DSGram-Eval, DSGram-LLMs
收藏arXiv2024-12-17 更新2024-12-19 收录
下载链接:
https://huggingface.co/datasets/jxtse/DSGram
下载链接
链接失效反馈官方服务:
资源简介:
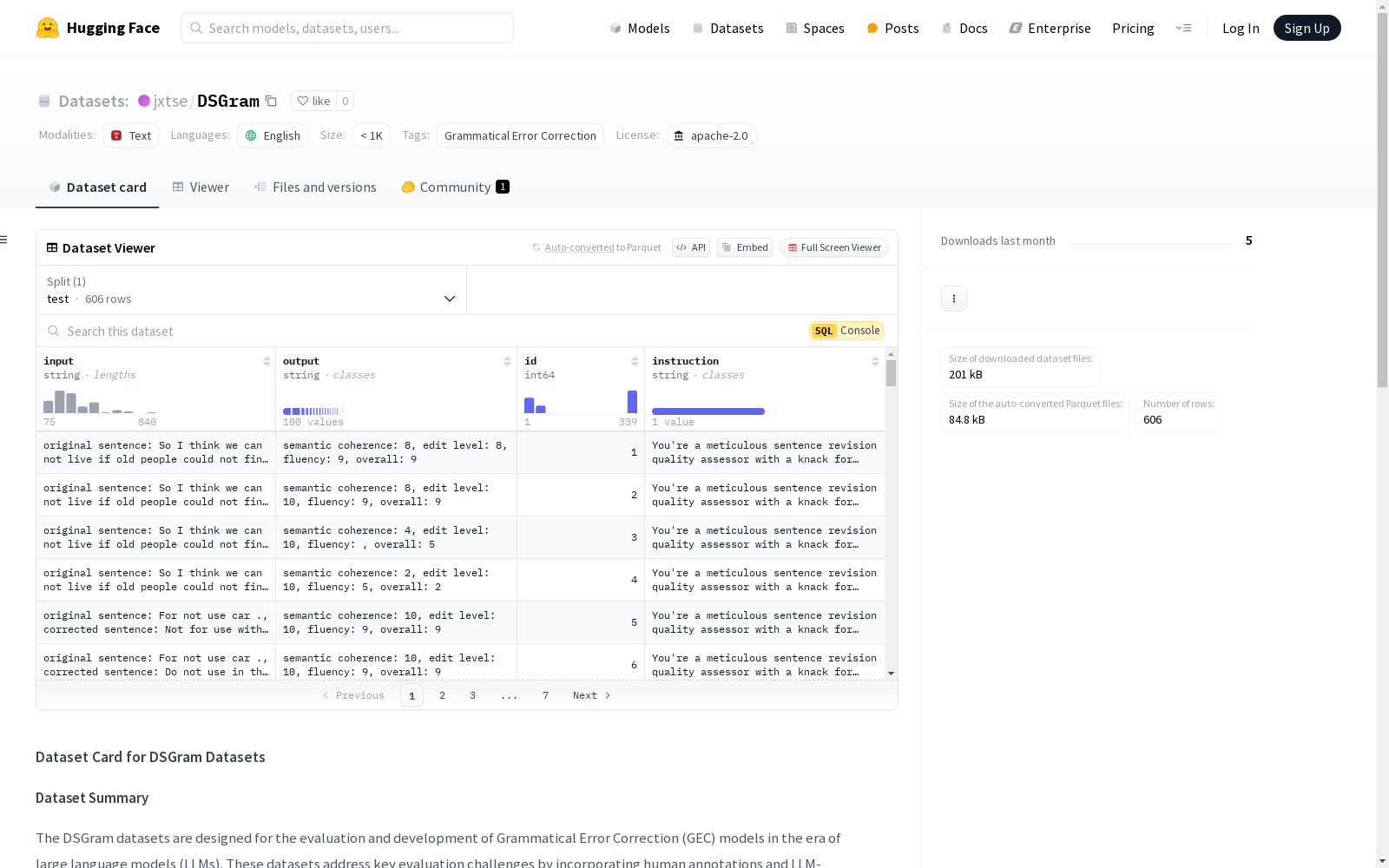
DSGram数据集由北京大学王选计算机研究所创建,旨在用于语法错误纠正(GEC)模型的评估。该数据集包含DSGram-Eval和DSGram-LLMs两个子集,分别通过人工评分和LLM模拟评分生成,用于验证算法和微调模型。数据集内容包括来自CoNLL-2014和BEA-2019测试集的句子,涵盖语义一致性、编辑级别和流畅性等多个评估维度。创建过程结合了人工标注和LLM模拟,确保数据集的多样性和准确性。DSGram数据集主要应用于GEC模型的评估和优化,旨在解决传统评估方法在大型语言模型时代中的不足。
The DSGram Dataset was created by the Wangxuan Institute of Computer Technology at Peking University, aiming for the evaluation of Grammatical Error Correction (GEC) models. It comprises two subsets: DSGram-Eval and DSGram-LLMs, which are generated via human scoring and LLM-based simulated scoring respectively, and are used to validate algorithms and fine-tuned models. The dataset includes sentences sourced from the CoNLL-2014 and BEA-2019 test sets, covering multiple evaluation dimensions such as semantic consistency, edit level, and fluency. Its creation integrates manual annotation and LLM-based simulation to ensure the dataset's diversity and accuracy. The DSGram Dataset is mainly applied to the evaluation and optimization of GEC models, with the purpose of addressing the shortcomings of traditional evaluation methods in the era of large language models.
提供机构:
北京大学王选计算机研究所
创建时间:
2024-12-17
原始信息汇总
DSGram 数据集
数据集概述
DSGram 数据集是为评估和开发语法错误纠正(GEC)模型而设计的,特别是在大规模语言模型(LLMs)时代。该数据集通过结合人工标注和LLM生成的评分,解决了关键的评估挑战。数据集包含两个子集:
- DSGram-LLMs:一个模拟数据集,包含由GPT-4标注的句子对,用于GEC模型的微调和成本效益评估。
- DSGram-Eval:一个手动标注的数据集,提供高质量的人工评分示例,用于基准测试DSGram框架。
数据集支持基于以下三个子指标的修正评估:
- 语义一致性:保留原始含义。
- 编辑级别:修改的适当性。
- 流畅性:语法正确性和自然流畅性。
数据集结构
DSGram-LLMs
- 输入:来自CoNLL-2014和BEA-2019测试集的原始和修正句子。
- 标注:由GPT-4使用提示工程技术(Chain-of-Thought, few-shot prompting)生成的评分。
- 大小:约2,500条数据。
DSGram-Eval
- 输入:来自CoNLL-2014的句子。
- 标注:基于三个子指标的人工评分句子对,多个标注者以确保一致性。
- 大小:约200条数据。
数据集用途
预期用途
- 微调开源LLMs以进行GEC评估。
- 使用稳健且上下文敏感的指标基准测试GEC模型。
- 研究文本修正任务的评估框架。
引用
如果使用这些数据集,请引用相关论文。
搜集汇总
数据集介绍
构建方式
DSGram-Eval和DSGram-LLMs数据集的构建基于人类评分和大规模语言模型(LLMs)生成的模拟数据。DSGram-Eval数据集通过招募人类标注者对CoNLL-2014和BEA-2019测试集中的句子进行详细评分,涵盖语义一致性、编辑级别和流畅性等维度。DSGram-LLMs数据集则利用GPT-4生成模拟人类评分的子指标分数,进一步用于模型微调。这两个数据集共同为验证DSGram评估框架的有效性提供了坚实的基础。
特点
DSGram数据集的显著特点在于其综合性和动态性。DSGram-Eval通过人类标注确保了评分的准确性和可靠性,而DSGram-LLMs则通过LLMs生成的模拟数据扩展了数据集的规模和多样性。此外,DSGram数据集引入了新的子指标,如编辑级别,以更好地评估LLMs在语法错误纠正中的过度编辑问题,从而提升了评估的全面性和针对性。
使用方法
DSGram数据集主要用于验证和微调语法错误纠正(GEC)模型的评估框架。研究者可以通过DSGram-Eval数据集进行人类评分的对比实验,以评估不同GEC模型的性能。DSGram-LLMs数据集则可用于微调开源LLMs,如LLaMA,以提高其在GEC任务中的评分一致性和准确性。通过结合这两个数据集,研究者能够更全面地评估和优化GEC模型的表现。
背景与挑战
背景概述
随着大规模语言模型(LLMs)在语法错误纠正(GEC)领域的广泛应用,传统的基于参考的评估方法逐渐暴露出其局限性,尤其是在LLMs生成的修正与黄金参考存在显著差异时。为应对这一挑战,北京大学和北京交通大学的研究团队提出了DSGram评估框架,该框架通过动态加权机制整合语义一致性、编辑级别和流畅性三个子指标,并利用层次分析法(AHP)与LLMs相结合,以确定各评估标准的相对重要性。DSGram不仅引入了新的子指标以优化现有评估方法,还通过人工标注和LLMs模拟生成的句子构建了DSGram-Eval和DSGram-LLMs两个数据集,旨在验证其算法的有效性并优化更具成本效益的模型。
当前挑战
DSGram数据集的构建与应用面临多重挑战。首先,传统的基于参考的评估指标如BLEU和ERRANT在处理LLMs生成的过度修正时表现不佳,无法准确反映模型的实际性能。其次,构建过程中,如何确保人工标注与LLMs模拟生成的句子在语义一致性、编辑级别和流畅性上的准确性,是一个复杂且耗时的任务。此外,动态加权机制的引入虽然提升了评估的灵活性,但也增加了计算复杂度,如何在高效率与高准确性之间取得平衡,是DSGram面临的重要挑战。最后,随着LLMs的不断发展,如何持续更新和优化评估框架,以适应新的模型和应用场景,也是DSGram未来需要解决的问题。
常用场景
经典使用场景
DSGram-Eval和DSGram-LLMs数据集的经典使用场景主要集中在语法错误纠正(GEC)模型的评估上。这些数据集通过结合语义一致性、编辑级别和流畅性等多个子指标,提供了对GEC模型性能的全面评估。通过动态加权机制,DSGram框架能够根据不同的评估场景调整各子指标的权重,从而更准确地反映模型在不同文本类型中的表现。
解决学术问题
DSGram数据集解决了传统语法错误纠正评估中存在的几个关键问题。首先,它克服了传统基于参考的评估方法在处理大语言模型(LLM)输出时的局限性,这些模型可能产生与黄金参考不一致的修正。其次,DSGram通过引入动态加权机制,解决了现有评估指标与人类判断不一致的问题,提升了评估的准确性和可靠性。
衍生相关工作
DSGram数据集的提出催生了一系列相关研究工作。首先,基于DSGram的评估框架,研究者们进一步探索了如何利用大语言模型(如GPT-4)生成更准确的评估分数,并验证了这些分数与人类判断的高度一致性。其次,DSGram的动态加权机制启发了其他领域的评估方法,特别是在需要根据不同场景调整评估标准的任务中。此外,DSGram数据集的构建方法也为其他自然语言处理任务的数据集设计提供了参考。
以上内容由遇见数据集搜集并总结生成


