CalCEN
收藏Hugging Face2025-01-30 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/maomlab/CalCEN
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为Candida albicans共表达网络(CalCEN),旨在通过共表达分析预测基因功能。数据集包含多个配置文件,涵盖了基因表达数据、共表达网络、序列相似性网络等。这些数据来源于公开的转录组数据,用于重建已知的蛋白质网络、预测基因功能,并揭示共表达的影响因素。数据集还包括从NCBI SRA收集的RNA-seq运行数据,以及从Candida Genome Database收集的染色体特征和GO注释。
创建时间:
2025-01-30
原始信息汇总
数据集概述
数据集名称
Candida albicans Co-Expression Network (CalCEN)
数据集描述
CalCEN 是一个针对 Candida albicans 的共表达网络,用于预测基因功能,并能够洞察影响共表达的原理。
数据集构成
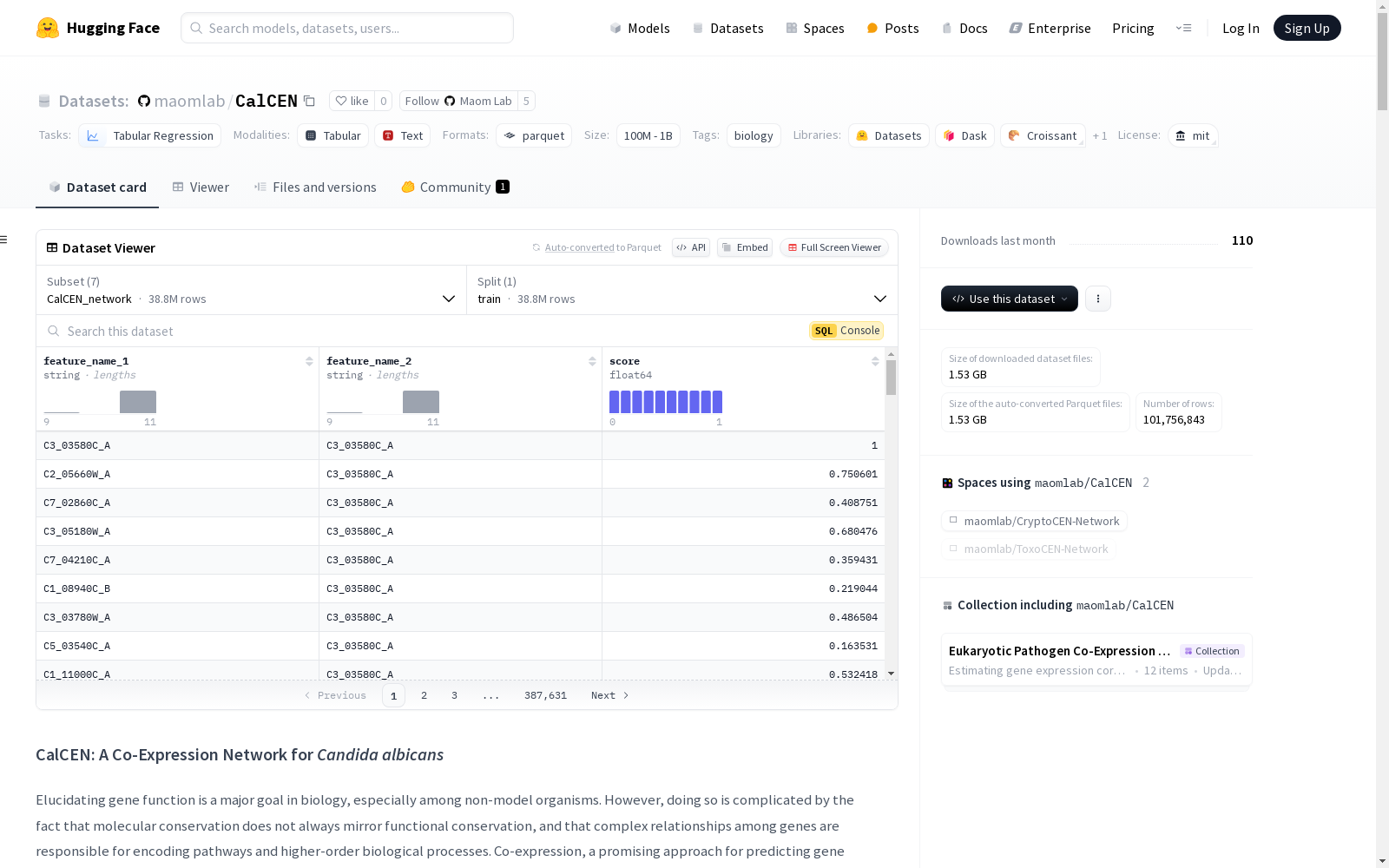
- CalCEN_network: 共表达网络数据
- blastp_network: 序列相似性网络数据
- sac_gene_network: 基因遗传关联网络数据
- sac_phys_network: 蛋白质-蛋白质相互作用网络数据
- yeast_net_network: YeastNet网络数据
数据集详情
- CalCEN_network
- 训练集大小:1,472,498,080 字节
- 训练集样本数:38,763,076
- 下载大小:633,855,931 字节
- 数据集大小:1,472,498,080 字节
- blastp_network
- 训练集大小:4,260,374 字节
- 训练集样本数:112,129
- 下载大小:1,122,972 字节
- 数据集大小:4,260,374 字节
- sac_gene_network
- 训练集大小:1,472,498,080 字节
- 训练集样本数:38,763,076
- 下载大小:452,519,443 字节
- 数据集大小:1,472,498,080 字节
- sac_phys_network
- 训练集大小:557,509,168 字节
- 训练集样本数:14,671,296
- 下载大小:105,496,144 字节
- 数据集大小:557,509,168 字节
- yeast_net_network
- 训练集大小:16,180,096 字节
- 训练集样本数:425,792
- 下载大小:6,316,147 字节
- 数据集大小:16,180,096 字节
许可
MIT 许可
搜集汇总
数据集介绍
构建方式
CalCEN数据集的构建是通过整合大量公开的转录组数据,利用基因共表达的网络分析方法,构建了一个针对白色念珠菌的共表达网络。该网络不仅反映了已知的蛋白质网络,还能预测基因功能,并揭示了影响共表达的原理。
特点
CalCEN数据集的特点在于它是一个大规模的共表达网络,包含了大量的基因对关联信息,能够用于预测基因功能,帮助研究人员深入了解基因间的相互作用和生物学过程。此外,它还提供了多种类型的网络数据,包括序列相似性网络、遗传关联网络和物理蛋白质相互作用网络等。
使用方法
使用CalCEN数据集时,研究人员可以根据自己的研究需求选择不同的网络配置文件。数据集提供了多种文件格式,包括基因特征、基因注释、表达水平等,方便研究人员进行数据整合和分析。此外,数据集还支持10折交叉验证,提供了均值和标准差的评估指标,帮助研究人员评估模型的性能。
背景与挑战
背景概述
CalCEN(Candida albicans Co-Expression Network)是一个针对真菌病原体Candida albicans的共表达网络,旨在通过分析大量公开的转录组数据,揭示基因功能并预测基因表达。该数据集的创建始于对Candida albicans基因功能的深入研究,由TR O'Meara、MJ O'Meara和M Sphere于2020年提出。CalCEN的构建不仅复现了已知的蛋白质网络,还预测了基因功能,为理解共表达原则提供了新的见解。该数据集对当前未充分注释的基因功能鉴定具有显著影响。
当前挑战
在构建CalCEN数据集的过程中,研究人员面临着多个挑战。首先,由于分子保守性并不总是反映功能保守性,且复杂的基因间关系负责编码生物途径和更高阶的生物过程,因此预测基因功能具有难度。其次,构建过程中需要整合来自不同来源的大量数据,包括基因注释、表达谱和蛋白质-蛋白质相互作用信息,这些数据的整合和处理是一个挑战。此外,确定共表达网络中的显著关联阈值,以及如何在众多网络中保持平衡,确保既不过度拟合也不遗漏重要的基因关联,都是构建过程中的关键挑战。
常用场景
经典使用场景
CalCEN数据集经典使用场景在于,通过其提供的基因共表达网络,研究人员能够预测基因功能,识别基因间的关联性,进而洞察复杂的生物学过程。这一场景在研究非模式生物,特别是在探索人类病原真菌Candida albicans的功能基因组学时尤为重要。
实际应用
在实际应用中,CalCEN数据集可用于指导实验室研究,帮助科学家在Candida albicans这一重要的人类病原体中识别潜在的治疗靶点,以及在药物发现和疾病机制研究中提供关键信息。
衍生相关工作
CalCEN数据集衍生出的相关工作包括了对基因功能的预测、基因调控网络的分析以及病原体与宿主相互作用的探究,这些都进一步扩展了CalCEN数据集在生物学研究中的应用范围和影响力。
以上内容由遇见数据集搜集并总结生成


