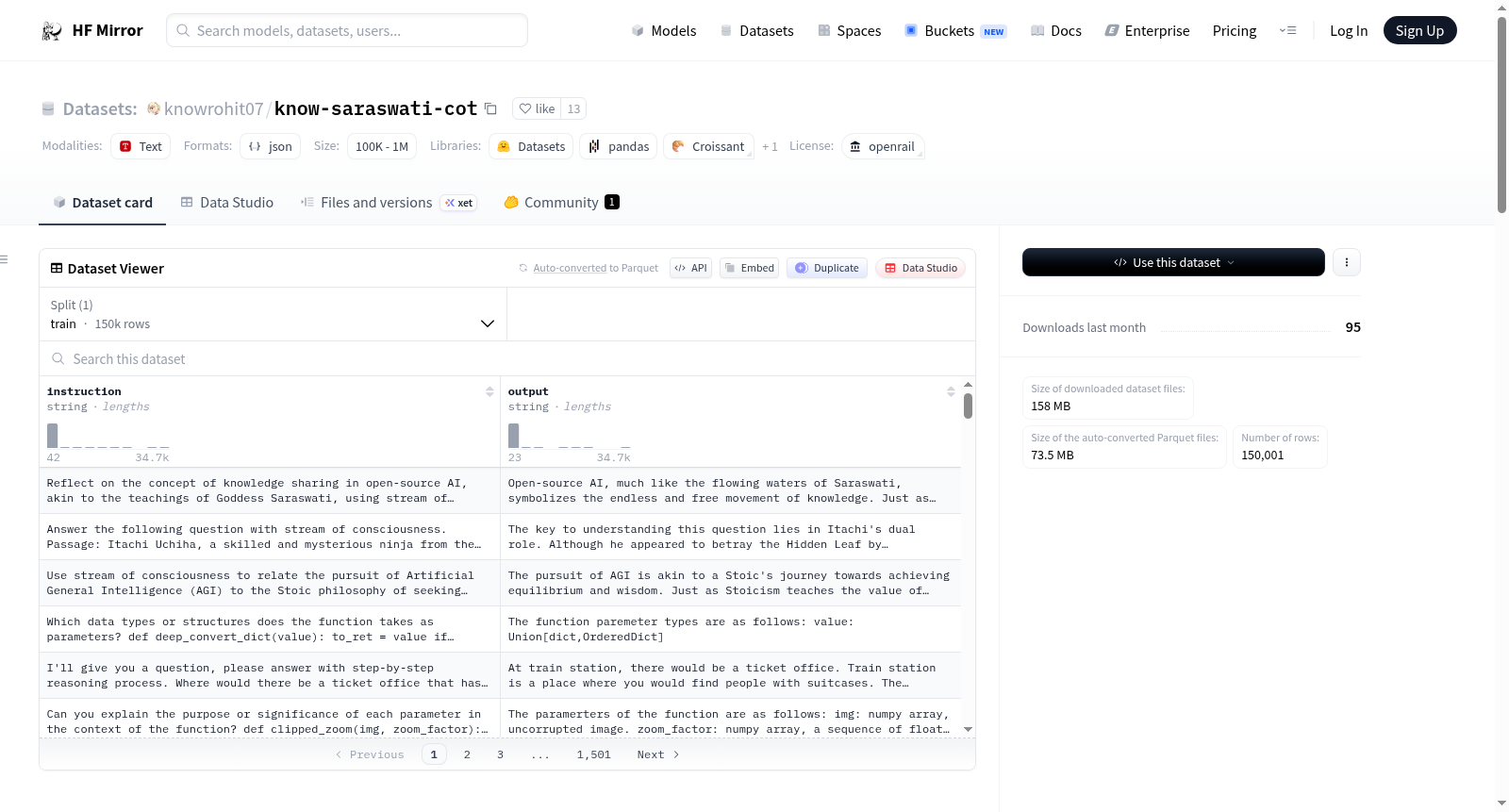
knowrohit07/know-saraswati-cot
收藏Hugging Face2023-11-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/knowrohit07/know-saraswati-cot
下载链接
链接失效反馈官方服务:
资源简介:
know-saraswati-cot数据集是一个精心策划的示例集合,旨在训练和评估大型语言模型(LLMs)在意识流(SoC)、思维链(CoT)和逻辑推理方面的能力。该数据集以印度教知识女神Saraswati命名,体现了开源知识共享的精神。数据集的结构包括指令和输出字段,旨在模拟人类推理过程。每个示例都经过精心设计,以捕捉人类逻辑、情感和认知的本质,引导AI生成相关且深入的响应。数据集还包含30,000个代码推理示例和各种其他深度推理场景,旨在赋予LLMs深刻的理解、推理和决策能力。
The know-saraswati-cot dataset is a carefully curated collection of examples designed to train and evaluate Large Language Models (LLMs) on their capabilities in Stream of Consciousness (SoC), Chain of Thought (CoT), and logical reasoning. Named after the Hindu goddess of knowledge, Saraswati, this dataset embodies the spirit of open-source knowledge sharing. The structure of the dataset includes instruction and output fields, which are intended to simulate the human reasoning process. Each example is meticulously designed to capture the essence of human logic, emotion, and cognition, and to guide AI models in generating relevant and in-depth responses. The dataset also contains 30,000 code reasoning examples and various other in-depth reasoning scenarios, aiming to equip LLMs with profound understanding, reasoning, and decision-making capabilities.
提供机构:
knowrohit07
原始信息汇总
概述
know-saraswati-cot数据集是一个精心策划的示例集合,旨在训练和评估大型语言模型(LLMs)在意识流(SoC)、思维链(CoT)和逻辑推理方面的能力。该数据集以知识、智慧和学习的印度教女神Saraswati命名,体现了开源知识共享的精神。它是对民主化知识的颂歌,使其像神话中的Saraswati河一样易于获取。
该数据集包含额外的30,000个代码推理示例和各种其他深度推理场景,旨在赋予LLMs深刻的理解、推理和决策能力。
数据集结构
每个know-saraswati-cot数据集条目包含一个指令和一个输出字段。指令提供一个需要深度思考的场景或问题,邀请模型进行逐步推理过程。输出则捕捉一个符合逻辑演绎和意识流思维原则的合理响应。
- 简洁推理:大多数示例在500个令牌内简洁地制定,促进快速和高效的思维链(CoT)。这模拟了类似于人类认知的简洁而深刻的推理过程。
- 多轮交互:一些条目设计为多轮交互,允许模型进行更深入和动态的对话。这模拟了现实世界对话,其中对话建立在前面的交流之上。
- 扩展讨论:数据集的一个子集包含长达2000个令牌的场景,用于全面的推理任务。这些场景旨在模拟一个有知觉的个体如何对复杂的逻辑谜题进行深思熟虑的响应,而不是由不太复杂的模型生成的通常表面和离题的响应。
- 每个示例都旨在捕捉人类逻辑、情感和认知的本质,引导AI响应远离不成熟和无关紧要的内容,朝着真正解决查询的关联性和深度发展。
灵感
受使知识对所有人免费和可访问的愿景启发,该数据集使用GPT-4合成。特别感谢我的兄弟,他的愿景——一个知识是公共财富的节俭启蒙世界——是这一努力的基础。
用例
know-saraswati-cot数据集可用于:
- 通过提供丰富的、细微的逻辑推理示例,该数据集非常适合开发能够模仿人类思维过程深度的模型。
- 研究人员可以利用该数据集来研究AI模型如何不仅得出结论,还能阐述其决策背后的推理,使AI的工作更加透明。
- know-saraswati-cot可以促进与哲学、文学和工程学交叉的AI发展,鼓励AI能力的全面和多维增长。
- 增加乐趣。
搜集汇总
数据集介绍
构建方式
在人工智能领域,数据集的构建往往决定了模型的学习边界与认知深度。know-saraswati-cot数据集通过精心设计的流程,利用GPT-4生成并筛选了涵盖意识流、思维链及逻辑推理的多样化示例。其构建过程注重模拟人类认知的层次性,每个条目均包含指令与输出字段,指令部分设定需深度思考的场景或问题,输出部分则呈现符合逻辑演绎与连贯思维过程的回应。数据集特别融入了约30,000个代码推理实例及其他深度推理情境,旨在通过结构化编排,使语言模型能够内化复杂推理模式,从而超越表层语言生成,触及更深层的理解与决策机制。
使用方法
在应用层面,know-saraswati-cot数据集为语言模型的训练与评估提供了丰富资源。研究者可将其用于开发能够模仿人类思维深度的模型,通过输入指令字段,引导模型进行逐步推理,并对比输出与数据集中提供的标准回应,以优化模型的逻辑连贯性与解释能力。该数据集亦适用于可解释人工智能的研究,帮助模型不仅得出结论,还能清晰阐述决策背后的推理过程,从而提升AI系统的透明度。此外,它鼓励跨学科探索,如融合哲学、文学与工程学视角,促进人工智能能力的多维发展,同时为开发者提供了探索复杂推理场景的实践平台。
背景与挑战
背景概述
在人工智能领域,大型语言模型(LLMs)的推理能力一直是核心研究议题。knowrohit07/know-saraswati-cot数据集应运而生,由开源社区贡献,旨在通过模拟人类意识流(SoC)和思维链(CoT)过程,提升模型在逻辑推理与深度思考方面的表现。该数据集以印度智慧女神萨拉斯瓦蒂命名,象征着对开放知识共享的追求,其构建融合了GPT-4生成的多样化示例,涵盖代码推理与复杂场景分析,致力于推动模型从表层模式匹配向深层理解演进,为AI的透明化与哲学化发展提供了关键资源。
当前挑战
该数据集致力于解决自然语言处理中模型逻辑推理与解释性不足的挑战,要求模型不仅生成答案,还需展现连贯的思维过程,这涉及对抽象概念和多重语境的理解。在构建过程中,挑战在于如何精准模拟人类推理的简洁性与深度,平衡示例的多样性与一致性,同时避免引入模型固有的偏见或浅层模式。此外,确保多轮交互与扩展讨论的自然流畅性,以及维持数据质量以促进模型泛化能力,均是实现其目标的关键难点。
常用场景
经典使用场景
在人工智能领域,大型语言模型的推理能力训练一直是核心挑战之一。know-saraswati-cot数据集通过精心设计的链式思维与意识流示例,为模型提供了模拟人类深度思考过程的范本。该数据集广泛应用于提升模型在复杂逻辑推理、代码生成及多轮对话中的表现,使模型能够逐步推导结论,而非仅依赖表层模式匹配,从而在学术基准测试和模型微调中展现出卓越的效能。
解决学术问题
该数据集致力于解决人工智能研究中模型缺乏透明推理路径的难题。通过提供结构化的逐步推理示例,它帮助研究者探索如何使语言模型不仅输出结果,还能清晰展示其决策逻辑,从而增强模型的可解释性。这在推动AI对齐、减少幻觉现象以及构建可信赖的智能系统方面具有深远意义,为学术社区提供了评估和提升模型推理质量的重要工具。
实际应用
在实际应用中,know-saraswati-cot数据集能够赋能智能助手、教育工具及专业咨询系统。例如,在代码辅助开发中,模型可依据数据集的推理示例生成逻辑严密的代码解释;在哲学或文学分析场景下,它支持模型进行多层次、连贯的论述。这些应用不仅提升了人机交互的深度,也促进了AI在跨学科领域中的融合与创新。
数据集最近研究
最新研究方向
在人工智能领域,know-saraswati-cot数据集以其聚焦于意识流与思维链推理的特性,正推动大语言模型向深度逻辑理解与透明决策机制的前沿探索。该数据集通过精心设计的代码推理与多轮交互场景,模拟人类认知的简洁性与动态性,助力模型超越表层响应,实现类人化的复杂问题解决。当前研究热点集中于利用此类数据集提升AI的可解释性,使其在哲学、工程等多学科交叉中展现更丰富的推理维度,为通用人工智能的发展奠定基础,体现了知识民主化与开放科学的精神内核。
以上内容由遇见数据集搜集并总结生成


