edomaru/jma-gsi-disaster-action-corpus
收藏Hugging Face2026-05-01 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/edomaru/jma-gsi-disaster-action-corpus
下载链接
链接失效反馈官方服务:
资源简介:
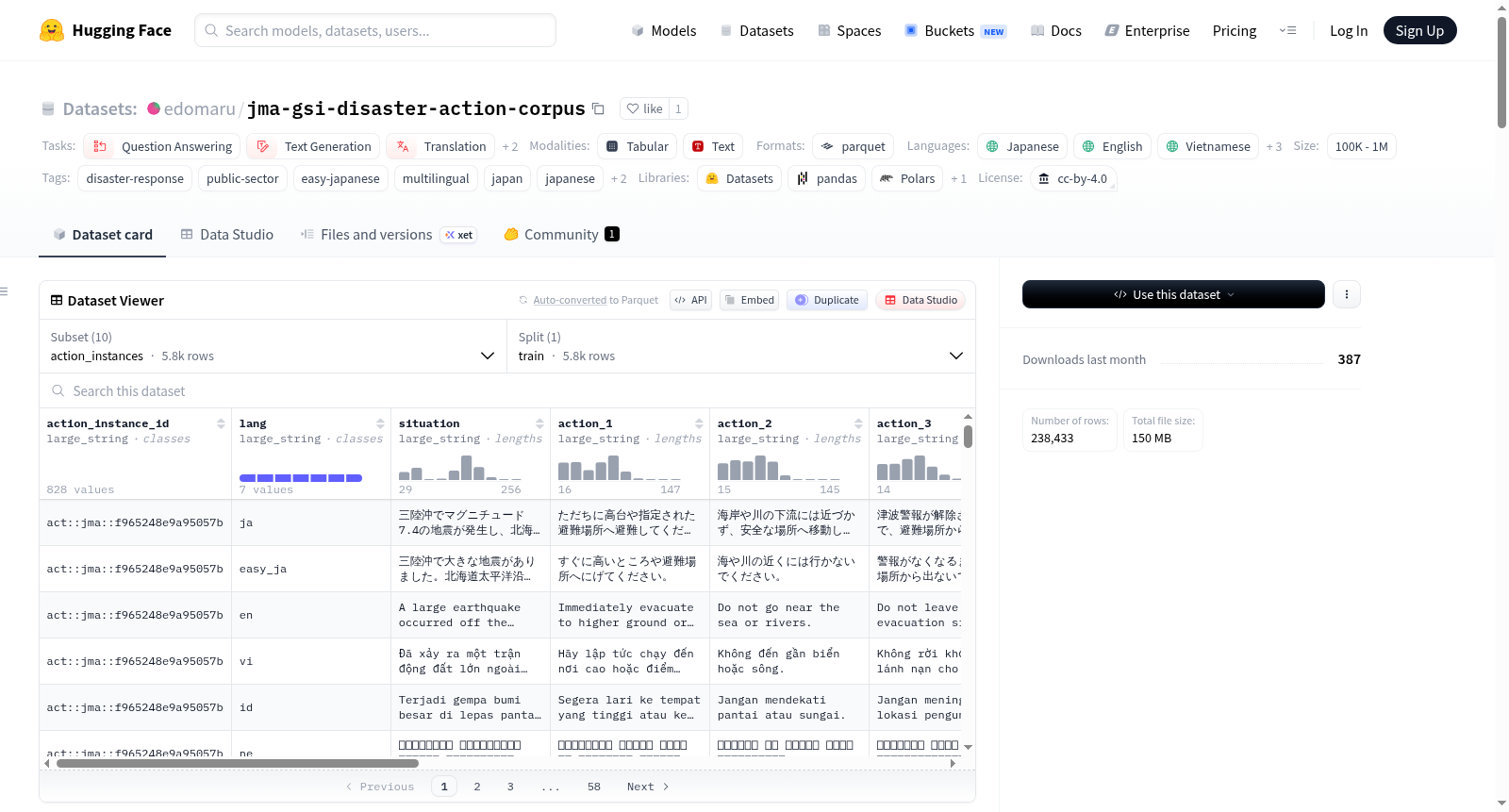
JMA-GSI灾害行动语料库是一个基于日本政府开放数据(JMA警报XML、JMA多语言术语表、JMA预测区域GIS和GSI指定避难所)构建的多语言灾害响应数据集。该数据集将结构化的灾害警报转化为简易日语和多语言(日语/简易日语/英语/越南语/印度尼西亚语/尼泊尔语/缅甸语)行动指南,并与灾害兼容的避难所相关联,具有完整的来源可追溯性。数据集涵盖多种自然语言处理任务,如问答、文本生成、翻译、摘要和文本检索,并提供了详细的数据集构建流程、质量检查报告以及预期用途。同时,README也指出了数据集的局限性,如非实时操作指导系统、快照数据、合成多语言内容等。
The JMA-GSI Disaster Action Corpus is a grounded, multilingual disaster-response dataset built from official Japanese government open data (JMA alert XML + JMA multilingual glossary + JMA forecast-area GIS + GSI designated evacuation shelters). Structured hazard alerts are transformed into easy-Japanese and multilingual (ja / easy-ja / en / vi / id / ne / my) action guidance, linked to hazard-compatible evacuation shelters, with full source traceability. The dataset supports various NLP tasks such as question-answering, text-generation, translation, summarization, and text-retrieval. It includes detailed information on the datasets reproduction pipeline, quality checks, intended use cases, and limitations, such as not being an operational evacuation instruction system, snapshot data, and synthetic multilingual content.
提供机构:
edomaru
搜集汇总
数据集介绍
构建方式
该数据集基于日本官方发布的气象厅警报XML数据、多语种术语表、气象厅预报区域GIS数据以及国土地理院指定的避难所开放数据,通过系统化的数据流水线构建而成。原始警报数据经过规范化处理后,被转化为简易日语及多语言(日语、简易日语、英语、越南语、印度尼西亚语、尼泊尔语、缅甸语)的行动指引,并与具备灾害兼容性的避难所信息进行关联。整个构建流程涵盖数据采集、字段标准化、实例生成、多语种内容生成、质量校验等多个环节,并采用大型语言模型辅助生成多语种问答对、时序变更摘要及安全偏好数据,最终形成包含十个核心配置文件的综合性数据集。
特点
该数据集具备鲜明的多模态与多语种特性,涵盖规范化警报、区域参考、避难所参考、术语表、行动实例、多语种问答、检索语料、警报差异、安全偏好对及避难所排序共十大子集,总计超过22万条记录。其显著特点在于对灾害响应场景的深度覆盖:每条行动实例均关联七种语言的情境描述与三项具体行动建议,并附有至多五个经排序的避难所候选。此外,数据集通过语言专家模型对非英语语种进行独立评测,确保了多语种内容的专业性与事实准确性,同时在避难所推荐中明确标注了路线免责声明,体现了严谨的数据治理态度。
使用方法
用户可通过Hugging Face Datasets库直接加载各子集配置,例如使用'alerts_normalized'获取规范化警报数据,或使用'qa_multilingual'获取多语种问答对。该数据集适用于构建面向公众安全信息的检索增强生成系统、简易日语改写基准测试、灾害响应指令微调以及偏好微调等场景。其中,adaption_enhanced文件夹提供了经由Adaptive Data平台增强的高质量版本,包含优化后的提示词与回复,可作为监督式微调的目标数据。建议开发者在实际应用中结合官方实时信息进行验证,并将数据集定位为研究与原型开发的辅助资源而非操作性的疏散指令系统。
背景与挑战
背景概述
在灾害应急响应领域,多语言、可溯源的行动指导语料库的匮乏长期制约着智能系统的部署。JMA-GSI Disaster Action Corpus由konbu17于2026年基于日本气象厅(JMA)和国土地理院(GSI)的官方开放数据构建,旨在弥合结构化预警信息与多语种公众理解之间的鸿沟。该数据集将地震、海啸等警报XML与多语种术语表、避难所地理信息深度融合,生成覆盖日语、简易日语、英语、越南语等七种语言的行动指引,为灾害响应中的问答、检索增强生成、指令微调等任务提供了首个大规模、地面化的多语言基准。其发布推动了公共安全领域自然语言处理研究的实用化进程,尤其为非日语母语者及语言弱势群体在紧急情况下的信息获取提供了关键支撑。
当前挑战
数据集面临的首要挑战是领域问题本身的复杂性:灾害警报具有高度时效性与上下文敏感性,错误或模糊的指令可能引发严重后果,要求模型在危机环境下实现精准理解与生成,而非简单翻译。构建过程中,团队遭遇了多语言一致性的严峻考验——简陋的地理数据处理需将日本上千个预警区域与近20万避难所设施准确关联,而机器生成的七语种翻译在自然度与事实准确性间难以平衡,尼泊尔语版最终仍需人工复审。此外,警报与避难所数据的静态快照性质使其难以反映动态变化,且缺乏路径规划能力,这些局限要求使用者在部署时务必结合实时官方渠道验证信息。
常用场景
经典使用场景
JMA-GSI Disaster Action Corpus 在防灾减灾研究领域确立了标杆性的多模态应用范式。该数据集最经典的场景是构建面向灾害响应的检索增强生成(RAG)系统,将日本气象厅(JMA)的结构化警报信息与国土地理院(GSI)的避难所数据有机融合,使模型能够根据实时灾害类型、区域范围和语言偏好,精准检索并生成包含具体避难行动指引的多语言应答。研究者可将警报归一化数据、避难所参考数据和多语言问答对协同使用,搭建端到端的灾害信息服务原型,通过'警报-区域-避难所'的闭环链路,实现对台风、海啸和地震等典型灾害情境的智能化响应。
解决学术问题
该数据集系统性地解决了灾害信息处理领域长期存在的三大核心学术困境。其一,打破了灾害响应数据在语言和地域上的隔离壁垒,通过覆盖日语、简易日语、英语、越南语、印尼语、尼泊尔语和缅甸语七种语言,为跨语言灾害信息检索与生成研究提供了扎实的平行语料基础。其二,弥合了结构化官方数据与非结构化行动指引之间的语义鸿沟,通过构建'警报-行动-避难所'的标准化映射体系,为指令微调中的行动链推理任务提供了高保真的训练基准。其三,开辟了灾害场景下时间敏感信息的时序摘要研究道路,利用警报差异数据集为连续事件的状态演化建模提供了独特锚点。
衍生相关工作
该数据集已催生出多项具有方法论启发意义的衍生工作。在数据增强层面,适配实验室(Adaption Labs)提出的自适应数据处理流程为行业树立了新标杆,通过七步引导式UI对原始生成内容进行质量诊断和改写优化,使数据集整体评分从6.0分跃升至9.1分,其偏好对构建方法论可直接迁移至其他低资源领域的指令微调任务。在质量评估维度,由五名语言专家型大模型组成的交叉审校体系为多语言语料质量保证提供了可复现的评测框架。在方法学创新上,基于灾害时空特征的避难所排序算法和面向安全对齐的偏好数据生成范式,为人机交互中的负责任人工智能研究提供了可量化的实验基底。
以上内容由遇见数据集搜集并总结生成


