Nhoodie/hgt-bootstrap-v1-synthetic
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/Nhoodie/hgt-bootstrap-v1-synthetic
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
tags:
- dna
- mutation
- synthetic
- icedc
- bootstrap
size_categories:
- 1K<n<10K
---
---
## ⚠️ IMPORTANT WARNING — Synthetic Data Quality
This synthetic dataset was generated using the ICI-DC (Interleaved Codon Insertion) method from a fine-tuned model that had underfit during training. The "mutations" in this dataset are predominantly random nucleotide fills (Ti/Tv ratio ~0.50, entropy ~3.51/3.58) that do NOT reflect biological HGT mutation patterns (real Ti/Tv ~0.77). Models trained on this data showed degraded mutation discrimination compared to the unmodified base model.
**This dataset is preserved for historical and reproducibility purposes only.**
---
# HGT Bootstrap V1 Synthetic Pairs
8,112 synthetic mutation pairs generated via ICI-DC (Interleaved Codon Insertion — Double Consensus) using the SAD coeff1.5 checkpoint as Model A and HyenaDNA-tiny-1k as Model B.
## Generation Details
- **Model A**: Nhoodie/omni-dna-sad-mutation (SAD coeff1.5 checkpoint)
- **Model B**: LongSafari/hyenadna-tiny-1k-seqlen-hf (Legacy DC)
- **Source sequences**: 1,014 unique sequences from 8 taxonomic domains
- **Gap intervals**: [3, 4, 5, 6] (codon distance between gaps)
- **Seeds**: [42, 137]
- **Passes**: 4 × 2 = 8 files
- **Legacy DC consensus rate**: 2.03%
## Properties
- Mean mutation rate: ~23%
- Mean Levenshtein distance: ~89.5 nt
- 4,998 source sequences from raw_sequences.fasta
## Files
| File | Gap | Seed | Pairs |
|------|-----|------|-------|
| synthetic_gap3_seed42.jsonl | 3 | 42 | 1,014 |
| synthetic_gap3_seed137.jsonl | 3 | 137 | 1,014 |
| synthetic_gap4_seed42.jsonl | 4 | 42 | 1,014 |
| synthetic_gap4_seed137.jsonl | 4 | 137 | 1,014 |
| synthetic_gap5_seed42.jsonl | 5 | 42 | 1,014 |
| synthetic_gap5_seed137.jsonl | 5 | 137 | 1,014 |
| synthetic_gap6_seed42.jsonl | 6 | 42 | 1,014 |
| synthetic_gap6_seed137.jsonl | 6 | 137 | 1,014 |
## Format
Each line is a JSON object with parent/child sequences, quality metadata, and generation parameters.
## Related Datasets
- [Nhoodie/hgt-real-mutation-pairs](https://huggingface.co/datasets/Nhoodie/hgt-real-mutation-pairs) — Real mutation pairs (train + test)
- [Nhoodie/hgt-bootstrap-v2-synthetic](https://huggingface.co/datasets/Nhoodie/hgt-bootstrap-v2-synthetic) — 256K synthetic pairs (next iteration)
提供机构:
Nhoodie
搜集汇总
数据集介绍
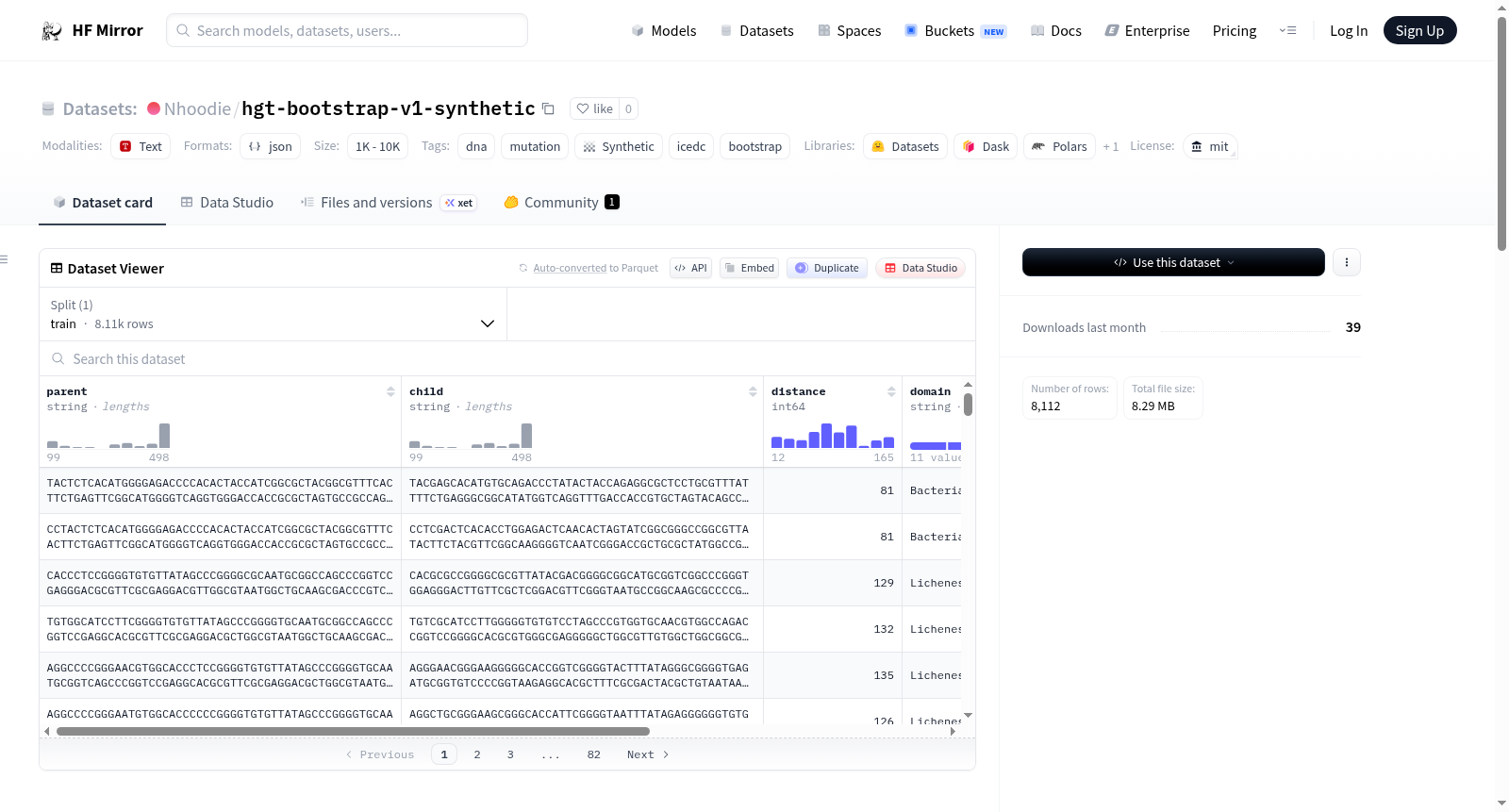
构建方式
在基因组学与生物信息学领域,合成数据的生成对于模型训练具有重要价值。本数据集采用ICI-DC方法构建,即交错密码子插入双共识策略,利用SAD coeff1.5检查点作为模型A与HyenaDNA-tiny-1k作为模型B,从八个分类域的1014条独特源序列中生成突变对。通过设置不同密码子间隔距离与随机种子,最终产生了8112对合成序列,每对均包含详细的生成参数与质量元数据。
特点
该数据集的核心特征在于其合成性质,突变主要由随机核苷酸填充构成,转换与颠换比率约为0.50,熵值接近3.51至3.58,与真实生物水平基因转移的突变模式存在显著差异。数据集平均突变率约为23%,平均编辑距离约89.5个核苷酸,且保留了原始序列的多样性来源。尽管数据质量有限,但其结构完整,为历史研究与可重复性提供了基础。
使用方法
在应用层面,该数据集主要用于历史参考与模型训练的可重复性验证。用户可通过加载提供的八个JSONL文件,访问每条记录的亲本与子代序列及其元数据。鉴于其合成突变与真实生物学模式不符,建议谨慎用于实际突变识别任务,而更适宜作为方法学比较或后续合成数据生成的基准对照。相关真实突变数据集与改进版本已可供进一步探索。
背景与挑战
背景概述
在基因组学与生物信息学领域,水平基因转移(HGT)作为驱动微生物进化与适应性的关键机制,其突变模式的精准识别与建模一直是研究的前沿课题。hgt-bootstrap-v1-synthetic数据集由研究团队Nhoodie等人构建,旨在通过合成数据生成方法探索DNA序列突变模拟的可行性。该数据集采用ICI-DC(交错密码子插入-双重共识)技术,结合SAD coeff1.5与HyenaDNA-tiny-1k模型,从八个分类学领域的1014条独特源序列中生成8112对合成突变序列,为HGT相关计算模型的训练与验证提供了初步的数据基础。尽管其生成过程体现了跨模型协作与合成数据扩增的创新尝试,但数据集本身主要服务于方法学验证与历史可重复性目的。
当前挑战
该数据集所针对的领域挑战在于如何构建能够准确反映生物水平基因转移突变规律的合成DNA序列数据,以支持突变识别与进化分析模型的训练。然而,数据生成过程中模型欠拟合导致突变模式偏离真实生物学特征,具体表现为核苷酸替换的Ti/Tv比率约为0.50、熵值接近3.51/3.58,与真实HGT突变模式(Ti/Tv约0.77)存在显著差异,这削弱了数据在突变判别任务上的有效性。此外,合成数据的构建依赖于特定模型检查点与共识机制,其生成质量受限于模型性能与算法参数的选择,使得数据在生物学合理性与泛化能力方面面临根本性局限。
常用场景
经典使用场景
在基因组学与生物信息学领域,合成数据常被用于模型训练与基准测试的辅助工具。HGT-bootstrap-v1-synthetic数据集通过ICI-DC方法生成了8,112对合成突变序列,这些序列模拟了DNA序列的变异模式,尽管其突变模式与真实生物数据存在差异。该数据集最经典的使用场景是作为历史参照或方法验证的基准,研究人员可将其用于评估序列生成模型的鲁棒性,或在对比实验中分析合成数据与真实数据在模型训练中的表现差异,从而揭示数据质量对算法性能的影响。
衍生相关工作
该数据集衍生了一系列相关研究,尤其是后续的改进版本如HGT-bootstrap-v2-synthetic,后者扩展了数据规模至256K对,旨在提升合成数据的质量与实用性。同时,与之配套的真实突变数据集HGT-real-mutation-pairs提供了对比基准,促进了合成与真实数据在水平基因转移研究中的协同分析。这些工作共同推动了基于深度学习的DNA序列建模领域的发展,为更精准的生物信息学工具奠定了基础。
数据集最近研究
最新研究方向
在基因组学与合成数据生成领域,hgt-bootstrap-v1-synthetic数据集作为历史性实验产物,其研究焦点已转向合成数据质量的评估与改进。该数据集通过ICI-DC方法生成,揭示了模型欠拟合导致的核苷酸随机填充问题,其Ti/Tv比率与生物学真实水平存在显著偏差,这促使学界深入探讨合成数据在模拟水平基因转移突变模式时的局限性。前沿研究围绕合成数据的真实性验证展开,结合后续版本如v2的优化,旨在提升模型对突变模式的判别能力,从而推动合成数据在生物信息学中的可靠应用,为基因突变分析与模型训练提供关键参考。
以上内容由遇见数据集搜集并总结生成


